2023年专业调参:10个令人困惑的XGBoost超参数及其调整方法
通过风格和可视化完成的XGBoost超参数调整

引言
今天,我将向你展示如何调整XGBoost的超参数,使其紧缩到无法bst,从而获得所有性能。
这不仅仅是一个超参数清单。我将详细解释每个超参数,功能,接受的值范围,最佳实践以及如何使用Optuna进行超参数调整。
让我们开始吧!
我们一直想要的…
一个愚蠢的欠拟合XGBoost模型几乎是闻所未闻的。即使使用默认参数值,在许多表格任务上表现得相当不错。然而,它最大的问题在于过拟合。
为了解决这个问题,大多数XGBoost超参数被放置在那里,以驯服它,使其不会吞噬训练集并在测试期间呕出骨头。
因此,通过超参数调整,我们的目标是在复杂模型与被驯服的简单模型之间取得最佳平衡,从而对看不见的数据进行良好的泛化。
以下参数对于控制过拟合至关重要:
etanum_boost_roundmax_depthsubsamplecolsample_bytreegammamin_child_weightlambdaalpha
除此之外,我们还将探讨其他一些参数的调整技巧。
Sklearn XGBoost与Native XGBoost
我真的很难在这两个之间选择,因为Sklearn是我最喜欢的库,而XGBoost是我最喜欢的库名(它完美地适配了 – 域名已被占用)。
然而,当我们考虑到客观事实时,原生的XGBoost训练API在灵活性和访问高级和微妙功能方面略有优势。
我同意Scikit-learn API与Scikit-learn生态系统(包括管道、交叉验证器和其他功能)无缝集成。但是,对于本文的目的,我们将专注于原生的XGBoost API。
