重新定义数据体验:使用生成式人工智能和现代数据架构来解锁洞见
实现现代数据架构提供了一种可扩展的方法来整合来自不同来源的数据。通过按业务领域而不是基础架构组织数据,每个领域可以选择适合其需求的工具。组织可以通过生成式人工智能解决方案最大化其现代数据架构的价值,同时不断创新。
自然语言功能允许非技术用户通过对话式英语而不是复杂的SQL查询数据。然而,实现全部优势需要克服一些挑战。人工智能和语言模型必须识别适当的数据源,生成有效的SQL查询,并以嵌入式结果的连贯响应在规模上进行。它们还需要一个自然语言问题的用户界面。
总的来说,利用AWS的现代数据架构和生成式人工智能技术是从多样化、广泛的数据中获取和传播关键见解的有前途的方法。AWS的最新生成式人工智能产品是Amazon Bedrock,它是一个完全托管的服务,也是使用基础模型构建和扩展生成式人工智能应用程序的最简单方法。AWS还通过Amazon SageMaker JumpStart作为Amazon SageMaker端点提供基础模型。大型语言模型(LLMs)的组合,包括Amazon Bedrock提供的易于集成的便利性,以及可扩展的面向领域的数据基础设施,将其定位为利用各种分析数据库和数据湖中丰富信息的智能方法。
在本文中,我们展示了一个场景,其中一家公司部署了具有多个数据库和API上的数据的现代数据架构,例如Amazon Simple Storage Service(Amazon S3)上的法律数据,Amazon关系数据库服务(Amazon RDS)上的人力资源,Amazon Redshift上的销售和营销,第三方数据仓库解决方案Snowflake上的金融市场数据以及产品数据作为API。这个实现旨在通过在该领域网状结构中使用生成式人工智能来提高企业业务分析、产品所有者和业务领域专家的生产力,从而更有效地实现公司的业务目标。这个解决方案有包括JumpStart中的LLMs作为SageMaker端点以及第三方模型的选择。我们为企业用户提供了一个小猪AI,可以询问基于事实的问题,而不必了解数据通道的基础知识,从而抽象出编写简单到复杂SQL查询的复杂性。
解决方案概述
