使用GPT-4进行引导标签化

一种成本效益高的数据标记方法
数据标记是机器学习项目中的关键组成部分。它建立在老话语“垃圾进,垃圾出”的基础上。标记包括创建用于训练和评估的带注释的数据集。但是,对于大量数据的项目,这个过程可能耗费时间和金钱。但是,如果我们可以利用LLM的进步来减少数据标记任务所需的成本和工作量呢?
GPT-4是由OpenAI开发的最先进的语言模型。它具有出色的理解和生成类人文本的能力,并已成为自然语言处理(NLP)社区等领域的变革者。在本博客文章中,我们将探讨如何使用GPT-4为各种任务引导标签。这可以显著减少标记过程所需的时间和成本。我们将重点关注情感分类,以演示如何使用GPT-4进行快速工程,使您能够使用GPT-4创建准确可靠的标签,以及如何将此技术用于更强大的事物。
利用GPT-4的预测进行数据预标记
如同写作,编辑通常比创作原始工作要轻松得多。这就是为什么从预标记的数据开始比从一个空白的画布开始更有吸引力的原因。使用GPT-4作为预测引擎进行预标记的数据源自其理解上下文和生成类人文本的能力。因此,利用GPT-4来减少数据标记所需的手动工作将是很好的。这可能会带来成本节约,并使标记过程不那么乏味。
那么我们该怎么做呢?如果您使用过GPT模型,那么您可能熟悉提示。提示在模型开始生成输出之前设置模型的上下文,并可以进行微调和工程化(即提示工程),以帮助模型提供高度特定的结果。这意味着我们可以创建GPT-4可以使用的提示,以生成看起来像模型预测的文本。对于我们的用例,我们将以指导模型产生所需输出格式的方式来设计我们的提示。
让我们以情感分析为一个简单的例子。如果我们试图将给定的文本字符串的情感分类为positive,negative或neutral,我们可以提供如下提示:
"将以下文本的情感分类为'positive'、'negative'或'neutral':<input_text>"一旦我们有了结构良好的提示,就可以使用OpenAI API从GPT-4生成预测。这里是使用Python的示例:
import openaiimport reopenai.api_key = "<your_api_key>"def get_sentiment(input_text): prompt = f"以json格式回复:{{'response': sentiment_classification}}\n文本:{input_text}\n情感(positive、neutral、negative):" response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "user", "content": prompt} ], max_tokens=40, n=1, stop=None, temperature=0.5, ) response_text = response.choices[0].message['content'].strip() sentiment = re.search("negative|neutral|positive", response_text).group(0) # Add input_text back in for the result return {"text": input_text, "response": sentiment}我们可以运行一个单一的示例来检查我们从API接收到的输出。
# 测试单个示例sample_text = "昨晚我在派对上度过了可怕的时光!"sentiment = get_sentiment(sample_text)print("结果\n",f"{sentiment}")
结果:{'text': '昨晚我在派对上度过了可怕的时光!', 'response': 'negative'}一旦我们对提示和我们从中获得的结果满意,我们就可以将其扩展到整个数据集。在这里,我们将假设一个文本文件,其中每行都有一个示例。
import json
input_file_path = "input_texts.txt"
output_file_path = "output_responses.json"
with open(input_file_path, "r") as input_file, open(output_file_path, "w") as output_file:
examples = []
for line in input_file:
text = line.strip()
if text:
examples.append(convert_ls_format(get_sentiment(text)))
output_file.write(json.dumps(examples))
我们可以将具有预标签预测的数据导入到Label Studio中,让审阅者验证或更正标签。这种方法极大地减少了数据标记所需的手动工作,因为人工审阅者只需要验证或更正模型生成的标签,而不是从头开始注释整个数据集。在这里查看我们的完整示例笔记本。
请注意,在大多数情况下,OpenAI被允许使用发送到其API的任何信息来进一步训练其模型。因此,如果不想将信息更广泛地公开,就重要不要将受保护或私人数据发送到这些API进行标记。
在Label Studio中审阅预标签数据
一旦我们准备好预标签数据,就可以将其导入到数据标记工具(例如Label Studio)中进行审阅。本节将指导您设置Label Studio项目,导入预标签数据并审查注释。