然而,对于那些坚定支持Scikit-learn API的人,我也将提供专门为该接口提供的超参数别名。
调整的代码
在我两年的XGBoost经验中,我发现调整其超参数的代码并不像理解每个参数的理论和为它们选择适当的调整范围那样困难。
因此,在我解释每个超参数的作用和重要性之前,我将留下这个GitHub Gist链接,可以将其复制/粘贴到你自己的工作中。该代码将对任何XGBoost模型进行交叉验证和调整,并返回最佳参数。没有必要在这里分享代码,因为它在移动端上将变得非常难读。
对于那些希望了解代码和如何使用Optuna进行调整的人,我建议阅读我的这篇文章(非常客观的选择)。
为什么Kaggle上的人都痴迷于使用Optuna进行超参数调整?
编辑说明
towardsdatascience.com
在我最终开始解释参数之前,我还将留下两个表格,你可以参考一些你不必浪费时间记忆的细节。
第一个表格包含参数的Sklearn别名及其推荐的调整范围:

如果你想使用Optuna之外的调参器,你可以使用下面这个表格。
这个表格则是展示每一对参数之间的相互作用:
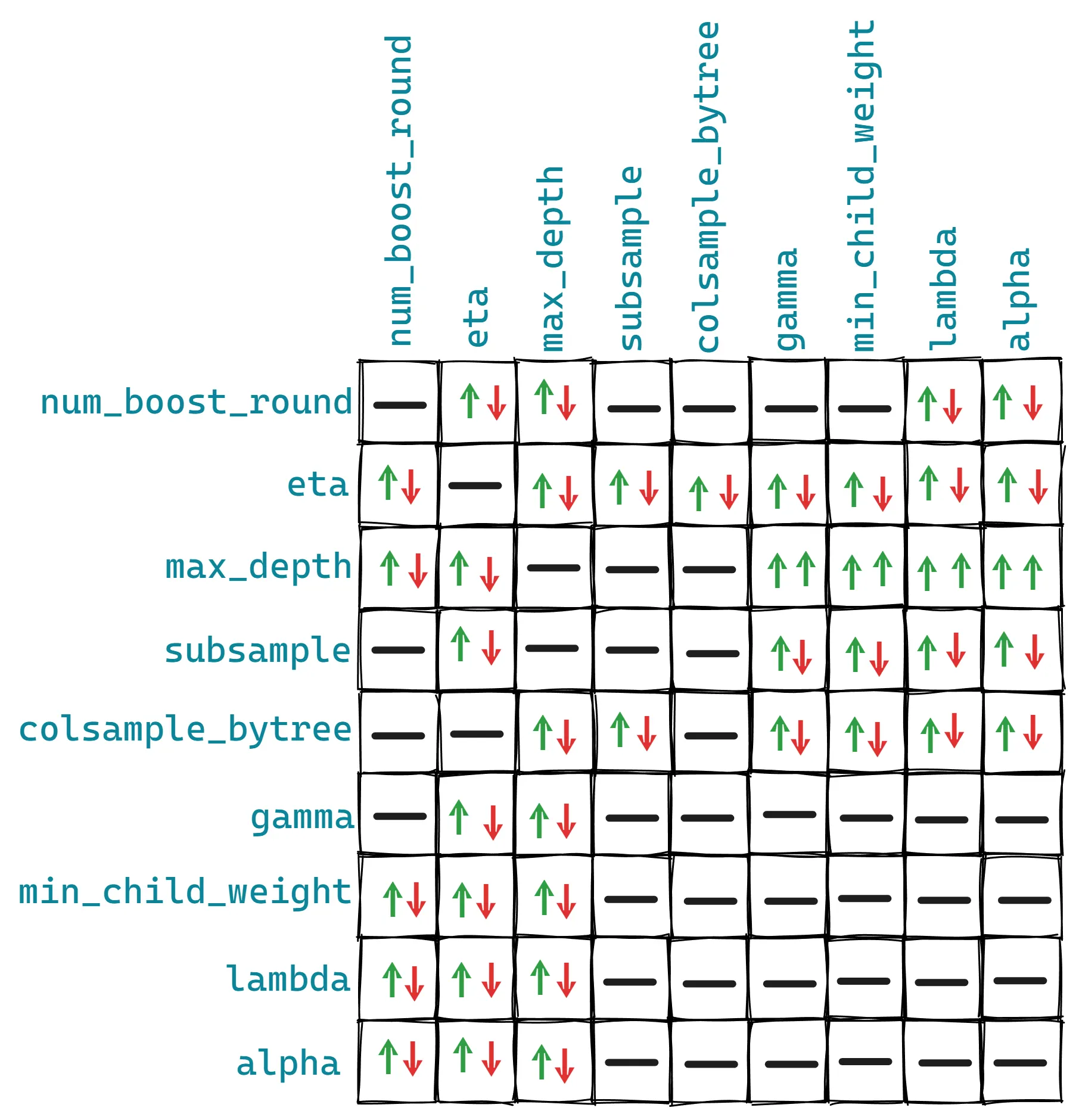
这些关系并不是固定的,其他参数也可能会影响它们。但是它们可以给出XGBoost中哪些参数会相互影响的大致情况。
10个参数的故事
0. objective – 无Sklearn别名
首先,在设置目标(XGBoost是基于树的集成模型)时,你必须确定你在这个领域的路径:
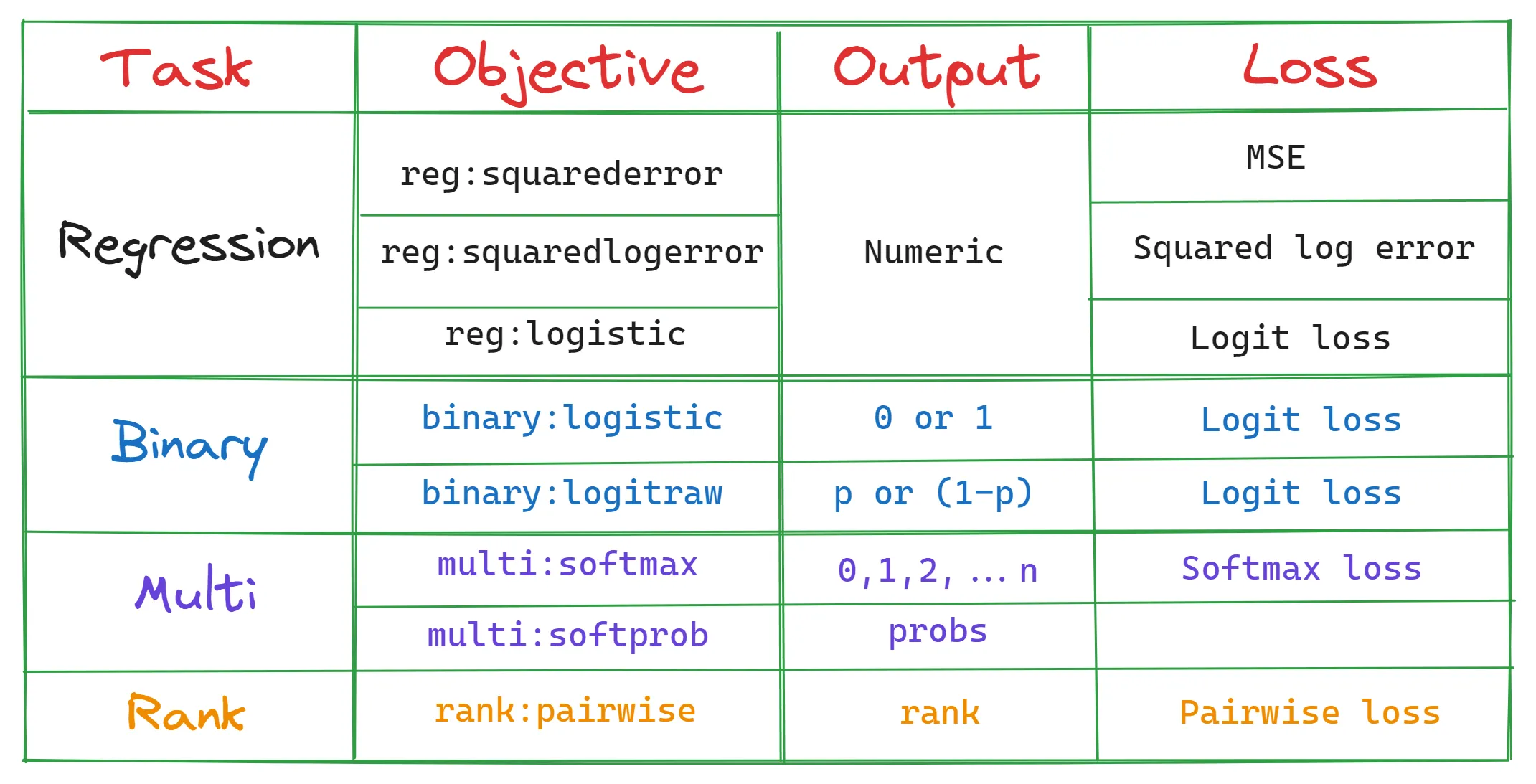
objective 直接影响决策树的类型和使用的损失函数。
