解读美国参议院关于AI监管的听证会:Python中的自然语言处理分析
使用 NLTK 工具包进行词频分析、可视化和情感评分
上个星期天早上,我在吃早餐的时候不停地换电视频道,试图找到一些可以看的东西,无意中发现了一场有关 AI 监督的参议院听证会的重播。它才刚刚开始 40 分钟,所以我决定看完剩下的部分(说实话这是一个有趣的星期天早晨的活动!)。
当像参议院司法小组委员会对 AI 的监督这样的活动举行时,如果你想了解关键要点,你有四个选择:现场观看,寻找未来的录音(这两个选项都需要三个小时的时间);阅读书面版本(记录),其长度约为 79 页,超过 29000 个单词;或者阅读网站或社交媒体上的评论,以获取不同的意见并形成自己的意见(如果不是来自他人的话)。
现在,随着一切都变得如此迅速,我们的日子感觉太短,很容易选择捷径,依赖评论而不是查看原始资料(我也曾经这样做过)。如果你选择捷径来了解这场听证会,很可能大多数你在网上或社交媒体上找到的评论都会集中在 OpenAI CEO Sam Altman 呼吁监管 AI 上。然而,在观看了听证会后,我觉得除了头条新闻之外还有更多可以探索的。
因此,在度过了充满乐趣的星期天早上活动之后,我决定下载参议院听证会记录,并使用 NLTK Package(Python 自然语言处理包)进行分析,比较最常用的单词,对不同利益群体(OpenAI、IBM、学术界、国会)应用一些情感评分,看看文本之间可能存在的联系。剧透!在分析的 29000 个单词中,仅有 70 个(0.24%)与监管、调控、法规或立法等相关的词汇有关。
需要注意的是,本文并不是关于我对这场 AI 听证会或 ChatGPT 的 Sam Altman 的看法。相反,它着重于探讨在国会山范围内代表社会各部分(私人机构、学术界、政府)的每个人所说的话语之下的深层含义,以及我们可以从这些话语中混合在一起的内容中学到什么。
考虑到未来几个月对人工智能监管的未来是有趣的时刻,因为欧盟 AI 法案的最终草案正在等待欧洲议会的辩论(预计将于 6 月举行),因此值得探索大西洋这一侧围绕 AI 的讨论背后的内容。
步骤 01:获取数据
我使用了 Justin Hendrix 在 Tech Policy Press 上发布的记录(可在此处访问)。

虽然 Hendrix 提到这是一份快速记录,并建议通过观看参议院听证会视频来确认引用,但我认为它对于这次分析来说相当准确和有趣。如果你想观看参议院听证会或阅读 Sam Altman(Open AI)、Christina Montgomery(IBM)和 Gary Marcus(纽约大学教授)的证言,可以在这里找到它们。
最初,我计划将记录复制到 Word 文档中,并手动在 Excel 中创建一个包含参与者姓名、其代表组织和评论的表格。然而,这种方法耗时且效率低下。因此,我转向 Python,并从 Microsoft Word 文件中将完整记录上传到数据框中。以下是我使用的代码:
# 步骤 01-读取 Word 文档# 记得安装 pip install python-docximport docximport pandas as pddoc = docx.Document('D:\....your word file on microsoft word')items = []names = []comments = []# 迭代段落 for paragraph in doc.paragraphs: text = paragraph.text.strip() if text.endswith(':'): name = text[:-1] else: items.append(len(items)) names.append(name) comments.append(text)dfsenate = pd.DataFrame({'item': items, 'name': names, 'comment': comments})# 删除空评论所在行dfsenate = dfsenate[dfsenate['comment'].str.strip().astype(bool)]# 重置索引dfsenate.reset_index(drop=True, inplace=True)dfsenate['item'] = dfsenate.index + 1print(dfsenate)输出结果应该如下:
项名称 评论0 1 参议员理查德·布卢门撒尔(D-CT)现在进行一些介绍性的讲话。1 2 参议员理查德·布卢门撒尔(D-CT)“我们太经常看到技术超越监管带来的后果,个人数据的无节制利用,虚假信息的泛滥以及社会不平等的加深。我们已经看到算法偏见如何持续歧视和偏见,以及透明度的缺乏如何破坏公众信任。这不是我们想要的未来。”2 3 参议员理查德·布卢门撒尔(D-CT)如果你在家听,你可能会认为那个声音是我的,话语是我的,但实际上,那个声音不是我的。话也不是我的。这个音频是一个AI语音克隆软件在我的演讲中进行过训练的结果。这篇讲话是由ChatGPT编写的,当被问到我将如何开始这场听证会时,它就写下了这篇讲话。你刚才听到的就是ChatGPT的回答。我问ChatGPT,你为什么选择那些主题和内容?它回答说:“布卢门撒尔在倡导消费者保护和民权方面有很强的记录。他对数据隐私和算法决策中的歧视潜在问题非常关注。因此,该声明强调了这些方面。”3 4 参议员理查德·布卢门撒尔(D-CT)阿尔特曼先生,我很感激ChatGPT的支持。说真的,这种推理方式非常令人印象深刻。