12个数据科学的思维模型
探究数据科学领域的强大概念

简介
在不断发展的数据科学领域中,处理和分析数据的原始技术能力无疑对任何数据项目至关重要。除了技术和软技能,经验丰富的数据科学家可能还会在多年中开发一套被称为心理模型的概念工具,以帮助他们在数据领域中导航。
心理模型不仅对数据科学有帮助,James Clear(《原子习惯》的作者)在本文中探讨了心理模型如何帮助我们更好地思考以及它们在广泛领域(商业、科学、工程等)的实用性。
就像木匠使用不同的工具来完成不同的任务一样,数据科学家根据手头的问题使用不同的心理模型。这些模型提供了一种结构化的问题解决和决策制定方式。它们使我们能够简化复杂的情况,突出相关信息,并对未来做出教育猜测。
本博客介绍了12个可能有助于提高数据科学生产力的心理模型。特别是,我们通过说明这些模型如何在数据科学环境中应用来进行说明,然后对每个模型进行简短的解释。无论您是经验丰富的数据科学家还是新来者,了解这些模型对您的数据科学实践都有帮助。
1. 垃圾进,垃圾出
任何数据分析的第一步都是确保您使用的数据具有高质量,因为您从中得出的任何结论都将基于这些数据。此外,这可能意味着即使最复杂的分析也无法弥补低质量数据的影响。简而言之,这一概念强调输出质量取决于输入质量。在处理数据时,数据集的整理和预处理将有助于提高数据的质量。
2. 大数定律
在确保数据质量之后,下一步通常是收集更多数据。大数定律解释了为什么拥有更多数据通常会导致更准确的模型。这个原则表明,随着样本大小的增长,其平均值也越来越接近整个人口的平均值。这在数据科学中是基础,因为它支撑着收集更多数据以提高模型的泛化和准确性的逻辑。
3. 确认偏差
一旦有了数据,您必须小心地解释它。确认偏差提醒我们避免仅寻找支持假设的数据,并考虑所有证据。尤其是,确认偏差指的是倾向于以一种符合自己先前信念或假设的方式搜索、解释、偏爱和回忆信息的趋势。在数据科学中,了解这种偏见并寻找证实和证伪的证据都是至关重要的。
4. P-Hacking
这是在数据分析阶段需要记住的另一个重要概念。这指的是误用数据分析来有选择地寻找可以呈现为具有统计显着性的数据模式,从而导致不正确的结论。简而言之,罕见的统计显着结果(无论是故意还是偶然地)可能会被有选择地呈现。因此,了解这一点以确保进行稳健和诚实的数据分析非常重要。
5. 辛普森悖论
这个悖论提醒我们,在查看数据时,考虑不同的群体可能会影响您的结果是很重要的。它警示我们不要忽略上下文和不考虑可能的混淆变量。当数据的不同组中出现趋势,但这些组合在一起时趋势消失或反转时,就会发生这种统计现象。当因果关系得到适当处理时,这种悖论可以得到解决。