1. num_boost_round – n_estimators
之后,你需要使用 num_boost_round 来确定训练过程中要种植的决策树(通常称为XGBoost的基学习者)的数量。默认值为100,但这对于今天的大数据集来说远远不够。
增加该参数将种植更多的树,但随着模型变得更加复杂,过拟合的可能性也会显著增加。
我从Kaggle学到的一个技巧是将 num_boost_round 设置为100,000,并利用 early stopping rounds。
在每个提升回合中,XGBoost会种植一棵决策树,以改善之前的决策树的总体得分。这就是为什么它被称为提升。这个过程会一直持续到达到 num_boost_round 回合,无论新回合是否比上一回合更好。
但是通过使用early stopping,我们可以在得分在过去5、10、50或任意一定回合内没有改善时停止训练和种植不必要的决策树。
借助这个技巧,我们可以找到完美的决策树数量,而无需调整 num_boost_round,并且可以节省时间和计算资源。以下是示例代码:
# Define the rest of the paramsparams = {...}# Build the train/validation setsdtrain_final = xgb.DMatrix(X_train, label=y_train)dvalid_final = xgb.DMatrix(X_valid, label=y_valid)bst_final = xgb.train( params, dtrain_final, num_boost_round=100000 # Set a high number evals=[(dvalid_final, "validation")], early_stopping_rounds=50, # Enable early stopping verbose_eval=False,)上面的代码将会使XGBoost使用100,000个决策树,但是由于使用了early stopping,它会在验证分数在过去50个回合中没有改善时停止。通常,所需的树的数量将少于5000-10000。
控制 num_boost_round 也是训练过程持续时间的最大因素之一,因为更多的树需要更多的资源。
2. eta – learning_rate
在每个回合中,所有现有的树都会对给定的输入返回一个预测。例如,在提升的第五轮中,五棵树可能会对样本N返回以下预测:
- 树1:0.57
- 树2:0.9
- 树3:4.25
- 树4:6.4
- 树5:2.1
为了返回最终的预测,需要将这些输出相加,但在此之前,XGBoost会使用一个名为 eta 或学习率的参数来缩放它们。缩放后,最终输出将是:
output = eta * (0.57 + 0.9 + 4.25 + 6.4 + 2.1)较大的学习率会给集成中每个树的贡献赋予更大的权重,但这可能会导致过拟合/不稳定,但训练时间更快。相反,较低的学习率会减弱每个树的贡献,使学习过程变慢但更稳健。
学习率参数的这种正则化效应对于复杂和嘈杂的数据集特别有用。
学习率与其他参数(如num_boost_round,max_depth,subsample和colsample_bytree)呈反比关系。较低的学习率需要更高的这些参数值,反之亦然。但是您不必担心这些参数之间的相互作用,因为超参数调整器将找到最佳组合。