在AWS上的现代数据架构应用人工智能和自然语言处理来查询多个分析数据库。通过使用Amazon Redshift、Amazon RDS、Snowflake、Amazon Athena和AWS Glue等服务,它创建了一个可扩展的解决方案,以整合来自各种来源的数据。使用LangChain,一种用于处理LLMs的强大库,包括Amazon Bedrock和JumpStart中的基础模型在内的SageMaker工作室笔记本电脑,构建了一个系统,用户可以用自然英语提出业务问题,并收到从相关数据库绘制的数据的答案。
以下图表说明了架构。
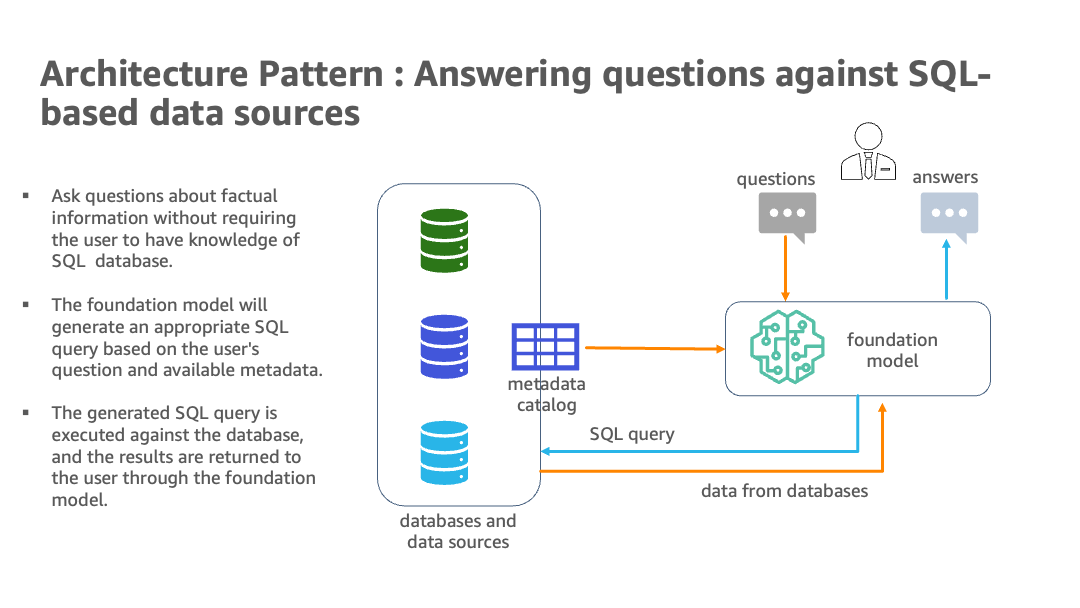
混合架构使用多个数据库和LLMs,其中包括来自Amazon Bedrock和JumpStart的基础模型,用于数据源识别、SQL生成和包含结果的文本生成。
以下图表说明了我们解决方案的特定工作流程步骤。
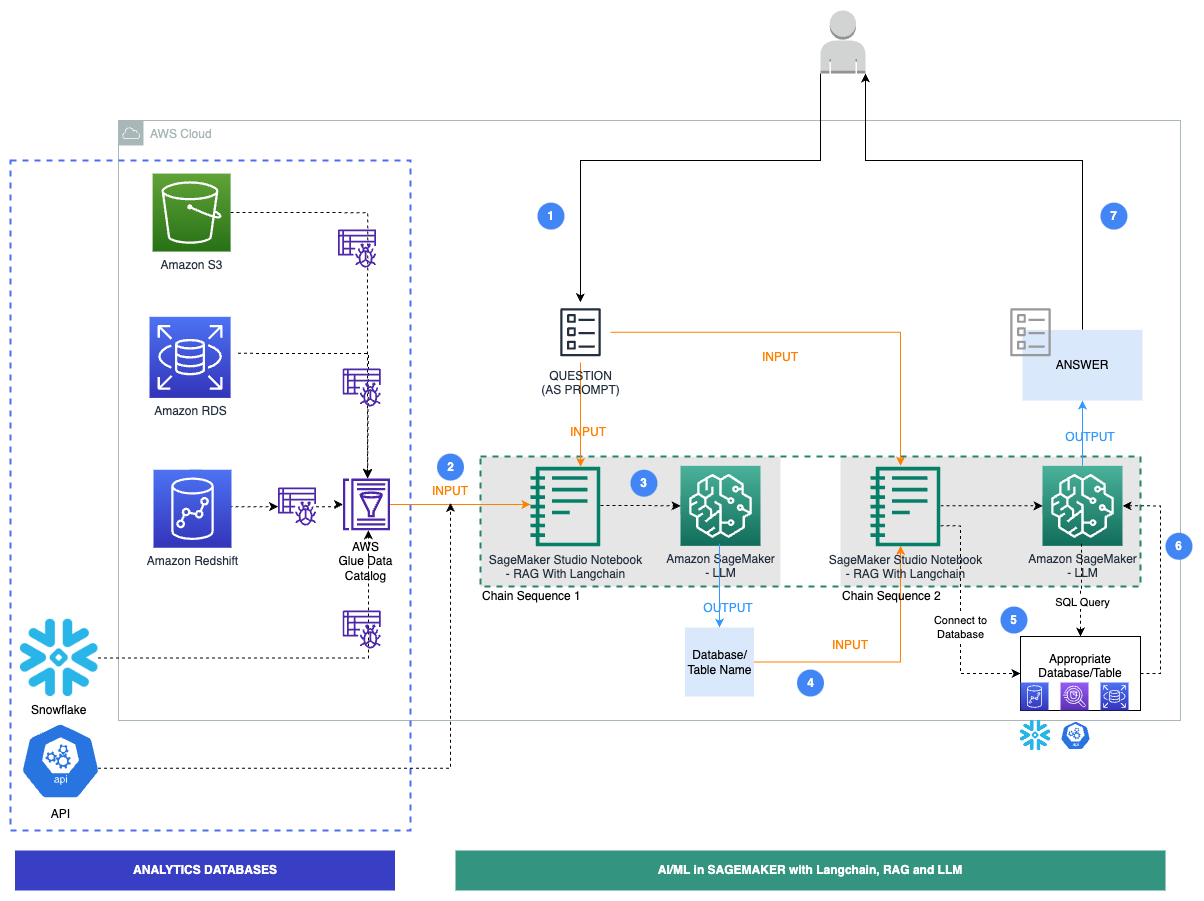
步骤如下:
- 业务用户提供英语问题提示。
- 安排AWS Glue爬虫定期运行,从数据库中提取元数据并创建AWS Glue数据目录中的表定义。数据目录是输入到链序列1中的(见上图)。
- LangChain是在工作室笔记本电脑中使用的用于处理LLMs和提示的工具。LangChain需要定义LLM。作为链序列1的一部分,将提示和数据目录元数据传递给托管在SageMaker端点上的LLM,以使用LangChain识别相关数据库和表。
- 将提示和识别的数据库和表传递给链序列2。
- LangChain建立到数据库的连接并运行SQL查询以获取结果。
- 结果传递给LLM以生成带有数据的英语答案。
- 用户收到从不同数据库查询的英语答案。
以下部分解释了一些关键步骤及相关代码。要深入了解此解决方案和所有步骤的代码,请参阅 GitHub 存储库。以下图表显示了所遵循的步骤序列:

先决条件
您可以使用任何与 SQLAlchemy 兼容的数据库来生成 LLMs 和 LangChain 的响应。但是,这些数据库必须将其元数据注册到 AWS Glue 数据目录中。此外,您需要通过 JumpStart 或 API 密钥访问 LLMs。
使用 SQLAlchemy 连接到数据库
LangChain 使用 SQLAlchemy 连接到 SQL 数据库。我们通过为每个数据源创建引擎并建立连接来初始化 LangChain 的 SQLDatabase 函数。以下是如何连接到 Amazon Aurora MySQL-Compatible Edition 无服务器数据库并仅包括 employees 表格的示例:
#连接到 AWS Aurora MySQL
cluster_arn = <cluster_arn>
secret_arn = <secret_arn>
engine_rds=create_engine('mysql+auroradataapi://:@/employees',echo=True,
connect_args=dict(aurora_cluster_arn=cluster_arn, secret_arn=secret_arn))
dbrds = SQLDatabase(engine_rds, include_tables=['employees'])接下来,我们构建 Chain Sequence 1 使用的提示,以根据用户问题识别数据库和表格名称。
生成动态提示模板
我们使用 AWS Glue 数据目录(旨在存储和管理元数据信息)来识别用户查询的数据源,并根据以下步骤为 Chain Sequence 1 构建提示:
- 使用演示中使用的 JDBC 连接遍历多个数据源的元数据来构建数据目录。
- 使用 Boto3 库,我们从多个数据源构建数据目录的汇总视图。以下是如何从 Aurora MySQL 数据库的数据目录获取 employees 表格的元数据的示例:
#从粘合剂数据目录检索元数据
glue_tables_rds = glue_client.get_tables(DatabaseName=<database_name>, MaxResults=1000)
for table in glue_tables_rds['TableList']:
for column in table['StorageDescriptor']['Columns']:
columns_str=columns_str+'\n'+('rdsmysql|employees|'+table['Name']+"|"+column['Name'])汇总的数据目录具有有关数据源的详细信息,例如模式、表格名称和列名称。以下是汇总数据目录的输出示例:
database|schema|table|column_names
redshift|tickit|tickit_sales|listid
rdsmysql|employees|employees|emp_no
....