步骤1:安装和启动Label Studio
首先,您需要在计算机上安装Label Studio。您可以使用pip安装它:
pip install label-studio安装Label Studio后,通过运行以下命令来启动它:
label-studio这将在默认的Web浏览器中打开Label Studio。
步骤2:创建新项目
单击“创建项目”并输入项目名称,例如“审阅引导标签”。接下来,您需要定义标注配置。对于情感分析,我们可以使用文本情感分析文本分类。
这些模板是可配置的,因此如果我们想更改任何属性,那么非常简单。默认的标注配置如下所示。
<View> <Header value="Choose text sentiment:"/> <Text name="my_text" value="$reviewText"/> <Choices name="sentiment" toName="my_text" choice="single" showInline="true"> <Choice value="Positive"/> <Choice value="Negative"/> <Choice value="Neutral"/> </Choices></View>单击“创建”以完成项目设置。
步骤3:导入预标签数据
要导入预标签数据,请单击“导入”按钮。选择json文件并选择之前生成的预标签数据文件(例如“output_responses.json”)。将导入数据以及预填充的预测一起导入。
步骤4:审查和更新标签
导入数据后,您可以审查模型生成的标签。注释界面将为每个文本样本显示预标记的情感,审阅者可以接受或更正建议的标签。
通过让多个注释者审查每个示例,您可以进一步提高质量。
通过利用GPT-4生成的标签作为起点,审查过程变得更加高效,审阅者可以专注于验证或更正注释,而不是从头开始创建它们。
步骤5:导出标记数据
完成审阅过程后,您可以通过单击“数据管理器”选项卡中的“导出”按钮导出标记数据。选择所需的输出格式(例如JSON、CSV或TSV),并将标记数据集保存以供在机器学习项目中进一步使用。
成本分析
我脑海中一直有一个问题: “这最终花费了我多少钱?”
注意:下面显示的价格反映了作者在发布时的当前数据。未来或基于地理位置,价格可能会有所不同。
对于语言模型,OpenAI根据您请求中的标记数量收费。标记通常是查询中的单词数,但特殊字符和表情符号有时会被视为单个标记。 OpenAI的定价页面指出,“您可以将标记视为单词的一部分,其中1,000个标记约为750个单词。”有关如何计算标记的更多信息,请参见此页面。
每个标记的成本根据所使用的模型而异。例如,GPT-4 8K-context模型的成本为每1K标记的提示为$0.03,每个生成的标记的成本为$0.06 / 1K标记,而GPT-3.5-turbo模型的成本为$0.002 / 1K标记。

为了估计数据集预标记的成本,我们可以使用一个简单的公式,考虑数据集中的示例数量,提示和完成的每个标记价格以及每个示例的平均标记数。

其中:

此外,我们可以计算数据集中标记的总数,如下所示:
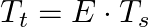
其中:
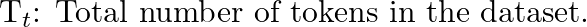
使用此公式,我们可以通过将示例数乘以提示成本和完成成本之和来估算预标记数据集的成本,根据每个示例的平均标记数进行调整。
例如,如果我们有一个包含1,000个示例的数据集,我们想要使用GPT-4进行情感分析进行预标记,我们可以使用以下公式进行计算:提示价格为每1K标记$0.03,完成价格为每1K标记$0.06,提示长度为20个标记,平均示例长度为80个标记,平均结果标记长度为3个标记,预标记的总成本将是:

在此示例中,使用GPT-4进行预标记的成本为$3.18。注意:使用GPT-3.5-turbo的相同数据集将花费约$0.21。
如果我们的预标记任务需要较少的专业知识,我们可能需要使用较不稳定的模型以节省成本。通常值得手动审查一些具有不同复杂性水平的示例,以了解一个模型与另一个模型相比的准确性。有关模型的信息,请参见OpenAI定价页面。
超越情感分析:标记任何NLP任务

这种方法的好处在于它不仅仅局限于情感分析。我们可以使用提示工程在GPT-4中为各种NLP任务预先标记数据,并引导它生成正确的输出。以下是几个不同NLP任务的提示示例,所有这些示例都可以在Label Studio中进行审核和标记(使用GPT-4生成)。请记住,更复杂的任务可能需要更长的提示,这将计入您的令牌计数,并随后产生费用。
摘要
- 提示:
以JSON格式回复以下文本的摘要:{‘summary’:summary}
文本:我喜欢在晴天去公园。客户服务很糟糕;他们很粗鲁,也没有什么帮助。我对新政策变化既不高兴也不难过。蛋糕很好吃,演示很棒。我对产品有非常糟糕的经历,它在两天后就坏了。
摘要:
回复:
{'summary': '人工智能是一种快速发展的技术,它能够从数据中学习并做出决策,而无需明确编程。它有助于解决世界上一些最紧迫的问题,但也存在风险和道德考虑,如偏见和工作替代。重要的是要考虑人工智能的影响,并确保负责任和有益的使用。'}分类学
提示:
以JSON格式回复以下文本的诊断摘要:{‘diagnosis’:diagnosis},其中可能的诊断包括肺炎、急性支气管炎、哮喘恶化、充血性心力衰竭、慢性阻塞性肺疾病(COPD)、肺栓塞、胸腔积液、间质性肺疾病或肺癌。
文本:患者出现气短和持续咳嗽。体格检查中,在下肺野听到啰音。胸部X线显示双侧浸润,与肺炎一致。患者开始服用抗生素,并在48小时内症状有所改善。
诊断:
回复:
{'diagnosis': '肺炎'}命名实体识别(NER)
提示:
您是一位专业的NER标注员。仅返回JSON。不返回解释。以JSON格式返回以下句子的CoNLL格式。
回复:
{ "data": [ { "word": "哈利", "entity": "B-PER" }, { "word": "波特", "entity": "I-PER" }, { "word": "是", "entity": "O" }, { "word": "一名", "entity": "O" }, { "word": "学生", "entity": "O" }, { "word": "在", "entity": "O" }, { "word": "霍格沃茨", "entity": "B-LOC" } ]}在我看来,没有什么可以代替人类的评估,但使用GPT模型为我们提供一个起点可能是一个巨大的优势。
结论
标记数据始终是困难的,有时,即使获得起点也是一个巨大的优势。在本博客中,我们展示了如何使用OpenAI的GPT模型生成数据预测,作为数据标记工作流的起点。这个过程可以显著减少人力投入,并将标记者的注意力集中在为他们的努力提供更多价值上。请查看有关本博客中介绍的主题的更多信息的资源。
资源
完整的示例笔记本电脑-笔记本电脑,所有代码都已准备好在Colab中运行
Label Studio-开源数据标记工具
OpenAI定价页面-本文中的定价估计详情