提升PyTorch在CPU上的推理能力:从训练后量化到多线程
Kaggle 蓝图
如何通过聪明的模型选择、ONNX Runtime 或 OpenVINO 的后训练量化以及 ThreadPoolExecutor 的多线程来减少 CPU 推理时间

欢迎来到“Kaggle 蓝图”的另一期,我们将分析 Kaggle 竞赛中的获胜解决方案,以便我们可以应用到自己的数据科学项目中。
本期将回顾“BirdCLEF 2023”比赛的技术和方法,该比赛于 2023 年 5 月结束。
问题陈述:在有限的时间和计算约束下进行深度学习推理
BirdCLEF 竞赛是 Kaggle 上一系列年度举办的竞赛。通常,BirdCLEF 竞赛的主要目标是通过声音识别特定的鸟种。竞赛者会获得单个鸟鸣的短音频文件,然后必须预测在更长的录音中是否存在特定的鸟种。
在早期的“Kaggle 蓝图”中,我们已经回顾了去年“BirdCLEF 2022”竞赛中基于深度学习的音频分类的获胜方法。
“BirdCLEF 2023”竞赛中的一个新颖之处是有限的时间和计算约束:竞争者需要在 2 小时内在 CPU Notebook 上预测大约 200 个长达 10 分钟的录音。
BirdCLEF 2023
识别声景中的鸟鸣声
www.kaggle.com
现在,您可能会问为什么有人要在 CPU 上推断深度学习模型而不是 GPU 上。这是一个常见的实际问题陈述[4],因为通常人员(特别是在保护方面,但也包括其他行业)有预算约束,因此只能访问有限的计算资源。此外,能够快速进行预测是有帮助的。
由于深度学习的音频分类方法如何处理的内容与上一期“Kaggle 蓝图”中的“BirdCLEF 2022”竞赛的获胜方法重复,因此本文将专注于如何加速 CPU 上深度学习模型的推理。
如果您对基于深度学习的音频分类的获胜方法感兴趣,请查看以前的版本:
使用 Python 进行深度学习的音频分类
使用 PyTorch 和 torchaudio 调整图像模型以处理域转移和类别不平衡的音频数据
towardsdatascience.com
接近 CPU 上的深度学习推理
在有限的时间内进行 CPU 推理的主要问题是您无法创建大型强大且多样化的模型集合,以挤出最后几个性能百分点。根据使用的模型,有些竞争者甚至难以满足单个模型的有限时间要求。
然而,通常情况下,较弱的模型集合通常表现比单个强大的模型更好。在竞赛的撰写中,成功的竞争者分享了一些加速 CPU 推理的技巧。
本文涵盖了撰写中分享的以下技巧:
- 模型选择
- 后训练量化
- 多线程
模型选择
模型大小会严重影响推理时间。作为经验法则:模型越大,推理时间越长。
作为经验法则:模型越大,推理时间越长。
因此,当选择其合模型的骨干网络时,竞争者不得不评估哪些模型在性能和推理时间之间取得了最好的平衡。
虽然在去年和今年的比赛中,NFNet(eca_nfnet_l0)[3、5、7、9、10、11、13、14、16]和EfficientNet没有改变作为流行的骨干网络,但我们可以看到在今年的比赛中,竞争者更喜欢EfficientNet的较小版本。
虽然在BirdCLEF 2022竞赛中,tf_efficientnet_b0_ns[8、11]、tf_efficientnet_b3_ns[8]、tf_efficientnetv2_s_in21k[11、16]和tf_efficientnetv2_m_in21k[13]很受欢迎,但今年更喜欢使用较小的版本tf_efficientnet_b0_ns[1、5、6、7、10]和tf_efficientnetv2_s_in21k[1、6、15]。
下面您可以看到一些BirdCLEF竞赛系列中流行模型的参数数量比较。
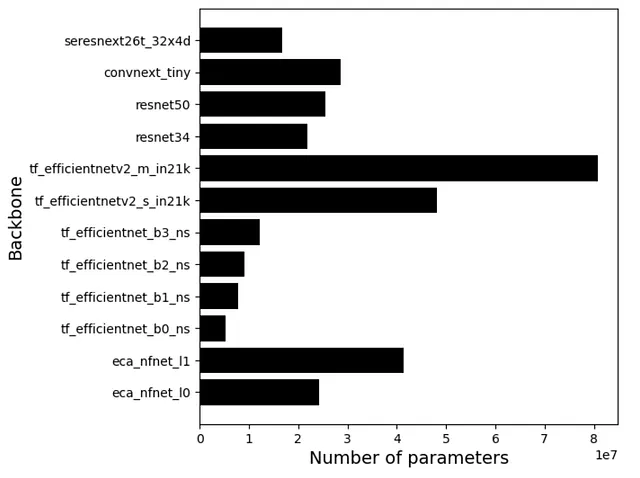
因此,我们可以看到,成功的竞争者利用了一个较大的模型(eca_nfnet_l0)和较小的模型(例如tf_efficientnet_b0_ns)的组合。
训练后量化
另一个加速CPU推理的技巧是在训练后对模型应用量化:训练后量化将模型的权重和激活从浮点精度(32位)降低到较低位宽表示(例如,8位)。
这种技术将模型转换为更适合硬件的表示形式,从而改善延迟。然而,由于权重和激活表示的精度损失,它也可能导致轻微的性能损失。
量化与硬件密不可分。例如,Kaggle Notebook有4个CPU(Intel(R)Xeon(R)CPU @ 2.20GHz,带有x86_64架构)。这些具有x86架构的Intel CPU更喜欢量化数据类型为INT8。
提示:要显示有关CPU架构的信息,请运行lscpu命令,然后检查制造商的主页,以查看该特定CPU首选哪种量化输入数据类型。
有关训练后量化的详细解释和ONNX Runtime和OpenVINO的比较,我建议阅读本文:
OpenVINO与ONNX在生产中的变换器比较