s3|none|claims|policy_id- 我们将汇总的数据目录传递给提示模板,并定义 LangChain 使用的提示:
prompt_template = """
从下表中找到包含用于回答问题 {query} 的数据(在相应的 column_names 中)的数据库(在 database 列中)。
"""+glue_catalog +"""将您的答案作为 database == 提供。
将您的答案作为 database.table ==="""
Chain Sequence 1:使用 LangChain 和 LLM 检测用户查询的源元数据
我们将在前一步骤中生成的提示模板与用户查询一起传递给 LangChain 模型,以查找回答问题的最佳数据源。LangChain 使用我们选择的 LLM 模型来检测源元数据。
使用以下代码使用 JumpStart 或第三方模型的 LLM:
#在此处定义 LLM 模型
llm = <LLM>
#将提示模板和用户查询传递给提示
PROMPT = PromptTemplate(template=prompt_template, input_variables=["query"])
#定义 llm 链
llm_chain = LLMChain(prompt=PROMPT, llm=llm)
#运行查询并保存到生成的文本中
generated_texts = llm_chain.run(query)生成的文本包含有关用户查询执行的数据库和表名等信息。例如,对于用户查询“列出本月出生的所有员工”,generated_text包含了database == rdsmysql和database.table == rdsmysql.employees等信息。
接下来,我们将人力资源领域、Aurora MySQL数据库和员工表的详细信息传递给链序列2。
链序列2:从数据源检索响应以回答用户查询
然后,我们运行LangChain的SQL数据库链将文本转换为SQL,并隐式地针对数据库运行生成的SQL以检索简单易读的语言中的数据库结果。
我们先定义一个提示模板,指导LLM生成一个语法正确的SQL查询,然后针对数据库运行它:
_DEFAULT_TEMPLATE = """给定一个输入问题,首先创建一个语法正确的{dialect}查询来运行,然后查看查询结果并返回答案。
只使用以下表:
{table_info}
如果有人要求销售额,他们真正想要的是tickit.sales表。
问题:{input}"""
#define the prompt
PROMPT = PromptTemplate( input_variables=["input", "table_info", "dialect"], template=_DEFAULT_TEMPLATE)最后,我们将LLM、数据库连接和提示传递给SQL数据库链并运行SQL查询:
db_chain = SQLDatabaseChain.from_llm(llm, db, prompt=PROMPT)
response=db_chain.run(query)例如,对于用户查询“列出本月出生的所有员工”,答案如下:
问题:列出本月出生的所有员工
SELECT * FROM employees WHERE MONTH(birth_date) = MONTH(CURRENT_DATE());
用户响应:
本月生日的员工有:
Christian Koblick
Tzvetan Zielinski清理
在运行具有生成AI的现代数据架构之后,请确保清理不再使用的任何资源。关闭并删除使用的数据库(Amazon Redshift,Amazon RDS,Snowflake)。此外,删除Amazon S3中的数据并停止任何Studio笔记本实例,以避免产生进一步的费用。如果您使用JumpStart将LLM部署为SageMaker实时端点,请通过SageMaker控制台或Studio删除端点。
结论
在本文中,我们在SageMaker中将现代数据架构与生成AI和LLMs集成。该解决方案使用了JumpStart的各种文本到文本基础模型以及第三方模型。这种混合方法可以识别数据源,编写SQL查询并生成带有查询结果的响应。它使用Amazon Redshift,Amazon RDS,Snowflake和LLMs。为了改进解决方案,您可以添加更多数据库、英文查询的UI、提示工程和数据工具。这可以成为从多个数据存储库获取洞察的智能、统一的方式。要深入了解解决方案和本文中显示的代码,请查看GitHub存储库。此外,请参考Amazon Bedrock,了解生成AI、基础模型和大型语言模型的用例。