利用pykrige和matplotlib进行地质变化的空间可视化
通过测井测量探索空间地质变化

在处理地质和岩石物理数据时,我们通常希望了解该数据在我们的领域或地区如何变化。我们可以通过对实际测量值进行网格化,并推断出在尚未使用钻孔勘探的其他区域中这些值可能是什么,从而进行这种推断。
一种特定的执行此推断的方法是kriging,一种以南非采矿工程师Danie G. Krige命名的地统计过程。 kriging背后的思想在于其估计技术:它使用观察数据之间的空间相关性来预测未测量位置上的值。
通过评估变量随距离变化的方式,该方法建立了一个可用于预测区域内的值的统计关系,将分散的数据点转换为连贯的空间地图。
在本教程中,我们将介绍一个名为pykrige 的Python库。该库已经为2D和3D kriging计算进行了设计,并且在使用测井数据时易于使用。
导入库和数据
首先,我们需要导入我们需要的库。对于本文,我们需要以下库:
- pandas — 用于读取我们的数据,该数据以
csv格式存储 - matplotlib 用于创建可视化效果
- pykrige 用于执行kriging
- numpy 用于一些数值计算
import pandas as pdimport matplotlib.pyplot as pltfrom pykrige import OrdinaryKrigingimport numpy as np导入库后,我们现在可以导入我们的数据。
在本教程中,我们将使用从Xeek和Force 2020机器学习竞赛中导出的数据集来预测岩性与测井测量值相关的数据。该数据集的详细信息可以在本文底部找到。
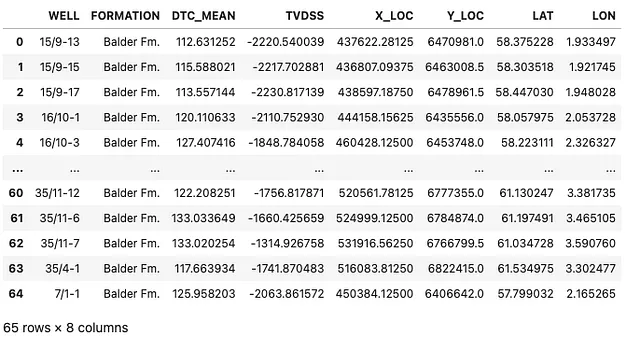
该竞赛数据集的子集包含65个井位置,其平均声波纵向慢度测量值为Balder层。
要读取我们的数据,我们可以使用pandas read_csv()函数,并传递数据文件的位置。在这个例子中,我们使用相对于我们的Jupyter Notebook的路径,但是如果我们的文件位于其他地方,我们也可以使用绝对路径。
df = pd.read_csv('Data/Xeek Force 2020/Xeek_2020_Balder_DTC_AVG.csv')df当我们查看数据框时,我们会看到我们有65口井,其中包含了Balder层的顶部位置(X_LOC和Y_LOC用于网格坐标,LAT和LON用于纬度和经度)。我们还有遇到该层的真实垂直深度(TVDSS)和声波纵向慢度(DTC)的平均值。
可视化井的空间位置
现在,我们已经成功将数据加载到数据框中,我们可以通过可视化来理解井的位置。为此,我们将使用matplotlib的散点图,并传递经度和纬度列。
plt.scatter(df['Longitude'], df['Latitude'], c=df['DTC'])当我们运行上述代码时,我们会得到以下绘图结果。
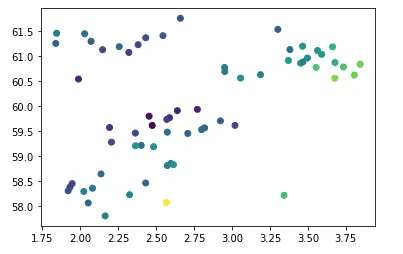
我们可以看到上面的图表非常基础,没有颜色条或轴标签。
让我们通过添加这些特性稍微修改一下绘图结果。
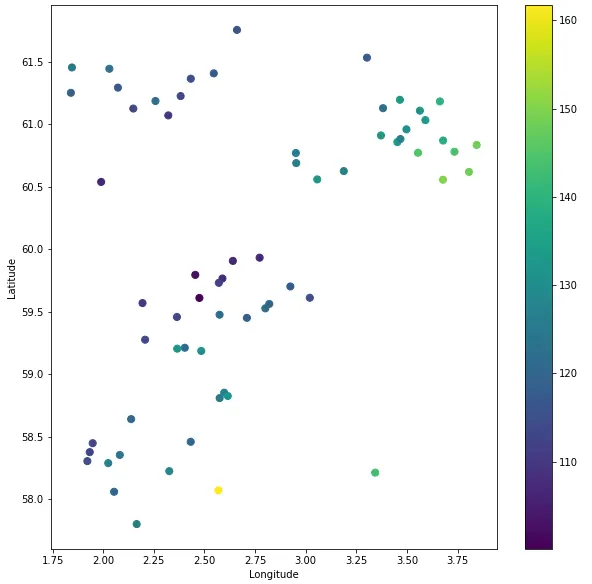
cm = plt.cm.get_cmap('viridis')plt.figure(figsize=(10,10))scatter = plt.scatter(df['LON'], df['LAT'], c=df['DTC_MEAN'], cmap=cm, s=50)plt.colorbar(scatter)plt.xlabel('Longitude')plt.ylabel('Latitude')plt.show()当我们运行上述代码时,我们得到以下结果,它告诉我们更多关于我们的数据。我们可以使用颜色条来估计我们的点值。