变换器已经彻底改变了NLP,使其成为机器翻译、语义等应用程序的首选…
blog.ml6.eu
本节将具体介绍训练后量化的两种流行技术:
- ONNX Runtime
- OpenVINO
ONNX Runtime
加速CPU推理的一种流行方法是将最终模型转换为ONNX(开放神经网络交换)格式[2、7、9、10、14、15]。
以下是使用ONNX Runtime量化和加速CPU推理的相关步骤:
准备工作:安装ONNX Runtime
pip install onnxruntime第1步:将PyTorch模型转换为ONNX
import torchimport torchvision# 在此处定义您的模型model = ...# 在此处训练模型...# 定义dummy_inputdummy_input = torch.randn(1, N_CHANNELS, IMG_WIDTH, IMG_HEIGHT, device="cuda")# 将PyTorch模型导出为ONNX格式torch.onnx.export(model, dummy_input, "model.onnx")步骤二: 使用ONNX Runtime会话进行预测
import onnxruntime as rt# 使用形状为(BATCH_SIZE, N_CHANNELS, IMG_WIDTH, IMG_HEIGHT)的X_test定义X_test = ...# 定义ONNX Runtime会话sess = rt.InferenceSession("model.onnx")# 进行预测y_pred = sess.run([], {'input' : X_test})[0]OpenVINO
同样流行的加速CPU推断的方法是使用OpenVINO(Open Visual Inference and Neural network Optimization)[5, 6, 12],如在这个Kaggle Notebook中所示:
openvino是你所需要的
探索和运行Kaggle Notebooks中的机器学习代码|使用多个数据源的数据
www.kaggle.com
使用OpenVINO量化和加速深度学习模型的相关步骤如下:
准备工作: 安装OpenVINO
!pip install openvino-dev[onnx]步骤一: 将PyTorch模型转换为ONNX(参见ONNX Runtime的步骤1)
步骤二: 将ONNX模型转换为OpenVINO
mo --input_model model.onnx这将输出一个XML文件和一个BIN文件,我们将在下一步中使用XML文件。
步骤三: 使用OpenVINO将模型量化为INT8
import openvino.runtime as ovcore = ov.Core()openvino_model = core.read_model(model='model.xml')compiled_model = core.compile_model(openvino_model, device_name="CPU")步骤四: 使用OpenVINO推理请求进行预测
# 使用形状为(BATCH_SIZE, N_CHANNELS, IMG_WIDTH, IMG_HEIGHT)的X_test定义X_test = ...# 创建推理请求infer_request = compiled_model.create_infer_request()# 进行预测y_pred = infer_request.infer(inputs=[X_test, 2])比较:ONNX vs. OpenVINO vs. 替代方案
ONNX和OpenVINO都是为在CPU上部署模型进行优化的框架。使用ONNX和OpenVINO量化的神经网络推理时间据说是可比较的[12]。
一些竞争对手使用PyTorch JIT [3]或TorchScript [1]作为加速CPU推理的替代方案。然而,其他竞争者分享了ONNX比TorchScript快得多的经验[10]。
使用ThreadPoolExecutor进行多线程
另一种加速CPU推理的流行方法是使用多线程ThreadPoolExecutor [2、3、9、15],除了训练后量化之外,如在这个Kaggle Notebook中所示:
更快的eb0_SED模型推理
探索和运行Kaggle Notebooks中的机器学习代码|使用多个数据源的数据
www.kaggle.com
这使竞争对手能够同时运行多个推理。
在竞赛中使用ThreadPoolExecutor的下面示例中,我们有一个要推理的音频文件列表。
audios = ['audio_1.ogg', 'audio_2.ogg', # ..., 'audio_n.ogg',]接下来,您需要定义一个推理函数,该函数将音频文件作为输入并返回预测结果。
