如何优化SQL查询以实现更快的数据检索
今天,我们将讨论为什么SQL查询优化很重要,以及可以使用哪些技术来进行优化

SQL(结构化查询语言)如你所知,可以帮助你从数据库中收集数据。
它是专为此而设计的。换句话说,它使用行和列,允许您使用SQL查询操作数据库中的数据。
什么是SQL查询?
SQL查询是一堆指令,您可以用它们向数据库收集信息。
您可以使用这些查询收集和操作数据库中的数据。
通过使用它们,您可以创建报告,执行数据分析等操作。
由于这些查询的形式和长度,执行时间可能会很长,特别是在处理较大的数据表时。
为什么需要SQL查询优化?
SQL查询优化的目的是确保您有效地使用资源。简单地说,它可以减少执行时间,节省成本并提高性能。这是开发人员和数据分析师的重要技能。重要的不仅是从数据库返回正确的数据,还需要知道如何有效地执行。
您应该始终问自己:“是否有更好的编写查询的方法?”
让我们更深入地探讨一下原因。
资源效率:优化不佳的SQL查询会消耗过多的系统资源,例如CPU和内存。这可能会导致整体系统性能降低。优化SQL查询可确保有效使用这些资源。这反过来会导致更好的性能和可扩展性。
减少执行时间:如果查询运行缓慢,这将对用户体验产生负面影响。如果您有正在运行的应用程序,则会影响应用程序性能。优化查询可以帮助减少执行时间,提供更快的响应时间和更好的用户体验。
成本节约:优化查询可以减少支持数据库系统所需的硬件和基础架构。这可以在硬件,能源和维护成本方面节省成本。
请查看“编写SQL查询的最佳实践”,即使您的代码是正确的,也可以帮助您了解如何改进代码结构。
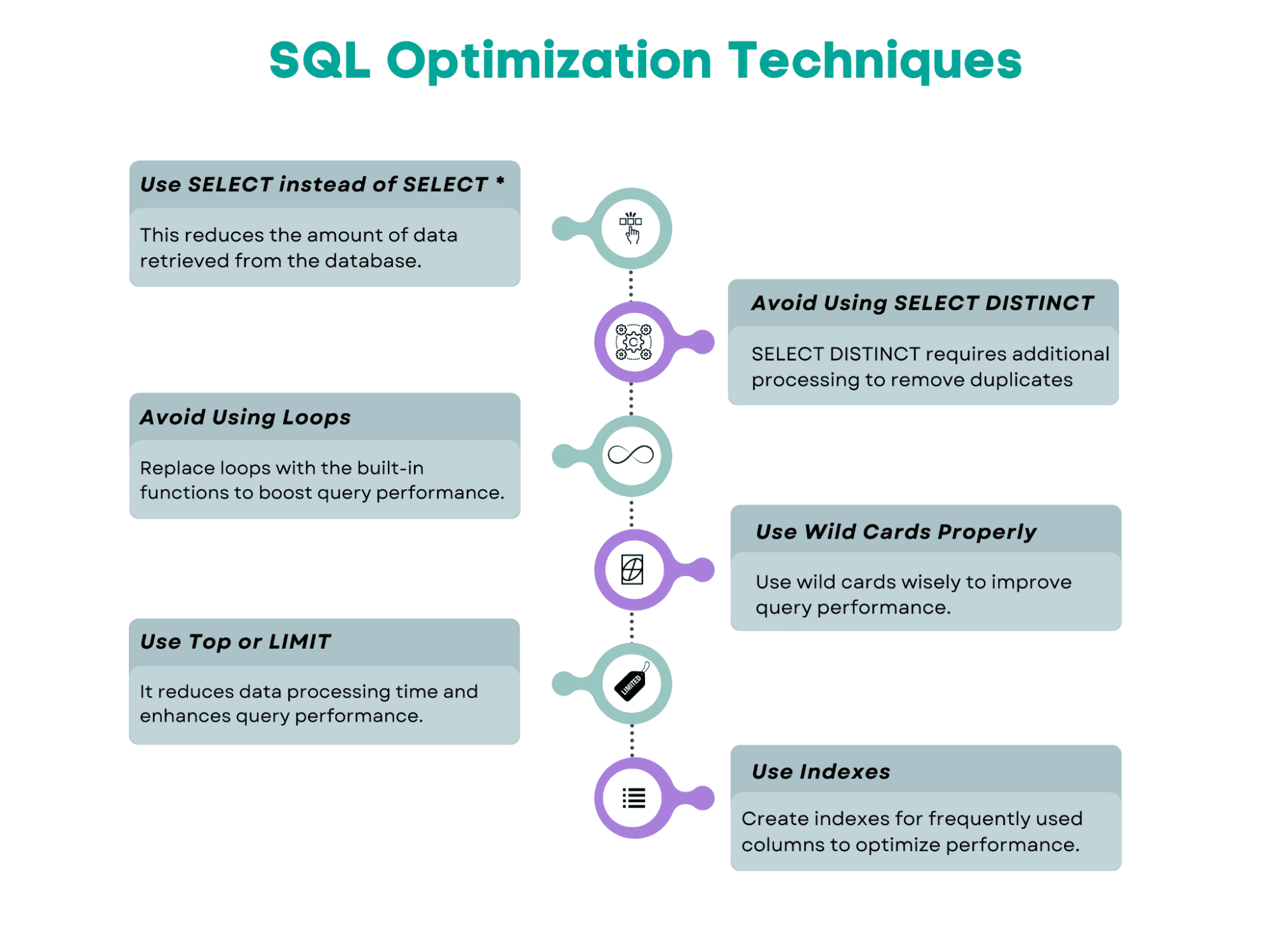
SQL查询优化技术
以下是本文将涵盖的SQL查询优化技术的概述。
这是显示在优化SQL查询时建议遵循的步骤的流程图。我们将在示例中遵循相同的方法。值得注意的是,优化工具也可以帮助改善查询性能。因此,让我们从众所周知的SQL命令SELECT开始探索这些技术。 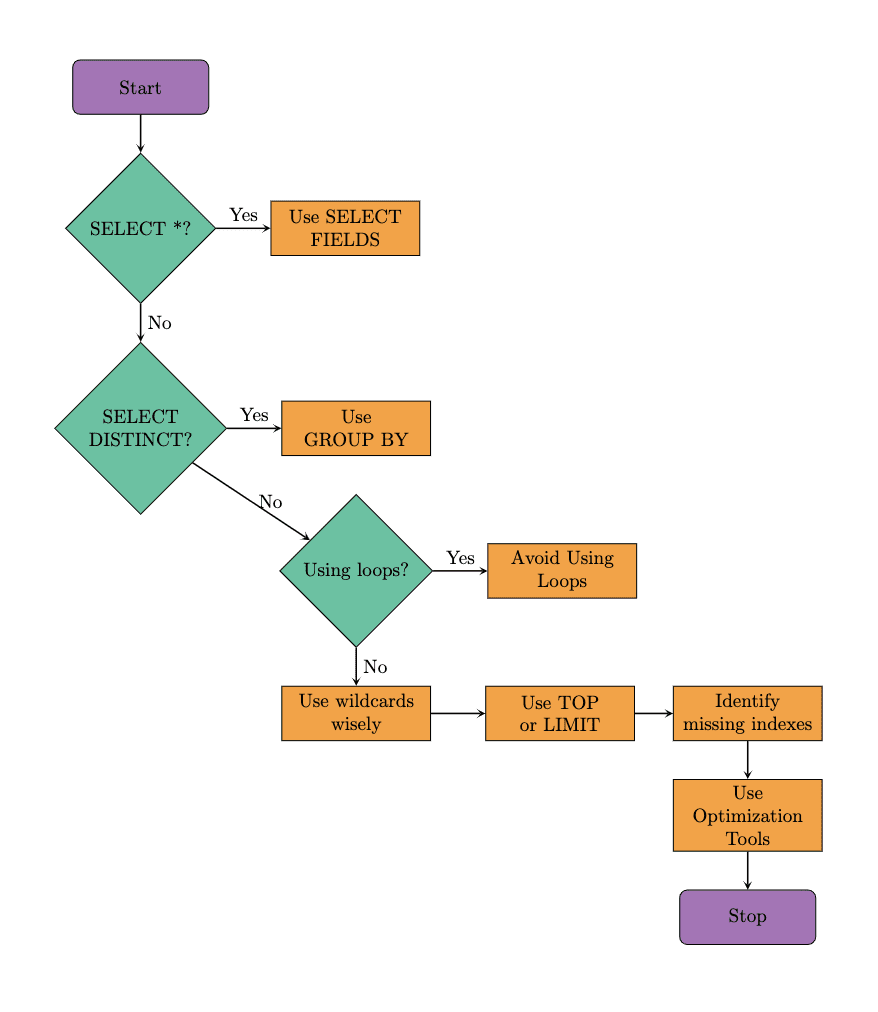