应用 Kriging
为了更好地理解我们的数据点以及 Balder Formation 区域内 DTC 测量值的变化,我们可以使用 kriging 和我们的数据点来填补测量值之间的空隙。
为此,我们需要从 pykrige 库创建一个 OrdinaryKriging 对象。
我们需要将 x 和 y 的位置数据以及我们要映射到 z 参数的数据传递给该对象。
我们还需要选择要使用的变异函数模型。在这种情况下,我们将使用指数模型。有关模型类型的更多详细信息可以在文档中找到。
由于我们使用纬度和经度作为 x 和 y 坐标,因此我们可以将 coordinates_type 参数更改为 geographic
OK = OrdinaryKriging(x=df['LON'], y=df['LAT'], z=df['DTC_MEAN'], variogram_model='exponential', verbose=True, enable_plotting=True, coordinates_type='geographic')当我们运行上述代码时,我们会得到以下模型摘要和半变异函数。
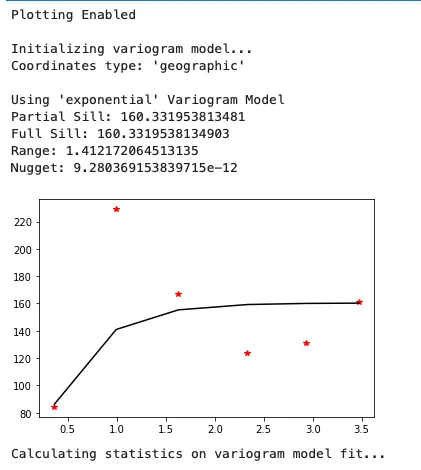
以下是返回的参数的简短概述:
- Nugget:坚果是变异函数的 y 截距,表示在零距离处的方差,通常由于测量误差或非常小的尺度变化而引起。
- Full Sill:Sill 是变异函数达到的最大方差并开始趋于平稳的点,当点之间很远时会发生这种情况。
- Range:Range 是变异函数达到 sill 的距离,这意味着超出这个距离,点的进一步分离不会增加方差。
- Partial Sill:Partial Sill 是 sill 和 nugget 的差异,表示空间结构化数据中的方差量。
这可以让我们根据生成的线和点的形状了解我们的模型对数据的适用性。
显示 Kriging 结果
为了开始展示我们的数据,我们需要创建一个数据网格。
为此,我们首先创建纬度和经度的数组,以在我们定义的坐标之间进行。在这种情况下,我们希望图表从57.5度N延伸到62度N,从1.5度E延伸到4.5度E。
使用np.arange将允许我们以常规间距创建这些数组。
grid_lat = np.arange(57.5, 62, 0.01, dtype='float64')grid_long = np.arange(1.5, 4.5, 0.01,dtype='float64')现在我们有了X和Y坐标,我们可以创建我们的值网格。为此,我们调用OK.execute,并传入我们的纬度和经度数组。
zstar, ss = OK.execute('grid', grid_long, grid_lat)这将返回两个数组。我们的数据网格(zstar)和与其相关的不确定性(ss)
接下来,我们现在可以使用我们的数据数组并使用matplotlib的imshow绘制它。
import matplotlib.pyplot as pltfig, ax = plt.subplots(figsize=(10,10))image = ax.imshow(zstar, extent=(1.5, 4.5, 57.5, 62), origin='lower')ax.set_xlabel('经度', fontsize=14, fontweight='bold')ax.set_ylabel('纬度', fontsize=14, fontweight='bold')scatter = ax.scatter(x=df['LON'], y=df['LAT'], color='black')colorbar = fig.colorbar(image)colorbar.set_label('DTC (us/ft)', fontsize=14, fontweight='bold')plt.show()当我们运行此代码时,我们将得到以下地图,显示Balder Formation的声学压缩慢度变化在我们的65口井中。