3、4. subsample和colsample_bytree
子采样是一种引入更多随机性的装袋方法,因此有助于更好地抵抗过度拟合。
subsample=0.7表示集成中的每个决策树将随机选择70%的可用数据进行训练。值为1.0表示将使用所有行(不进行子采样)。
与subsample类似,还有colsample_bytree。顾名思义,colsample_bytree控制每个决策树将使用的特征(列)的比例。 colsample_bytree=0.8使每个树在每个树中使用可用特征(列)的随机80%。
调整这两个参数可以控制偏差和方差之间的权衡。使用较小的值会减少树之间的相关性并增加集合中的多样性,这可以帮助提高泛化能力并减少过拟合。
但是,这可能也会引入更多噪音并增加模型的偏差。相反,使用较大的值会增加树之间的相关性,减少多样性并可能导致过拟合。
5. max_depth
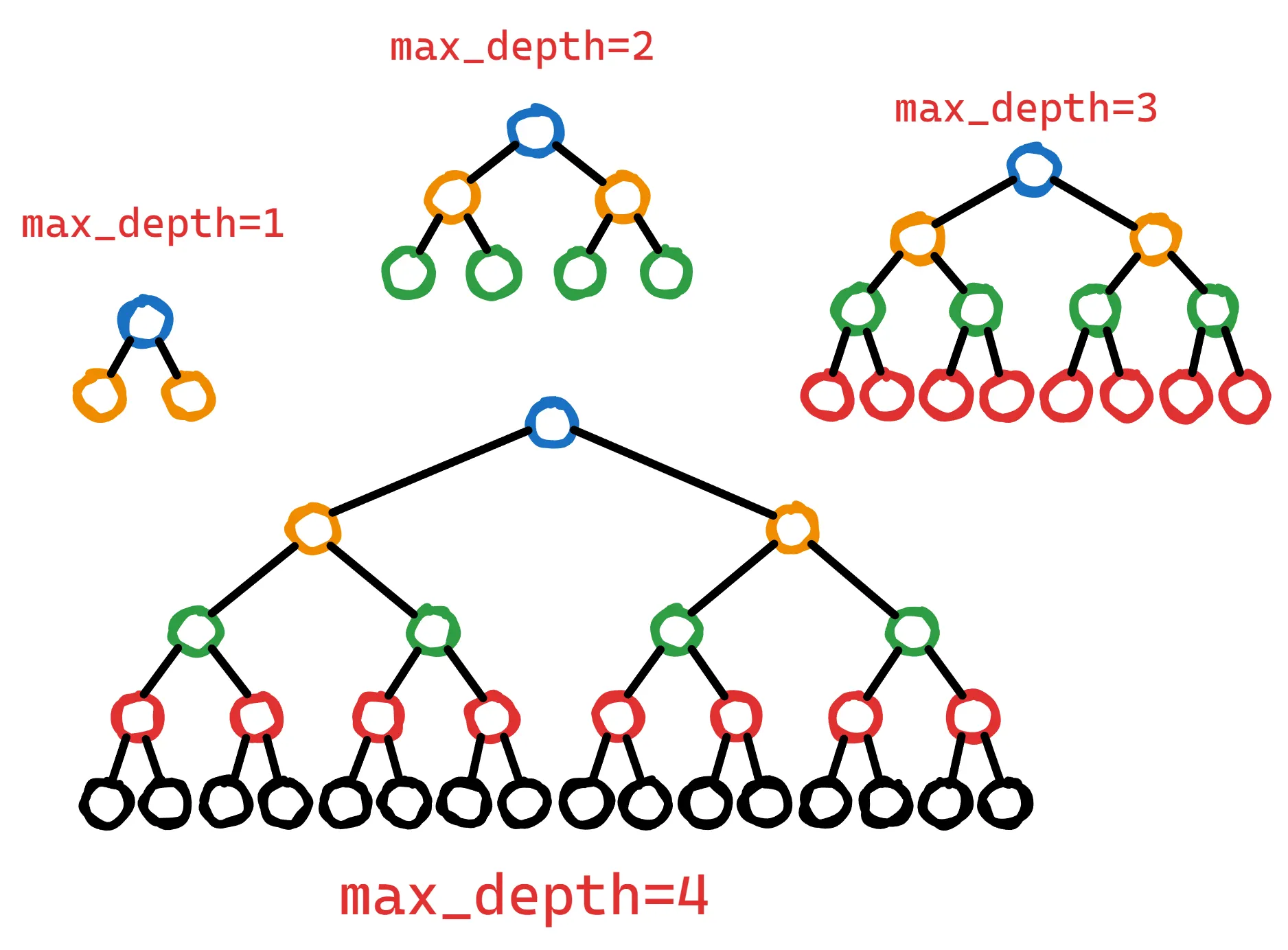
Max depth控制训练期间决策树可以达到的最大层数。
更深的树可以捕捉特征之间的更复杂的交互。但是,更深的树也有更高的过拟合风险,因为它们可以记忆训练数据中的噪声或无关模式。
为了控制这种复杂性,可以限制max_depth,从而得到更简单的更浅的决策树,可以捕获更一般的模式。
max_depth是复杂性和泛化之间的平衡器。
6、7. alpha和lambda
alpha(L1)和lambda(L2)是另外两个用于处理过拟合的正则化参数。
它们与其他正则化参数的区别在于,它们可以将不重要或不重要的特征的权重缩小到0(特别是alpha),从而得到具有更少特征的模型,因此更简单。