使用指定字段的SELECT而不是SELECT *
当您使用SELECT *时,它将返回表中所有行和所有列。您需要问自己是否真的需要它。
请在SELECT之后使用特定字段,而不是扫描整个数据库。
在示例中,我们将使用特定的列名称替换SELECT *。如您所见,这将减少检索的数据量。
因此,查询运行更快,因为数据库必须获取并提供请求的列,而不是表的所有列。
这将最小化数据库的I/O负担,特别是当表包含许多列或大量数据行时,这将非常有帮助。
以下是优化之前的代码。
SELECT * FROM customer;这是输出结果。
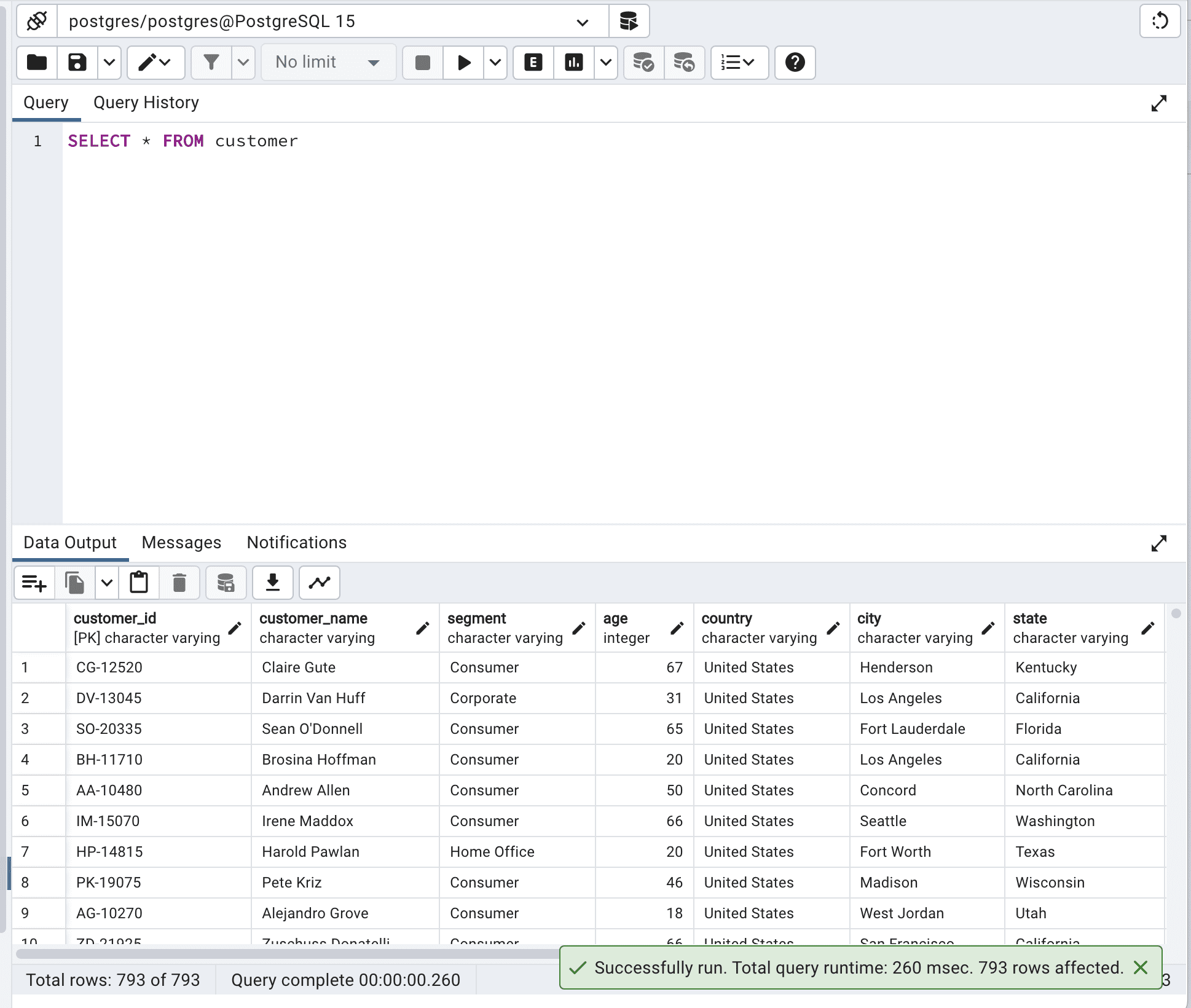
总查询运行时间为260毫秒。这可以改进。
为了向您展示这一点,我将选择仅选择3个不同的列,而不是选择所有列。
您可以根据项目需求选择所需的列。
以下是代码。
SELECT customer_id,
age,