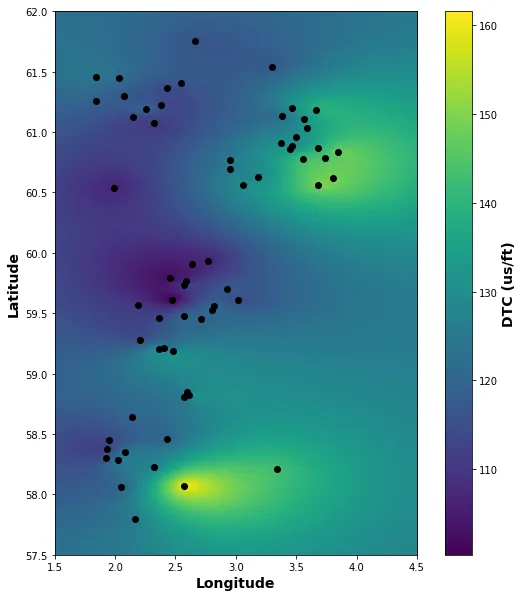
我们可以看到,在59到60度N左右,我们有更快的岩石,在东北部和西南部地区,我们有更慢的岩石。
要理解这一点,我们需要了解每个这些井的地层有多深。这将使我们能够确定差异是否与埋藏和压实或其他地质过程有关。
我们将在未来的文章中看到如何做到这一点。
可视化Kriging不确定性
查看此类数据时的关键问题之一是了解与kriging相关的不确定性。
我们可以通过重复使用相同的绘图代码来执行此操作,而不是传递zstar,我们可以将其替换为我们之前创建的ss变量。
fig, ax = plt.subplots(figsize=(10,10))image = ax.imshow(ss, extent=(1.5, 4.5, 57.5, 62), origin='lower')ax.set_xlabel('经度', fontsize=14, fontweight='bold')ax.set_ylabel('纬度', fontsize=14, fontweight='bold')scatter = ax.scatter(x=df['LON'], y=df['LAT'], color='black')colorbar = fig.colorbar(image)colorbar.set_label('DTC (us/ft)', fontsize=14, fontweight='bold')plt.show()通过以下绘图,我们能够看到我们具有高或低不确定性的区域。
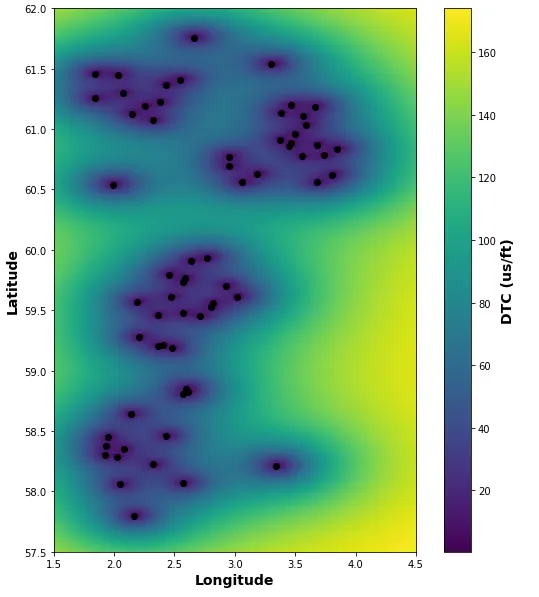
在井的覆盖范围较小的地区,我们的不确定性会更高,而在有多个井的地区,我们的不确定性会更低。
摘要
在本教程中,我们看到了如何对井测量值(DTC)进行平均值,并将其映射到整个区域。这使我们能够了解数据在地理区域上的趋势。
但是,在查看这些数据时,我们必须记住,我们看到的是一个2D表面,而不是我们在地下遇到的更复杂的3D结构。因此,测量的变化可能归因于深度的变化。
使用的数据集
本文中使用的数据集是 Xeek 和 FORCE 2020(Bormann et al.,2020)举办的机器学习竞赛的培训数据集的子集。它是根据挪威政府的 NOLD 2.0 许可证发布的,详细信息可以在这里找到:Norwegian Licence for Open Government Data (NLOD) 2.0。完整数据集可以在此处获取。
数据集的完整参考文献为:
Bormann, Peter, Aursand, Peder, Dilib, Fahad, Manral, Surrender, & Dischington, Peter. (2020). FORCE 2020 Well well log and lithofacies dataset for machine learning competition [Data set]. Zenodo. http://doi.org/10.5281/zenodo.4351156
感谢您的阅读。在离开之前,您应该订阅我的内容,并将我的文章发送到您的收件箱中。 您可以在此处执行此操作!
其次,您可以通过注册会员来获得完整的小猪AI体验,并支持成千上万的其他作家和我。它只需您每月支付5美元,您就可以完全访问所有fantastic 小猪AI文章,并有机会通过写作赚钱。
如果您使用我的链接进行注册,您将直接支持我一部分费用,而不会增加您的费用。如果您这样做,非常感谢您的支持。