alpha和lambda的效果可能会受到其他参数(如max_depth,subsample和colsample_bytree)的影响。较高的alpha或lambda值可能需要调整其他参数以补偿增加的正则化。例如,更高的alpha值可能会从更大的subsample值中获益,以保持模型的多样性并防止欠拟合。
8. gamma
如果您阅读XGBoost文档,则会发现gamma是:
要使树叶节点进一步分区所需的最小损失减少。
我认为这句话只有写它的人才能理解。让我们来分解一下。
以下是一个两级的决策树:
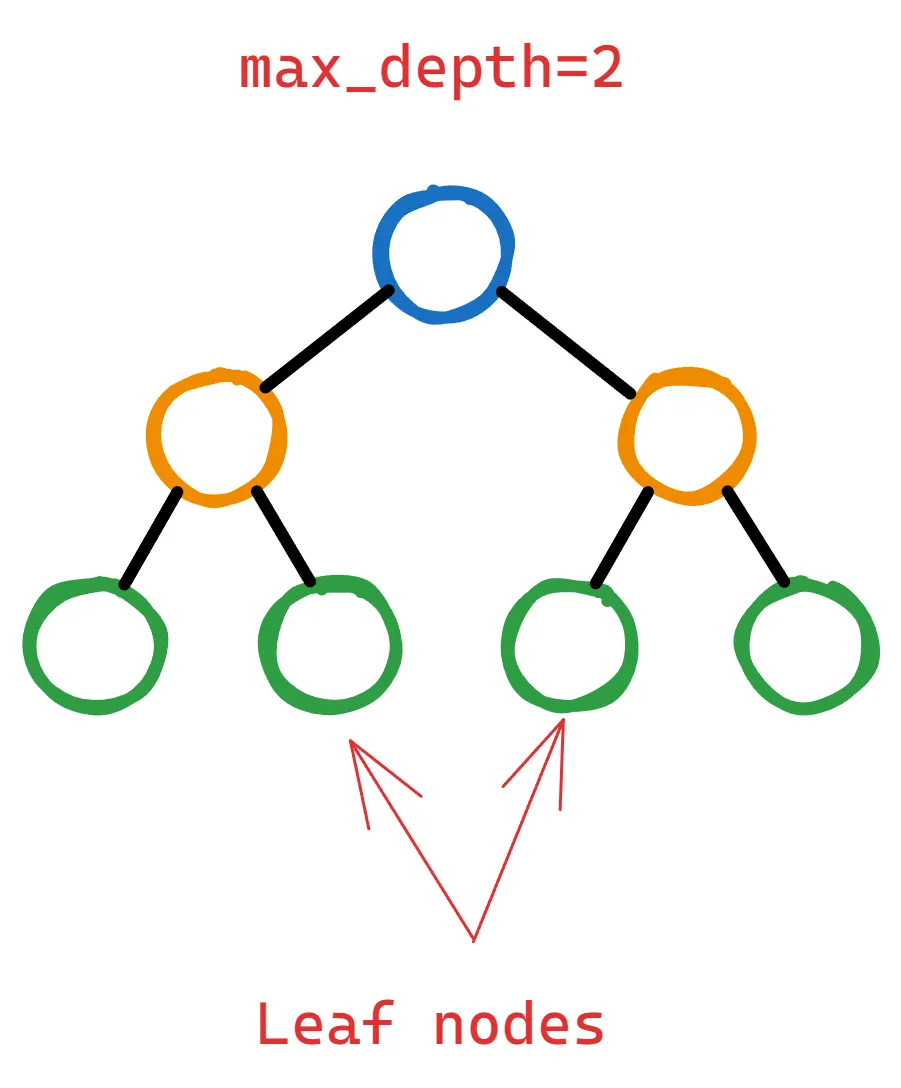
为了通过分裂叶节点来添加更多层次到树中,XGBoost 应该计算这个操作是否能显著地降低损失函数。
但你可能会问“显著地降低”有多少?这就是我们设置 gamma 的地方——它作为决定是否应该进一步分裂叶节点的阈值。
如果潜在分裂后损失函数的减少量(常称为增益)小于已选的 gamma,则不执行该分裂。这意味着叶节点保持不变,树将不会从那一点开始增长。
所以,调整 gamma 的目标是找到最佳分裂,以获得最大的损失函数降低,从而表示改进了模型性能。
9. min_child_weight
XGBoost 用一个单一的决策树和一个根节点开始初始训练过程。该节点最初包含所有的训练实例(行)。
然后,当 XGBoost 选择可能导致最大损失减小的潜在特征和分裂标准时,深层节点将包含越来越少的实例。
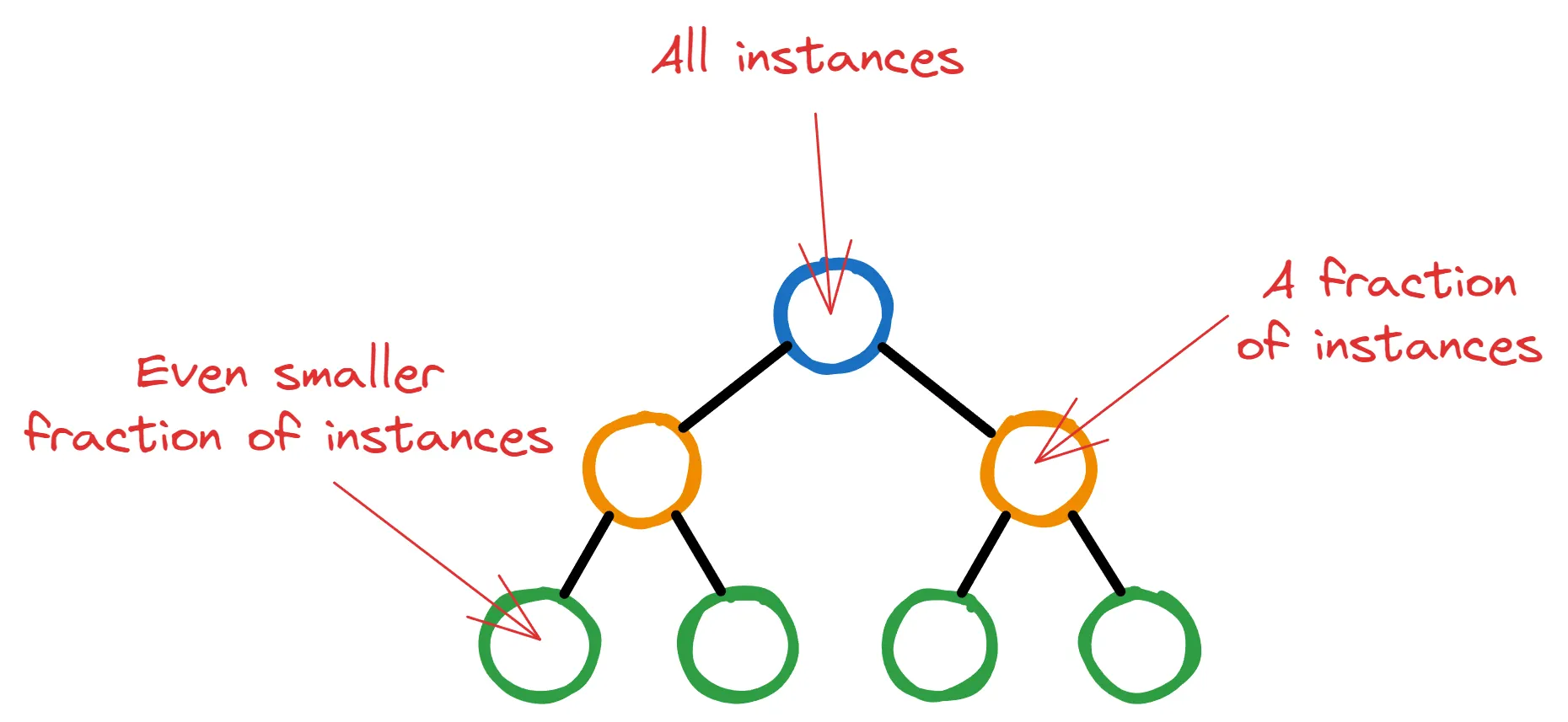
如果你让 XGBoost 随意发展,树可能会增长到最终节点中只有很少或不重要的实例。这种情况非常不希望,因为这正是过拟合的定义。