country
FROM customer;这是输出结果。
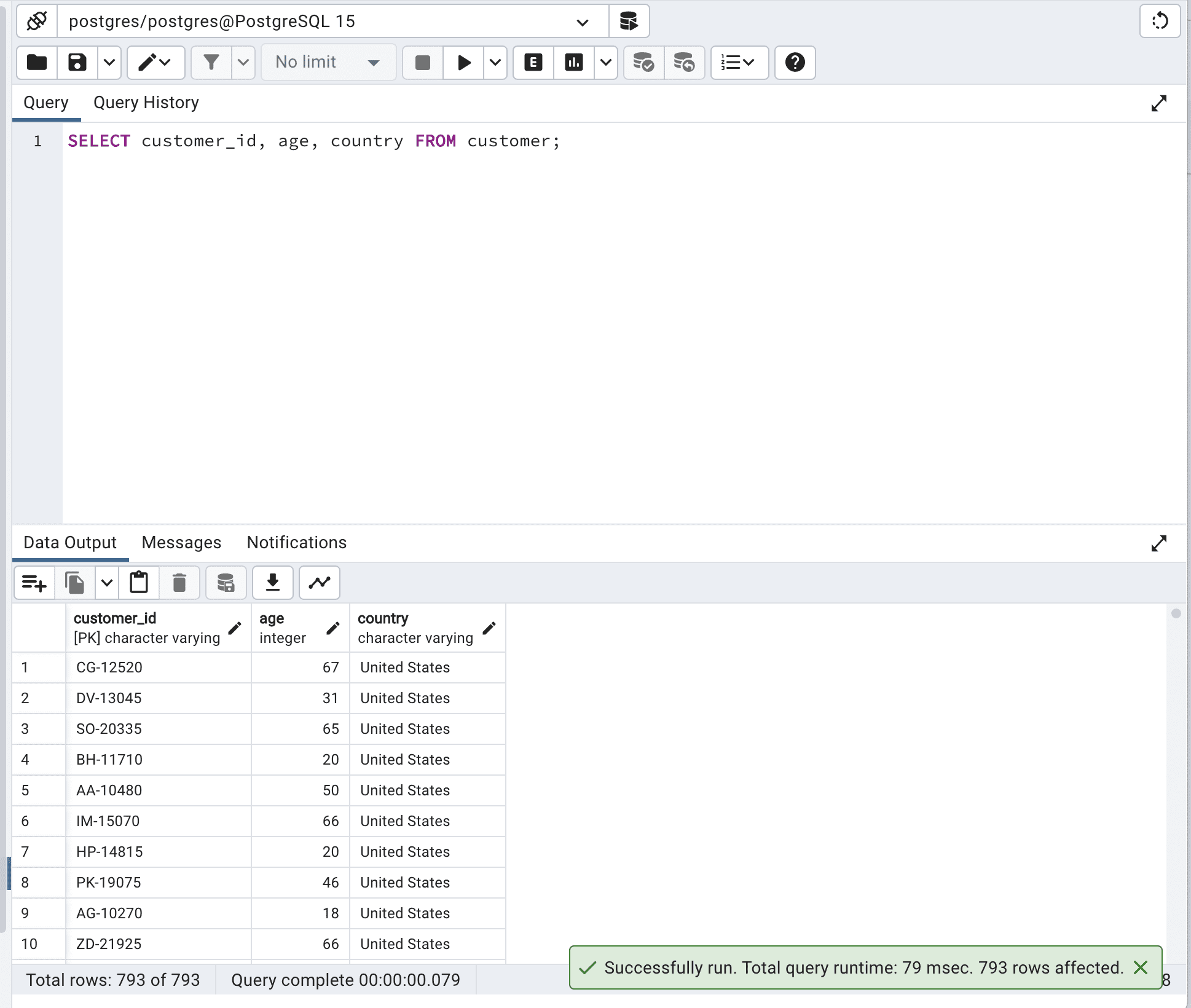
如您所见,通过定义我们想要选择的字段,我们不会强制数据库扫描所有数据,因此运行时间从 260 毫秒减少到 79 毫秒。
想象一下,如果有数百万或数十亿行,或者有数百列,差异会有多大。
避免使用 SELECT DISTINCT
SELECT DISTINCT 用于在指定的列中返回唯一值。为此,数据库引擎必须扫描整个表并删除重复值。在许多情况下,使用替代方法如 GROUP BY 可以通过减少处理的数据量来提高性能。
以下是代码。
SELECT DISTINCT segment
FROM customer;这是输出结果。
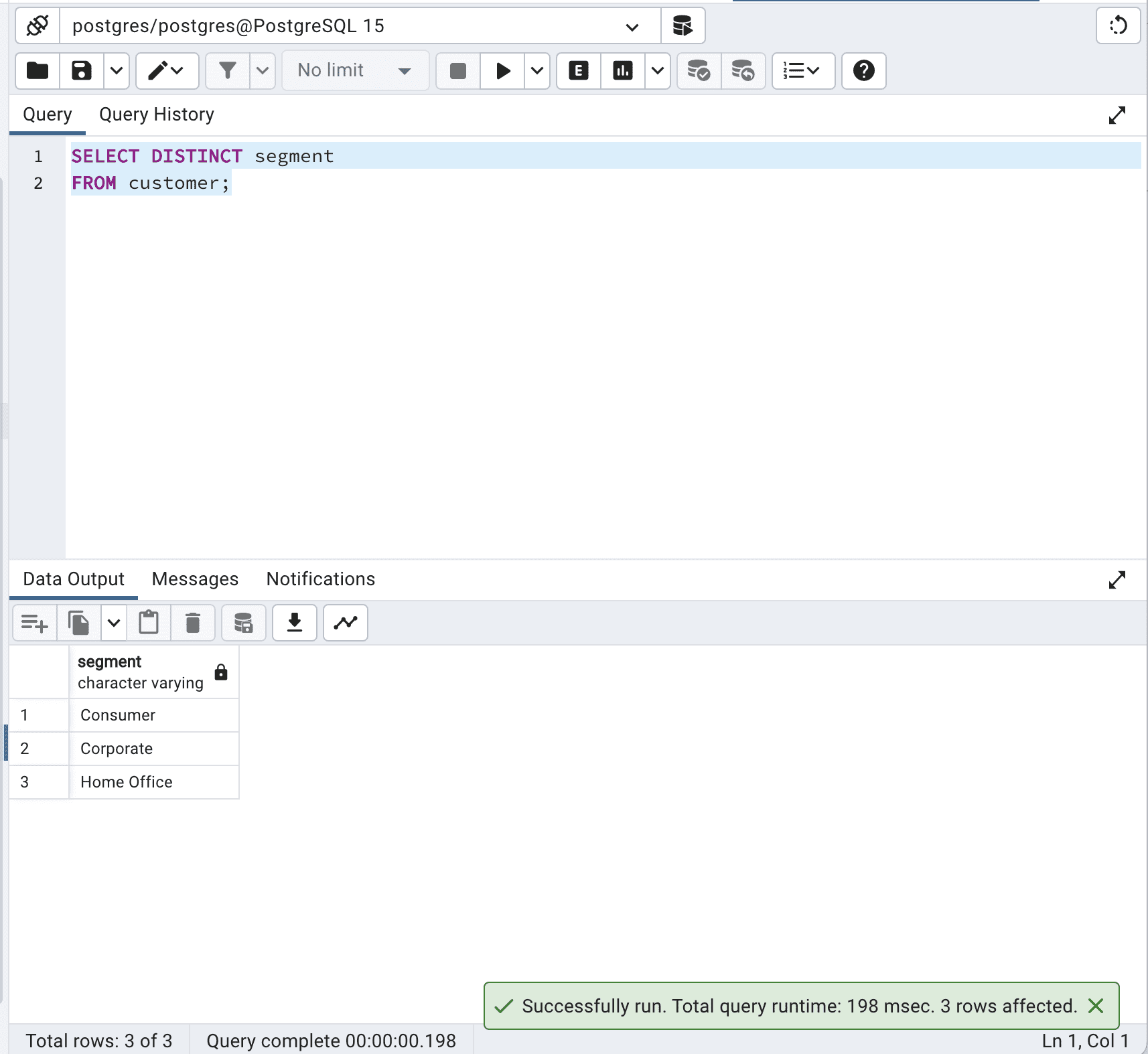
我们的代码从客户表中检索段列中的唯一值。数据库引擎必须处理表中的所有记录,识别重复值,并仅返回唯一值。对于大表而言,这可能在时间和资源方面代价高昂。