我敢肯定,十年后我们会像看待第一部手机那样看待ChatGPT和GPT-4,那些我们曾经携带的大而笨重的东西。但我们意识到,我们正处于一个新时代的边缘。这个音频和我的演奏,可能会让你感到好奇或有趣,但在我的脑海中回响的是,如果我问了它,如果它支持乌克兰、投降或弗拉基米尔·普京的领导,那将是非常可怕的。这个前景不仅仅有点可怕,正如您自己所用的词语,阿尔特曼先生,我认为您在引起注意这些陷阱和承诺方面非常有建设性。4 5 参议员理查德·布卢门撒尔(D-CT)这也是我们今天想要你来这里的原因。我们感谢你和其他证人加入我们几个月。现在,公众对GPT,dally和其他AI工具感到着迷。这些示例,例如由ChatGPT完成的作业或其编写的文章和专栏,感觉就像新奇玩具。但是这个时代的潜在进步不仅仅是研究实验。它们不再是科幻小说的幻想。它们是真实的,呈现出治愈癌症或开发新的物理和生物学理解或建模气候和天气的承诺。这一切都非常令人鼓舞和充满希望。但我们也知道潜在的危害,我们已经看到它们被武器化的虚假信息、住房歧视、骚扰妇女和模拟、欺诈、语音克隆深度伪造。尽管存在其他回报,但这些都是潜在的风险。对我来说,也许最大的噩梦是即将到来的新工业革命。数百万工人的被替代,大量就业机会的流失,需要为这个新工业革命做技能培训和重新安置的准备。而且,行业领袖已经在呼吁应对这些挑战。5 6 参议员理查德·布卢门撒尔(D-CT)引用ChatGPT的话,这不一定是我们想要的未来。我们需要最大限度地发挥好处。国会有选择。现在。当我们面对社交媒体时,我们也有同样的选择。我们未能抓住那个时刻。结果是互联网上的捕食者、利用儿童的有毒内容,为他们创造危险。参议员布莱克本、我和其他人,如司法委员会的杜宾参议员,正在试图通过《儿童在线安全法案》来解决这个问题。但是,国会在社交媒体方面没有抓住时机。现在,我们有义务在AI方面做到这一点,以免威胁和风险成为现实。明智的保障措施并不与创新相对立。问责制不是负担,而是我们如何在保护公众信任的同时前进的基础。它们是我们如何在技术和科学方面领导世界,同时也是如何促进我们的民主价值观的基础。6 7 参议员理查德·布卢门撒尔(D-CT)否则,在缺乏这种信任的情况下,我认为我们可能会失去两者。这些都是复杂的技术,但我们的法律中有基本的期望。我们可以从透明度开始。AI公司应该被要求测试他们的系统,披露已知的风险,并允许独立的研究人员进入。我们可以建立得分卡和营养标签,鼓励基于安全和信任的竞争,限制使用。AI的风险如此之大,以至于我们应该限制甚至禁止它们的使用,特别是当涉及商业侵犯隐私以谋取利润和影响人们生计的决策时。当AI公司及其客户造成伤害时,他们应该承担责任。我们不应该重复过去的错误,例如第230节,迫使公司提前考虑并对其业务决策的后果负责可以是最有力的工具。垃圾进,垃圾出。这个原则仍然适用。无论是进入这些平台还是从中出来的垃圾,我们都应该警惕。接下来,我考虑添加一些标签,以便于未来的分析,通过识别个体所代表的社会部分来确定他们的身份。
def assign_sector(name): if name in ['Sam Altman', 'Christina Montgomery']: return '私营' elif name == 'Gary Marcus': return '学术界' else: return '国会'# 应用函数 dfsenate['sector'] = dfsenate['name'].apply(assign_sector)# 根据姓名分配组织def assign_organization(name): if name == 'Sam Altman': return 'OpenAI' elif name == 'Christina Montgomery': return 'IBM' elif name == 'Gary Marcus': return '学术界' else: return '国会'# 应用函数dfsenate['Organization'] = dfsenate['name'].apply(assign_organization)print(dfsenate)最后,我决定添加一列来计算每个声明的单词数,这也有助于我们进行进一步的分析。
dfsenate['WordCount'] = dfsenate['comment'].apply(lambda x: len(x.split()))此时,您的数据框应该像这样:
item name ... Organization WordCount0 1 Sen. Richard Blumenthal (D-CT) ... 国会 51 2 Sen. Richard Blumenthal (D-CT) ... 国会 552 3 Sen. Richard Blumenthal (D-CT) ... 国会 1253 4 Sen. Richard Blumenthal (D-CT) ... 国会 1454 5 Sen. Richard Blumenthal (D-CT) ... 国会 197.. ... ... ... ... ...399 400 Sen. Cory Booker (D-NJ) ... 国会 156400 401 Sam Altman ... OpenAI 180401 402 Sen. Cory Booker (D-NJ) ... 国会 72402 403 Sen. Richard Blumenthal (D-CT) ... 国会 154403 404 Sen. Richard Blumenthal (D-CT) ... 国会 98步骤二:可视化数据