def predict(audio_path): # 在这里定义任何音频文件的预处理 ... # 进行预测 ... return predictions有了音频列表(例如audios)和推理函数(例如predict()),现在可以使用ThreadPoolExecutor同时运行多个推理(并行)而不是顺序运行,这将在推理时间上给您一个很好的提升。
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
dicts = list(executor.map(predict, audios))概述
通过回顾 Kagglers 在“BirdCLEF 2023”比赛期间创建的学习资源,我们可以学到很多东西。对于这类问题,也有许多不同的解决方案。
在本文中,我们重点讨论了许多竞争者都采用的一般方法:
- 模型选择:根据性能和推理时间之间的最佳平衡选择模型大小。此外,利用更大和更小的模型进行组合。
- 训练后量化:由于模型权重和激活的数据类型被优化为硬件,因此后训练量化可以导致更快的推理时间。但是,这可能会导致轻微的模型性能损失。
- 多线程:并行运行多个推理,而不是按顺序运行。这将提高推理时间。
如果您对如何使用深度学习处理音频分类感兴趣,这是本次比赛的主要方面,请查看 BirdCLEF 2022 比赛的详细介绍:
使用 Python 进行深度学习的音频分类
使用 PyTorch 和 torchaudio 对图像模型进行微调以解决域转移和类别不平衡问题
towardsdatascience.com
喜欢这个故事吗?
免费订阅以在我发布新故事时接收通知。
想要阅读超过 3 篇免费故事吗?-成为小猪AI会员只需 5 美元/月。使用我的推荐链接注册可以支持我,没有额外费用。
使用我的推荐链接加入小猪AI-Leonie Monigatti
在小猪AI上阅读来自 Leonie Monigatti(以及数千名其他作家)的所有故事。您的会员费直接支付…
小猪AI.com
在 LinkedIn、Twitter 和 Kaggle 上找到我!
参考资料
图片来源
除非另有说明,所有图片均由作者创建。
网络和文献
[1] adsr(2023)。Kaggle 讨论中的第三名解决方案:带有 Mel 频段关注的 SED(2023 年 6 月 1 日访问)
[2] anonamename(2023)。Kaggle 讨论中的第六名解决方案:BirdNET 嵌入 + CNN(2023 年 6 月 1 日访问)
[3] atfujita(2023)。Kaggle 讨论中的第四名解决方案:知识蒸馏是你所需要的(2023 年 6 月 1 日访问)
[4] beluga(2023)。推理限制 – CPU Notebook <= 120 分钟(2023 年 3 月 27 日访问)。
[5] Harshit Sheoran(2023)。Kaggle 讨论中的第九名解决方案:7 个 CNN 模型集合(2023 年 6 月 1 日访问)
[6] HONG LIHANG(2023)。Kaggle 讨论中的第二名解决方案:带有 7 个模型集成的 SED + CNN(2023 年 6 月 1 日访问)
[7] HyeongChan Kim(2023)。Kaggle 讨论中的第 24 名解决方案 – 预训练和单个模型(带有 ONNX 的 5 折集成)(2023 年 6 月 1 日访问)
[8] LeonShangguan(2022)。[ 公开 #1 私人 #2 ] + [ 私人 #7/8(潜在)] 解决方案。主持人获胜。在 Kaggle 讨论中(2023 年 3 月 13 日访问)
[9] LeonShangguan (2023). Kaggle 讨论区第十名方案(访问日期:2023年6月1日)
[10] moritake04 (2023). Kaggle 讨论区第二十名方案:使用 ONNX 的 SED + CNN 集成方案(访问日期:2023年6月1日)
[11] slime (2022). Kaggle 讨论区第三名方案(访问日期:2023年3月13日)
[12] storm (2023). Kaggle 讨论区第七名方案——“sumix”增强技术起到了全部作用(访问日期:2023年6月1日)
[13] Volodymyr (2022). Kaggle 讨论区第一名方案模型(并非全部使用 BirdNet)(访问日期:2023年3月13日)
[14] Volodymyr (2023). Kaggle 讨论区第一名方案:正确的数据是你所需要的一切(访问日期:2023年6月1日)
[15] Yevhenii Maslov (2023). Kaggle 讨论区第五名方案(访问日期:2023年6月1日)
[16] yokuyama (2022). Kaggle 讨论区第五名方案(访问日期:2023年3月13日)