在替代版本中,以下查询使用 GROUP BY 子句检索段列中的唯一值。GROUP BY 子句根据指定的列对记录进行分组,并为每个组返回一个记录。
以下是代码。
SELECT segment
FROM customer
GROUP BY segment;这是输出结果。
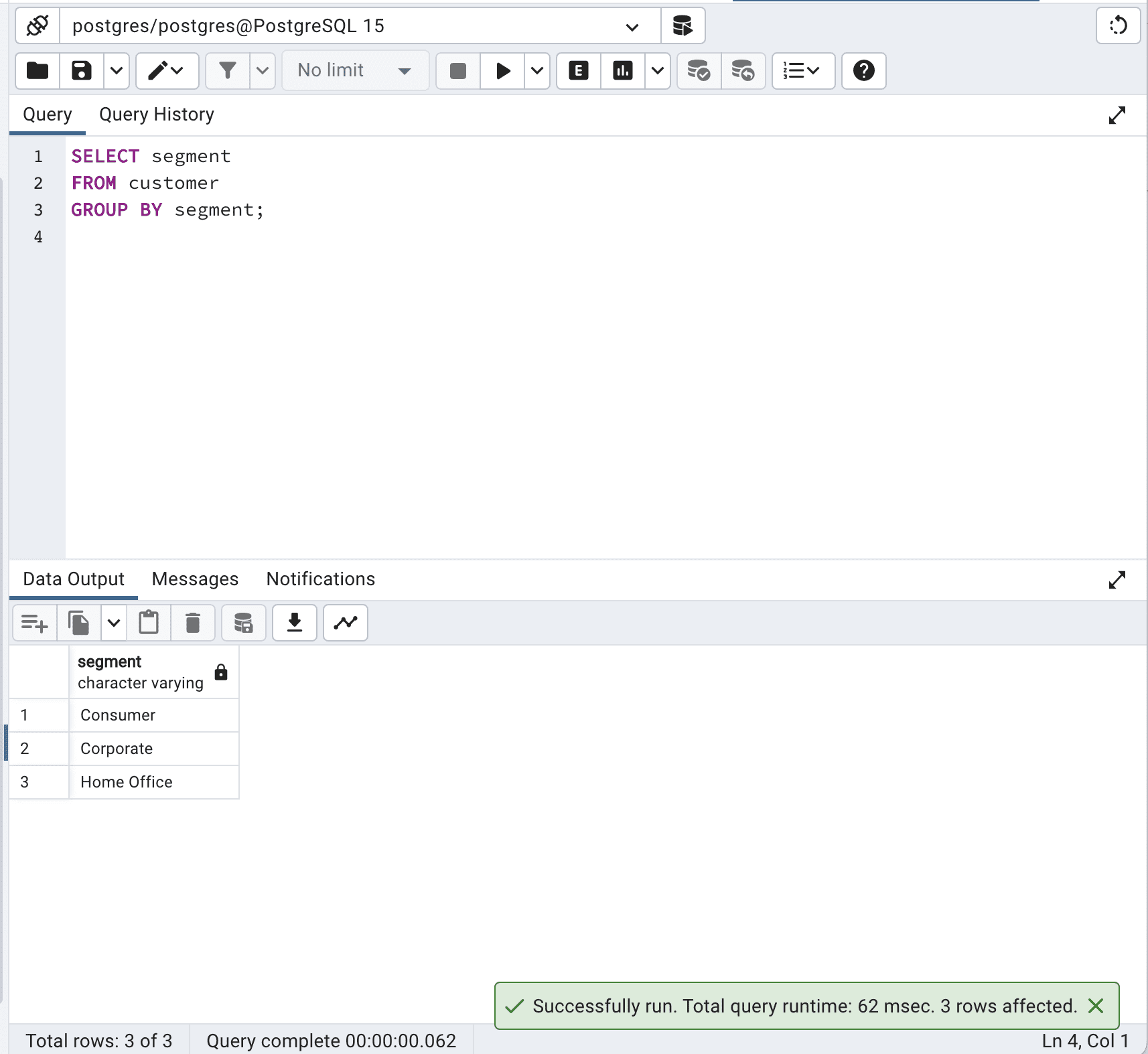
在这种情况下,GROUP BY 子句有效地根据段列对记录进行分组,导致与 SELECT DISTINCT 查询相同的输出。
通过避免使用 SELECT DISTINCT,改用 GROUP BY,可以优化 SQL 查询,并将总查询时间从 198 毫秒减少到 62 毫秒,这比原来快了 3 倍以上。
避免使用循环
循环可能会使查询速度变慢,因为它们强制数据库逐个记录地处理。
可能时,使用内置操作和 SQL 函数,这可以利用数据库引擎的优化并更有效地处理数据。
让我们定义一个带有循环的自定义函数。