让我们来看一下我们目前拥有的数字:404个问题或证言,近29,000个单词。这些数字为我们开始提供了材料。需要知道的是,有些声明被分成了更小的部分。当有长篇声明带有不同段落时,代码将它们分成单独的声明,即使它们实际上是一个贡献的一部分。为了更好地了解每个参与者的参与程度,我还考虑了他们使用的单词数。这提供了另一种参与角度。
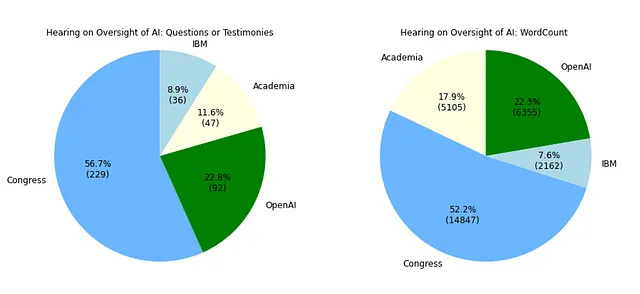
如图01所示,国会成员的干预超过了所有听证会的一半,其次是Sam Altman的证言。然而,通过计算每一方的单词数获得的备选视图显示了国会(11名成员)和由Altman(OpenAI)、Montgomery(IBM)和Marcus(学术界)组成的小组之间更平衡的代表。
有趣的是,要注意参加参议院听证会的国会成员之间不同的参与程度(请参阅下表)。正如预期的那样,作为小组委员会主席的布卢门撒尔参议员非常积极。但其他成员呢?表格显示了所有11位参与者参与程度的显着差异。请记住,贡献的数量不一定表示质量。在您审查数字时,我让您自己做出判断。
最后,即使Sam Altman受到了很多关注,也值得注意的是,尽管可能出现他参与机会较少的情况,但是Gary Marcus的发言很多,他的单词数与Altman的相似。或者是因为学术界通常提供详细的解释,而商业界更喜欢实用性和简明性?
好的,马库斯教授,如果您能具体说明一下。这是您的机会,讲清楚,告诉我我们应该实施哪些规则。而且请不要只用概念。我正在寻找具体性。
参议员约翰·肯尼迪(路易斯安那州共和党人)。美国参议院监管人工智能听证会(2023年)
#*****************************饼图************************************import pandas as pdimport matplotlib.pyplot as plt# 按照“组织”分类的饼图(问题和证言)org_colors = {'国会': '#6BB6FF', 'OpenAI': '绿色', 'IBM': '浅蓝色', '学术界': '浅黄色'}org_counts = dfsenate['Organization'].value_counts()plt.figure(figsize=(8, 6))patches, text, autotext = plt.pie(org_counts.values, labels=org_counts.index, autopct=lambda p: f'{p:.1f}%\n({int(p * sum(org_counts.values) / 100)})', startangle=90, colors=[org_colors.get(org, '灰色') for org in org_counts.index])plt.title('监督人工智能听证会:问题或证言')plt.axis('equal')plt.setp(text, fontsize=12)plt.setp(autotext, fontsize=12)plt.show()# 按照“组织”分类的饼图(单词计数)org_colors = {'国会': '#6BB6FF', 'OpenAI': '绿色', 'IBM': '浅蓝色', '学术界': '浅黄色'}org_wordcount = dfsenate.groupby('Organization')['WordCount'].sum()plt.figure(figsize=(8, 6))patches, text, autotext = plt.pie(org_wordcount.values, labels=org_wordcount.index, autopct=lambda p: f'{p:.1f}%\n({int(p * sum(org_wordcount.values) / 100)})', startangle=90, colors=[org_colors.get(org, '灰色') for org in org_wordcount.index])plt.title('监督人工智能听证会:单词计数')plt.axis('equal')plt.setp(text, fontsize=12)plt.setp(autotext, fontsize=12)plt.show()#************国会议员之间的互动**********************# 按名称分组并计算行数Summary_Name = dfsenate.groupby('姓名').agg(comment_count=('评论', 'size')).reset_index()# 每个名称的单词计数列Summary_Name ['总字数'] = dfsenate.groupby('姓名')['WordCount'].sum().values# 评论计数的百分比分布Summary_Name ['评论计数_%'] = Summary_Name['comment_count'] / Summary_Name['comment_count'].sum() * 100# 总字数百分比分布Summary_Name ['单词计数_%'] = Summary_Name['总字数'] / Summary_Name['总字数'].sum() * 100Summary_Name = Summary_Name.sort_values('总字数', ascending=False)print (Summary_Name)+-------+--------------------------------+---------------+-------------+-----------------+--------------+| index | 姓名 | 介入次数 | 总字数 | 介入_% | 单词计数_% |+-------+--------------------------------+---------------+-------------+-----------------+--------------+| 2 | Sam Altman | 92 | 6355 | 22.77227723 | 22.32252626 || 1 | Gary Marcus | 47 | 5105 | 11.63366337 | 17.93178545 || 15 | Sen. Richard Blumenthal (D-CT) | 58 | 3283 | 14.35643564 | 11.53184165 || 10 | Sen. Josh Hawley (R-MO) | 25 | 2283 | 6.188118812 | 8.019249008 || 0 | Christina Montgomery | 36 | 2162 | 8.910891089 | 7.594225298 || 6 | Sen. Cory Booker (D-NJ) | 20 | 1688 | 4.95049505 | 5.929256384 || 7 | Sen. Dick Durbin (D-IL) | 8 | 1143 | 1.98019802 | 4.014893393 || 11 | Sen. Lindsey Graham (R-SC) | 32 | 880 | 7.920792079 | 3.091081527 || 5 | Sen. Christopher Coons (D-CT) | 6 | 869 | 1.485148515 | 3.052443008 || 12 | Sen. Marsha Blackburn (R-TN) | 14 | 869 | 3.465346535 | 3.052443008 || 4 | Sen. Amy Klobuchar (D-MN) | 11 | 769 | 2.722772277 | 2.701183744 || 13 | Sen. Mazie Hirono (D-HI) | 7 | 755 | 1.732673267 | 2.652007447 || 14 | Sen. Peter Welch (D-VT) | 11 | 704 | 2.722772277 | 2.472865222 || 3 | Sen. Alex Padilla (D-CA) | 7 | 656 | 1.732673267 | 2.304260775 |+-------+--------------------------------+---------------+-------------+-----------------+--------------+步骤三:分词
这里是自然语言处理(NLP)的乐趣之所在。为了分析文本,我们将使用Python中的NLTK包。它提供了有用的工具,用于单词频率分析和可视化。以下库和模块将提供单词频率分析和可视化所需的必要工具。
#pip install nltk#pip install spacy#pip install wordcloud#pip install subprocess#python -m spacy download en首先,我们将从分词开始,这意味着将文本分成单个单词,也称为“标记”。为此,我们将使用spaCy,这是一个开源的NLP库,可以处理缩写词、标点符号和特殊字符。接下来,我们将使用NLTK库中的停用词资源删除不添加太多含义的常见单词,例如“a”、“an”、“the”、“is”和“and”。最后,我们将应用词形还原,将单词缩减为它们的基本形式,也称为词形还原。例如,“running”变成“run”,“happier”变成“happy”。这种技术帮助我们更有效地处理文本,并理解其含义。
总之:
o 对文本进行分词。
o 删除常用词。
o 应用词形还原。
#***************************WORD-FRECUENCY*******************************import subprocessimport nltkimport spacyfrom nltk.probability import FreqDistfrom nltk.corpus import stopwords# Download resourcessubprocess.run('python -m spacy download en', shell=True)nltk.download('punkt')# Load spaCy model and set stopwordsnlp = spacy.load('en_core_web_sm')stop_words = set(stopwords.words('english'))def preprocess_text(text): words = nltk.word_tokenize(text) words = [word.lower() for word in words if word.isalpha()] words = [word for word