这就是为什么 XGBoost 允许用户在每个节点上拥有最小实例数的阈值,以继续分裂。为了确定这一点,节点中的所有实例都会被加权,然后找到权重之和。然后,如果这个最终权重小于 min_child_weight,则分裂停止,节点变成一个叶节点。
虽然这个解释是整个过程的极度简化,但它应该能够给你一个基本的概念。
结论
虽然我们已经涵盖了很多理论,但还有很多需要学习。我建议向 ChatGPT 提出以下两个提示:
1) 详细解释 XGBoost 参数 {parameter_name},以及如何明智地选择其值。2) 描述 {parameter_name} 如何适配到 XGBoost 的逐步树构建过程中。我想留下一个最后的注释,说一下在调整后应该使用交叉验证和一个原始的最终测试集来测试模型的性能。
您可以将数据分为 80/20,并使用 5-7 折交叉验证在 80% 上调整 XGBoost,一旦找到最佳参数,就在原始的 20% 上测量性能一次。这确保您获得的结果尽可能健壮。
不要忘记使用 GitHub Gist 代码进行调整。谢谢阅读!
喜欢这篇文章,不得不承认,它的奇怪写作风格吗?想象一下,您可以访问数十篇类似的文章,都是由一位聪明、迷人、风趣的作者撰写的(顺便说一句,那就是我 :)。
只需 4.99 美元的会员费,您将获得访问小猪AI上最好、最聪明的头脑的知识的宝库,而不仅仅是我的故事。如果您使用我的推荐链接,您将获得我的超新星感激和虚拟高五,支持我的工作。
使用我的推荐链接加入小猪AI – Bex T.
获取对我所有⚡高级⚡内容和小猪AI上所有内容的独家访问权限。通过给我买一份…来支持我的工作。
ibexorigin.medium.com