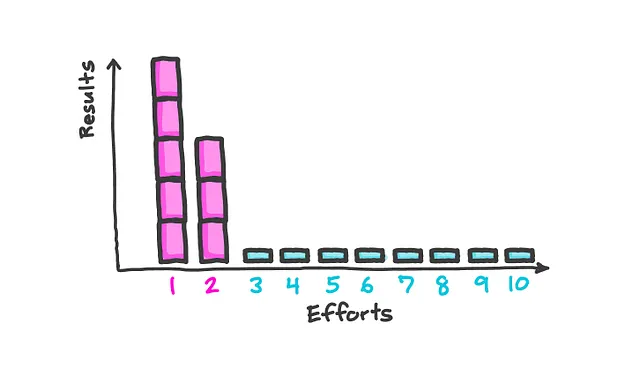
6. 帕累托 80/20 法则
一旦数据被理解并且问题被定义,这个模型可以帮助确定在模型中要关注哪些特征,因为它表明少数原因往往导致大部分结果。
这个原则表明,对于许多结果,大约 80% 的后果来自 20% 的原因。在数据科学中,这可能意味着模型的大部分预测能力来自于一小部分特征。
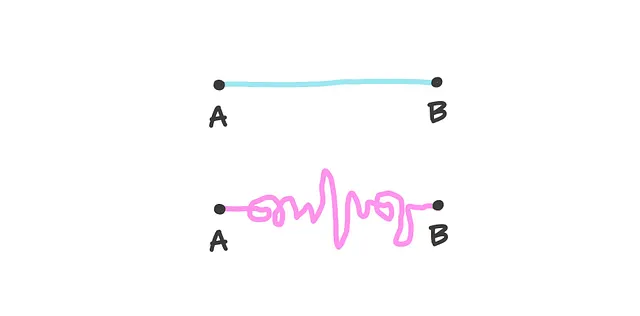
7. 奥卡姆剃刀
这个原则表明,最简单的解释通常是最好的解释。当你开始建立模型时,奥卡姆剃刀建议你在性能相同的情况下更喜欢简单的模型。因此,它提醒我们不要不必要地使模型过于复杂。
8. 偏差-方差权衡
这个心理模型描述了模型中必须平衡偏差和方差这两种误差来源。偏差是由于将复杂问题简化以使机器学习模型更容易理解而引起的错误,从而导致欠拟合。方差是由于模型过于强调训练数据的细节而导致的错误,从而导致过拟合。因此,通过权衡,可以达到适当的模型复杂度,以最小化总误差(偏差和方差的组合)。特别是,减少偏差倾向于增加方差,反之亦然。
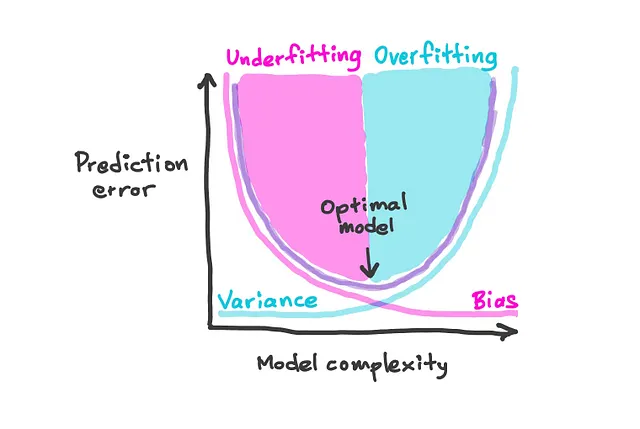
9. 过拟合与欠拟合
这个概念与偏差-方差权衡密切相关,并有助于进一步指导调整模型的复杂度和其对新数据的泛化能力。
当模型过于复杂并过于完美地学习训练数据,从而降低其在新的未见过的数据上的效果时,就会发生过拟合。欠拟合发生在模型过于简单而不能捕捉数据的基本结构,从而导致在训练和未见的数据上表现不佳。
因此,通过找到过拟合和欠拟合之间的平衡,可以得到一个好的机器学习模型。例如,可以通过交叉验证、正则化和修剪等技术来实现。
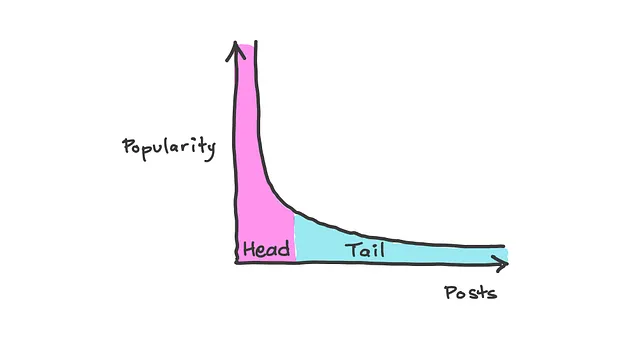
10. 长尾
长尾可以在帕累托分布或幂律分布等分布中看到,其中可以观察到低价值事件的高频率和高价值事件的低频率。了解这些分布对于处理实际数据非常重要,因为许多自然现象遵循这些分布。
例如,在社交媒体参与度方面,少数帖子获得了大部分的点赞、分享或评论,但是还有一大批帖子的互动较少。总体来说,这一长尾可以代表社交媒体活动的相当一部分。这引起了对不受欢迎或罕见事件的重要性和潜力的关注,如果只关注分布的“头部”,则这些事件可能会被忽视。
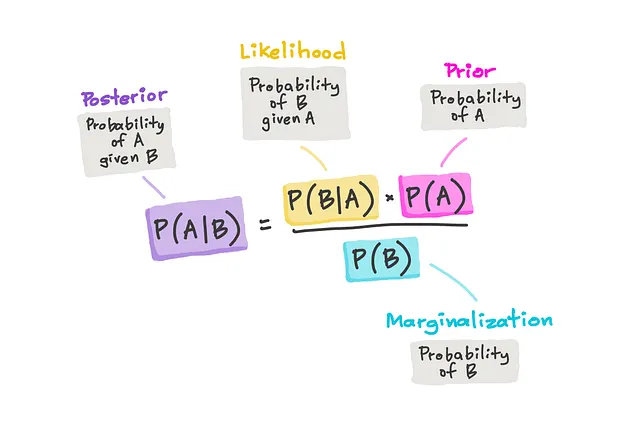
11. 贝叶斯思维