in words if word not in stop_words] lemmas = [token.lemma_ for token in nlp(" ".join(words))] return lemmas# Aggregate words and create Frecuency Distributionall_comments = ' '.join(dfsenate['comment'])processed_comments = preprocess_text(all_comments)fdist = FreqDist(processed_comments)#**********************HEARING TOP 30 COMMON WORDS*********************import matplotlib.pyplot as pltimport numpy as np# Most common words and their frequenciestop_words = fdist.most_common(30)words = [word for word, freq in top_words]frequencies = [freq for word, freq in top_words]# Bar plot-Hearing on Oversight of AI:Top 30 Most Common Wordsfig, ax = plt.subplots(figsize=(8, 10))ax.barh(range(len(words)), frequencies, align='center', color='skyblue')ax.invert_yaxis()ax.set_xlabel('Frequency', fontsize=12)ax.set_ylabel('Words', fontsize=12)ax.set_title('Hearing on Oversight of AI:Top 30 Most Common Words', fontsize=14)ax.set_yticks(range(len(words)))ax.set_yticklabels(words, fontsize=10)ax.spines['right'].set_visible(False)ax.spines['top'].set_visible(False)ax.spines['left'].set_linewidth(0.5)ax.spines['bottom'].set_linewidth(0.5)ax.tick_params(axis='x', labelsize=10)plt.subplots_adjust(left=0.3)for i, freq in enumerate(frequencies): ax.text(freq + 5, i, str(freq), va='center', fontsize=8)plt.show()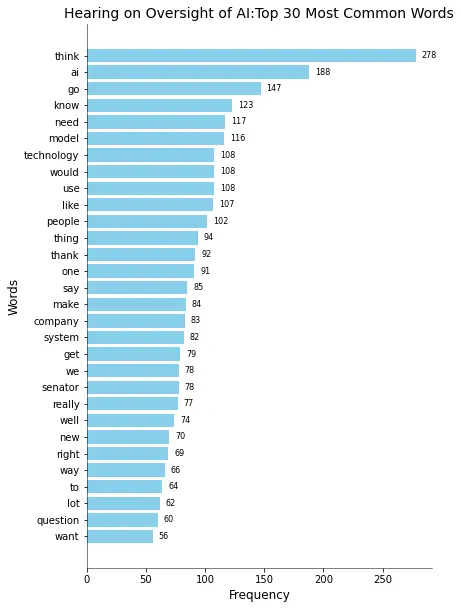
正如您在柱状图(图2)中看到的那样,有很多人在“思考”。也许前五个单词给了我们有关今天和未来在AI方面应该做什么的有趣提示:
“我们需要思考并知道AI应该走向何方”。
正如我在本文开头提到的那样,“规制”乍一看并不是参议院AI听证会上经常使用的单词。但是,得出它不是主要关注的话题的结论可能是不准确的。AI是否应该受到规制的兴趣用不同的词表达,例如“规制”、“调整”、“机构”或“监管”。因此,让我们对代码进行一些调整,汇总这些单词,并重新运行柱状图,以查看它对分析的影响。
nlp = spacy.load('en_core_web_sm')
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
words = nltk.word_tokenize(text)
words = [word.lower() for word in words if word.isalpha()]
words = [word for word in words if word not in stop_words]
lemmas = [token.lemma_ for token in nlp(" ".join(words))]
return lemmas
# 合并单词并创建频率分布
all_comments = ' '.join(dfsenate['comment'])
processed_comments = preprocess_text(all_comments)
fdist = FreqDist(processed_comments)
original_fdist = fdist.copy() # 保存原始对象
aggregate_words = ['regulation', 'regulate','agency', 'regulatory','legislation']
aggregate_freq = sum(fdist[word] for word in aggregate_words)
df_aggregatereg = pd.DataFrame({'Word': aggregate_words, 'Frequency': [fdist[word] for word in aggregate_words]})
# 删除个别单词并添加聚合
for word in aggregate_words:
del fdist[word]
fdist['regulation+agency'] = aggregate_freq
# Regulation+agency分布饼图
import matplotlib.pyplot as plt
labels = df_aggregatereg['Word']
values = df_aggregatereg['Frequency']
plt.figure(figsize=(8, 6))
plt.subplots_adjust(top=0.8, bottom=0.25)
patches, text, autotext = plt.pie(values, labels=labels,
autopct=lambda p: f'{p:.1f}%\n({int(p * sum(values) / 100)})',
startangle=90, colors=['#6BB6FF', 'green', 'lightblue', 'lightyellow', 'gray'])
plt.title('Regulation+agency: 分布', fontsize=14)
plt.axis('equal')
plt.setp(text, fontsize=8)
plt.setp(autotext, fontsize=8)
plt.show()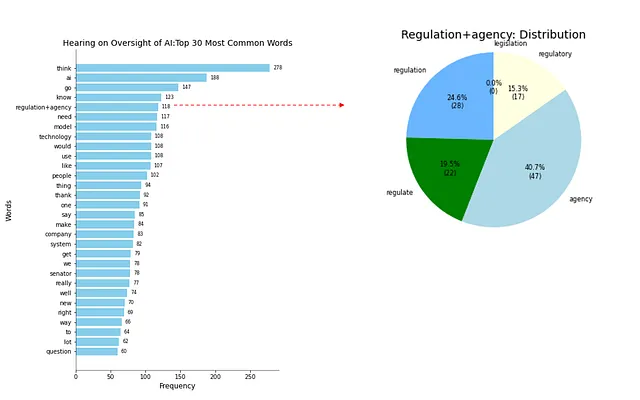
如图03所示,在参议院AI听证会期间,监管话题多次被提及。
步骤04:言之有物
仅凭单词可能为我们提供一些线索,但是单词之间的相互联系才真正为我们提供了一些视角。因此,让我们采用词云的方法,探索是否可以发现简单的条形图和饼图无法展示的见解。
# 参议院AI听证会的词云
from wordcloud import WordCloud
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(fdist)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('词云-参议院AI听证会')
plt.show()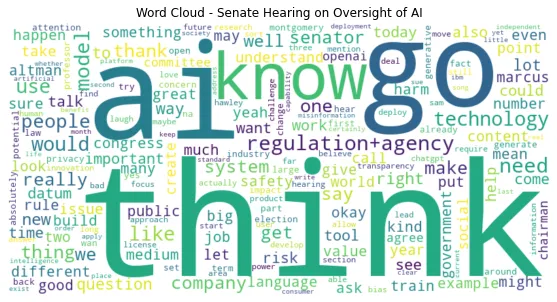
让我们进一步探索并比较代表AI听证会中不同利益集团的词云(私营企业、国会、学术界),看看它们揭示了未来AI的不同视角。
# 每个利益集团的词云
organizations = dfsenate['Organization'].unique()
for organization in organizations:
comments = dfsenate[dfsenate['Organization'] == organization]['comment']
all_comments = ' '.join(comments)
processed_comments = preprocess_text(all_comments)
fdist_organization = FreqDist(processed_comments)
# 词云
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(fdist_organization)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
if organization == 'IBM':
plt.title(f'词云:{organization} - Christina Montgomery')
elif organization == 'OpenAI':
plt.title(f'词云:{organization} - Sam Altman')
elif organization == 'Academia':
plt.title(f'词云:{organization} - Gary Marcus')
else:
plt.title(f'词云:{organization}')
plt.show()
有趣的是,当参议院AI听证会代表不同的利益集团谈论人工智能时,有些词会出现或消失。
在大标题方面,“Sam Altman呼吁监管AI”;嗯,他是否赞成监管我不太清楚,但在我的想法里,他似乎并没有在言辞上强调监管。相反,Sam Altman在谈到人工智能时似乎更注重以人为本,反复使用“思考”、“人”、“知道”、“重要”和“使用”等词,而不是使用“技术”、“系统”或“模型”等词语,而不是使用“AI”这个词。
在谈到“风险”和“问题”时,Christina Montgomery(IBM)不断重复这些词,同时谈论“技术”、“公司”和“AI”。在她的证词中,一个有趣的事实是,她说的话大多是人们期望从开发技术的公司中听到的;如“信任”、“治理”和“认为”在AI方面的“正确”之类的词语。
“我们需要让公司对他们部署的AI负责并承担责任…..“
克里斯蒂娜·蒙哥马利。 AI监管听证会(2023年)
在他的最初陈述中,Gary Marcus说:“我是一位科学家,是一位创立了AI公司并真正热爱AI的人……”,因此,为了这个NLP分析的缘故,我们将他视为学术界的代表。与其他词语相比,“需要”、“思考”、“知道”、“去”和“人”等词语更为突出。有趣的是,在他的证言中,“系统”这个词似乎比“AI”这个词重复了更多次。也许AI不是将改变未来的单一技术,未来的影响将来自多种技术或系统相互作用(物联网,机器人技术,生物技术等),而不仅仅是依靠其中一种。