贝叶斯思维是指根据新证据不断更新我们的信念的动态和迭代过程。最初,我们有一个信念或“先验”,这个先验会随着新数据的更新而得到修正,形成一个修订的信念或“后验”。随着收集到越来越多的证据,这个过程会继续,进一步完善我们的信念。在数据科学中,贝叶斯思维允许从数据中学习和进行预测,通常还提供围绕这些预测的不确定性度量。这种开放接受新信息的自适应信念系统不仅可以应用于数据科学,也可以应用于我们日常的决策。
12. 没有免费午餐定理
没有免费午餐定理断言,没有一种单一的机器学习算法能够在解决每个问题方面都表现出色。因此,重要的是要了解每个数据问题的独特特征,因为并不存在普遍优越的算法。因此,数据科学家会尝试使用各种模型和算法,通过考虑数据的复杂性、可用的计算资源和具体的任务等因素,找到最有效的解决方案。这个定理可以被看作是一个装满工具的工具箱,其中每个工具代表一个不同的算法,专业知识在于选择适合任务(问题)的正确工具(算法)。

结论
这些模型为典型数据科学项目的每个步骤提供了一个强大的框架,从数据收集和预处理到模型构建、优化和更新。它们帮助我们导航数据驱动的决策制定的复杂领域,使我们能够避免常见的陷阱、有效地优先考虑和做出明智的选择。
然而,必须记住没有一个单一的心智模型能够解决所有问题。每个模型都是一种工具,像所有工具一样,它们在适当使用时最有效。特别是,数据科学的动态和迭代性意味着这些模型不仅仅是以线性方式应用的。随着新的数据变得可用或我们对问题的理解发展,我们可能会回到早期的步骤,应用不同的模型并相应地调整我们的策略。
最终,使用这些数据科学心智模型的目标是从数据中提取有价值的见解,创建有意义的模型并做出更好的决策。通过这样做,我们可以释放数据科学的全部潜力,用它来推动创新、解决复杂问题,并在各个领域(例如生物信息学、药物发现、医疗保健、金融等)产生积极影响。
使用我的推荐链接加入小猪AI – Chanin Nantasenamat
如果您觉得这篇文章有帮助,请成为小猪AI会员,支持我作为作者。每月费用为5美元,提供…
data-professor.medium.com
阅读下面的文章…
如何掌握数据科学中的Scikit-learn
以下是数据科学中必备的Scikit-learn
towardsdatascience.com
如何掌握Python数据科学
以下是数据科学中必备的Python
towardsdatascience.com
接下来观看…
- Streamlit YouTube播放列表——我在我的YouTube频道Data Professor上创建的52个Streamlit教程视频的不断增长的收藏。