最后,参议员约翰·肯尼迪提出的第一个假设似乎并不完全错误(不仅仅适用于国会,而是适用于整个社会)。我们仍处于试图了解AI走向的阶段。
“请允许我与您分享三个假设,假设一,许多国会成员不了解人工智能。假设二,这种缺乏理解可能不会阻止国会充满热情地试图以可能伤害该技术的方式来监管这项技术。假设三,我希望您假设,人工智能社区可能有一个疯狂的派别,有意或无意地可能使用人工智能来杀害我们所有人并在我们 st的整个时间内伤害我们…..“
参议员约翰·肯尼迪(R-LA)。 AI监管听证会(2023年)
步骤05:你话语背后的情感
我们将使用NLTK库的SentimentIntensityAnalyzer类进行情感分析。这个预先训练的模型使用基于字典的方法,其中字典(VADER)中的每个单词都有预定义的情感极性值。文本中单词的情感分数被聚合以计算整体情感分数。数值范围从-1(负面情感)到+1(正面情感),0表示中性情感。积极情感反映出一种良好的情感、态度或热情,而消极情感则传达出一种不良的情感或态度。
#************情感分析************from nltk.sentiment import SentimentIntensityAnalyzernltk.download('vader_lexicon')sid = SentimentIntensityAnalyzer()dfsenate['Sentiment'] = dfsenate['comment'].apply(lambda x: sid.polarity_scores(x)['compound'])#************箱线图-利益组************import seaborn as snsimport matplotlib.pyplot as pltsns.set_style('white')plt.figure(figsize=(12, 7))sns.boxplot(x='Sentiment', y='Organization', data=dfsenate, color='yellow', width=0.6, showmeans=True, showfliers=True)# 自定义轴线 def add_cosmetics(title='利益组情感分析分布', xlabel='情感'): plt.title(title, fontsize=28) plt.xlabel(xlabel, fontsize=20) plt.xticks(fontsize=15) plt.yticks(fontsize=15) sns.despine()def customize_labels(label): if "OpenAI" in label: return label + "-Sam Altman" elif "IBM" in label: return label + "-Christina Montgomery" elif "Academia" in label: return label + "-Gary Marcus" else: return label# 将自定义标签应用于y轴yticks = plt.yticks()[1]plt.yticks(ticks=plt.yticks()[0], labels=[customize_labels(label.get_text()) for label in yticks])add_cosmetics()plt.show()
箱线图总是很有趣,因为它显示最小值、最大值、中位数、第一(Q1)和第三(Q3)四分位数。此外,添加了一行代码来显示平均值。(感谢Elena Kosourova设计箱线图代码模板;我只是针对我的数据集进行了调整)。
总的来说,在参议院听证会期间,每个人的情绪都很好,特别是Sam Altman,他的情感得分最高,其次是Christina Montgomery。另一方面,Gary Marcus似乎有着更为中性的体验(中位数约为0.25),他可能在某些时候感到有些不舒服,情感值接近0甚至为负值。此外,整个国会在情感得分上显示出左偏分布,表明倾向于中立或积极。有趣的是,如果我们仔细观察,某些干预措施的情感得分非常高或非常低。
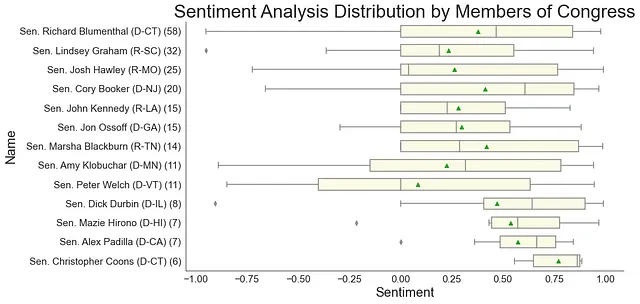
也许我们不应该将结果解释为参议院AI听证会中的人们是快乐的还是不舒服的。也许这表明参加听证会的人可能并不对AI的前景持有过于乐观的看法,但同时他们也不悲观。这些得分可能表明存在一些担忧,并且对AI应该走向持谨慎态度。
那时间轴呢?听证会期间的情绪是否保持不变?每个利益组的情绪如何演变?为了分析时间轴,我按照捕获语句的顺序组织了语句,并进行了情感分析。由于有400多个问题或证言,我为每个利益组定义了一个情感得分的移动平均值(国会、学术界、私营部门),使用窗口大小为10。这意味着通过对每10个连续语句的情感得分进行平均值计算来计算移动平均值:
#**************************时间轴-美国参议院人工智能听证会**************************************import seaborn as snsimport matplotlib.pyplot as pltimport numpy as npfrom scipy.interpolate import make_interp_spline# 每个组织的移动平均值window_size = 10 organizations = dfsenate['Organization'].unique()# 创建线图color_palette = sns.color_palette('Set2', len(organizations))plt.figure(figsize=(12, 6))for i, org in enumerate(organizations): df_org = dfsenate[dfsenate['Organization'] == org] # 移动平均值 df_org['Sentiment'].fillna(0, inplace=True) # 缺失值填充为0 df_org['Moving_Average'] = df_org['Sentiment'].rolling(window=window_size, min_periods=1).mean() x = np.linspace(df_org.index.min(), df_org.index.max(), 500) spl = make_interp_spline(df_org.index, df_org['Moving_Average'], k=3) y = spl(x) plt.plot(x, y, linewidth=2, label=f'{org} {window_size}-点移动平均值', color=color_palette[i])plt.xlabel('语句编号', fontsize=12)plt.ylabel('情感得分', fontsize=12)plt.title('AI监管听证会期间情感得分的演变', fontsize=16)plt.legend(fontsize=12)plt.grid(color='lightgray', linestyle='--', linewidth=0.5)plt.axhline(0, color='black', linewidth=0.5, alpha=0.5)for org in organizations: df_org = dfsenate[dfsenate['Organization'] == org] plt.text(df_org.index[-1], df_org['Moving_Average'].iloc[-1], f'{df_org["Moving_Average"].iloc[-1]:.2f}', ha='right', va='top', fontsize=12, color='black')plt.tight_layout()plt.show()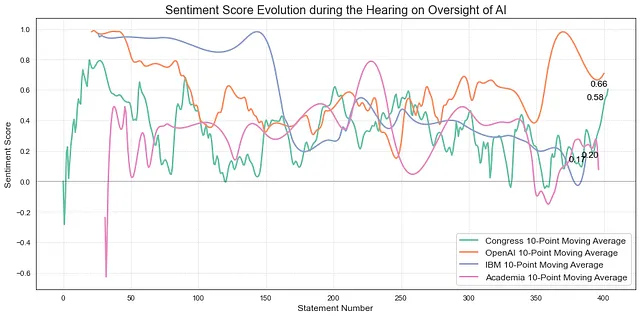
起初,听证会似乎友好而乐观,所有人都在讨论人工智能的未来。但随着听证会的进行,情绪开始变化。国会成员的乐观程度降低了,他们的问题变得更加具有挑战性。这影响了小组成员的得分,甚至有些人得到了低分(你可以在听证会结束时看到这一点)。有趣的是,即使在与国会成员紧张的时刻,模型也认为Altman是中立或略微积极的。
重要的是要记住,模型有其局限性,可能存在主观性。尽管情感分析并不完美,但它为我们提供了一个有趣的视角,窥见了那一天在国会山上情感的强度。
最后一点想法
在我看来,这次美国参议院人工智能听证会背后的教训在于五个最重复的词:“我们需要思考和了解人工智能应该走向何方”。值得注意的是,像“人们”和“重要性”这样的词出现在了Sam Altman的词云中,超出了“呼吁监管”的标题。虽然我希望在Altman的NLP分析中能够找到更多像“透明度”、“问责”、“信任”、“治理”和“公平性”这样的词,但在Christina Montgomery的证言中经常重复一些词令人松了一口气。这是我们所有人在人工智能讨论时都希望更频繁听到的。
Gary Marcus强调“系统”和“人工智能”,可能邀请我们从更广阔的背景下看待人工智能。现在有多种技术正在兴起,它们的综合影响将来自这些多种技术的冲突,而不仅仅来自其中的一种。学术界在引导这条道路方面发挥着至关重要的作用,如果需要某种形式的监管,那么它们也同样重要。我说这句话是“字面意义上”的,而不是“精神上”的(六个月的Moratorium信中的一个内部玩笑)。
最后,“机构”这个词与“监管”在其不同形式中被重复提到。这表明,未来不久的时间内,“AI机构”这个概念及其角色可能会成为讨论的话题。参议员Richard Blumenthal在参议院AI听证会上提到了关于这一挑战的有趣思考:
“ … 我的职业生涯大部分时间都是执法。我告诉你们,你们可以创建10个新机构,但如果你们不给他们资源,我说的不仅仅是资金,我说的是科学专业知识,你们会围着他们转。这不仅仅是模型或生成AI将在模型周围运行,而是你们公司中的科学家。对于政府监管的每一个成功案例,你可以想到五个失败案例……我希望我们在这里的经历会有所不同……“
Richard Blumenthal参议员(康涅狄格州民主党)。美国参议院AI监督听证会(2023)
尽管对我来说,协调创新、意识和监管是具有挑战性的,但我全力支持提高人们对人工智能在我们现在和未来中的作用的认识,但也要理解“研究”和“开发”是不同的事情。应该鼓励和推广前者,而不是限制,而后者需要投入更多的“思考”和“了解”。
我希望您觉得这个NLP分析有趣,并感谢Justin Hendrix和Tech Policy Press允许我在本文中使用他们的转录。您可以在此GitHub存储库中访问完整的代码。 (感谢ChatGPT帮助我优化了一些代码以获得更好的呈现效果)。
我有遗漏什么吗?欢迎您提出建议,让我们继续交流。