CREATE OR REPLACE FUNCTION sum_ages_with_loop() RETURNS TABLE (country_name TEXT, sum_age INTEGER) AS $$
DECLARE
country_record RECORD;
age_sum INTEGER;
BEGIN
FOR country_record IN SELECT DISTINCT country FROM customer WHERE segment = 'Corporate'
LOOP
SELECT SUM(age) INTO age_sum FROM customer WHERE country = country_record.country AND segment = 'Corporate';
country_name := country_record.country;
sum_age := age_sum;
RETURN NEXT;
END LOOP;
END;
$$ LANGUAGE plpgsql;以上代码使用基于循环的方法来计算客户段为“Corporate”的每个国家的年龄总和。
它首先检索不同国家的列表,然后使用循环迭代每个国家,计算该国家客户年龄的总和。这种方法可能很慢和低效,因为它逐行处理数据。
现在让我们运行此函数。
SELECT *
FROM sum_ages_with_loop()这是输出结果。
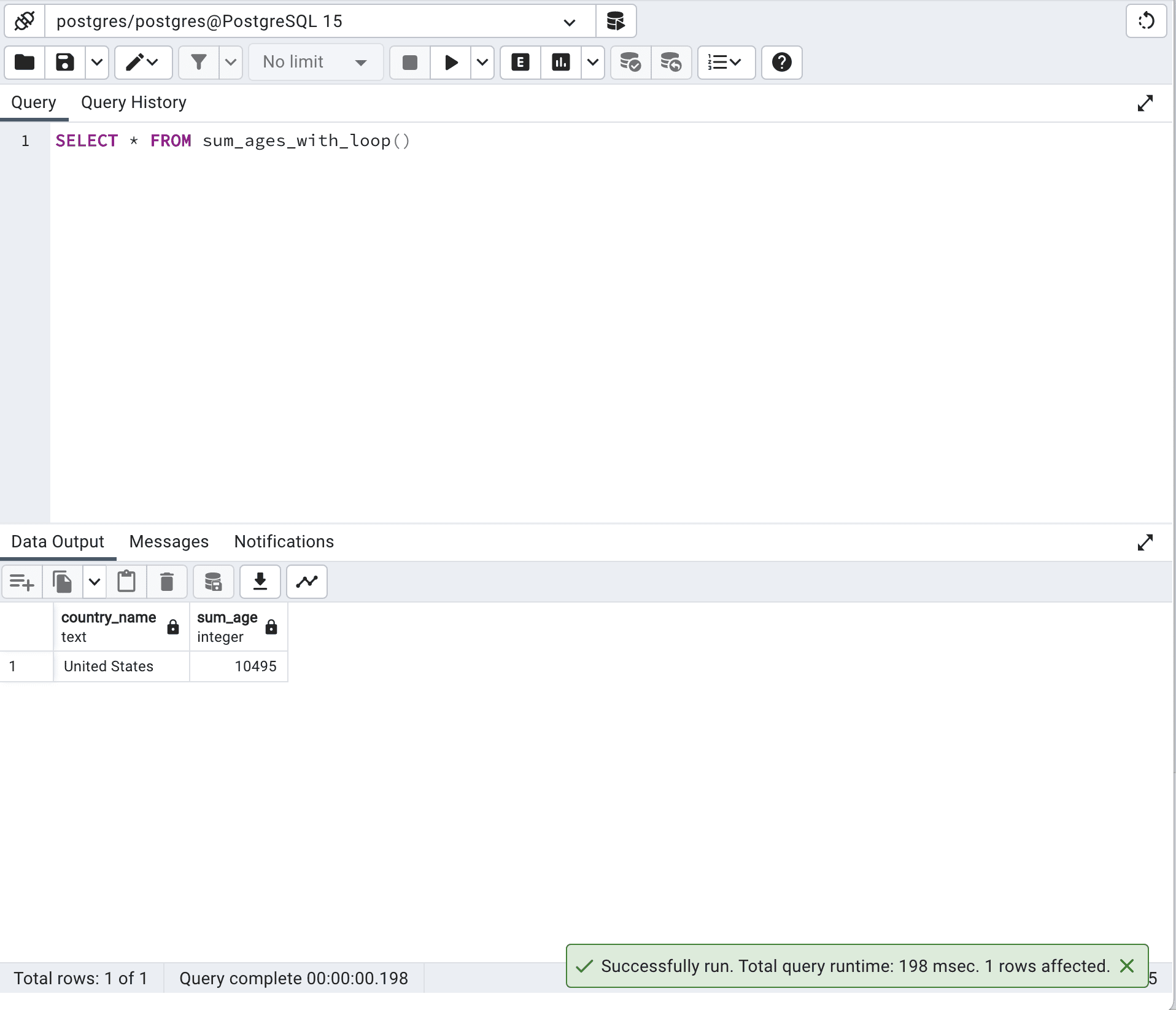
这种方法的运行时间为 198 毫秒。
现在让我们看看我们优化后的 SQL 代码。
SELECT country,
SUM(age) AS sum_age
FROM customer
WHERE segment = 'Corporate'
GROUP BY country;这是它的输出。
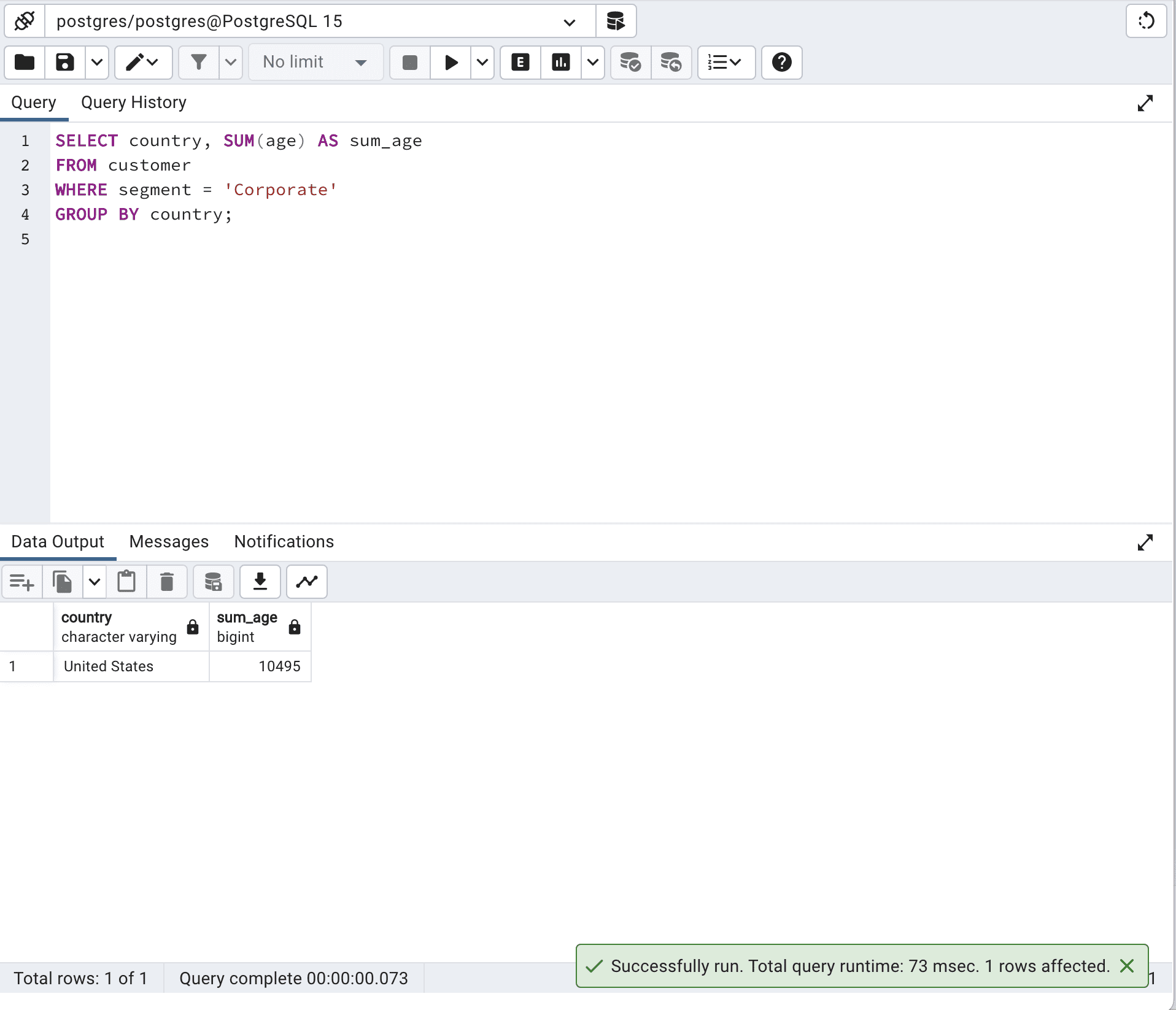
通常情况下,使用单个SQL查询的优化版本会表现更佳,因为它利用了数据库引擎的优化能力。
为了在我们的第一个代码中获得相同的结果,我们使用了PL/pgSQL函数中的循环,这通常比使用单个SQL查询更慢且效果更差。而且,这会强制你编写更多的代码行!
正确使用通配符
正确使用通配符对于优化SQL查询非常重要,特别是在匹配字符串和模式时。
通配符是在SQL查询中用于查找特定模式的特殊字符。
SQL中最常见的通配符是“%”和“_”,其中“%”表示任何字符序列,“_”表示一个字符。
明智地使用通配符很重要,因为不当的使用可能会导致性能问题,特别是在大型数据库中。
然而,高效地使用它们可以大大提高字符串匹配和模式匹配查询的性能。
现在让我们看看我们的例子。
此查询使用RIGHT()函数提取customer_name列的最后三个字符,然后检查它是否等于“son”。
SELECT customer_name
FROM customer
WHERE RIGHT(customer_name, 3) = 'son';这是输出。
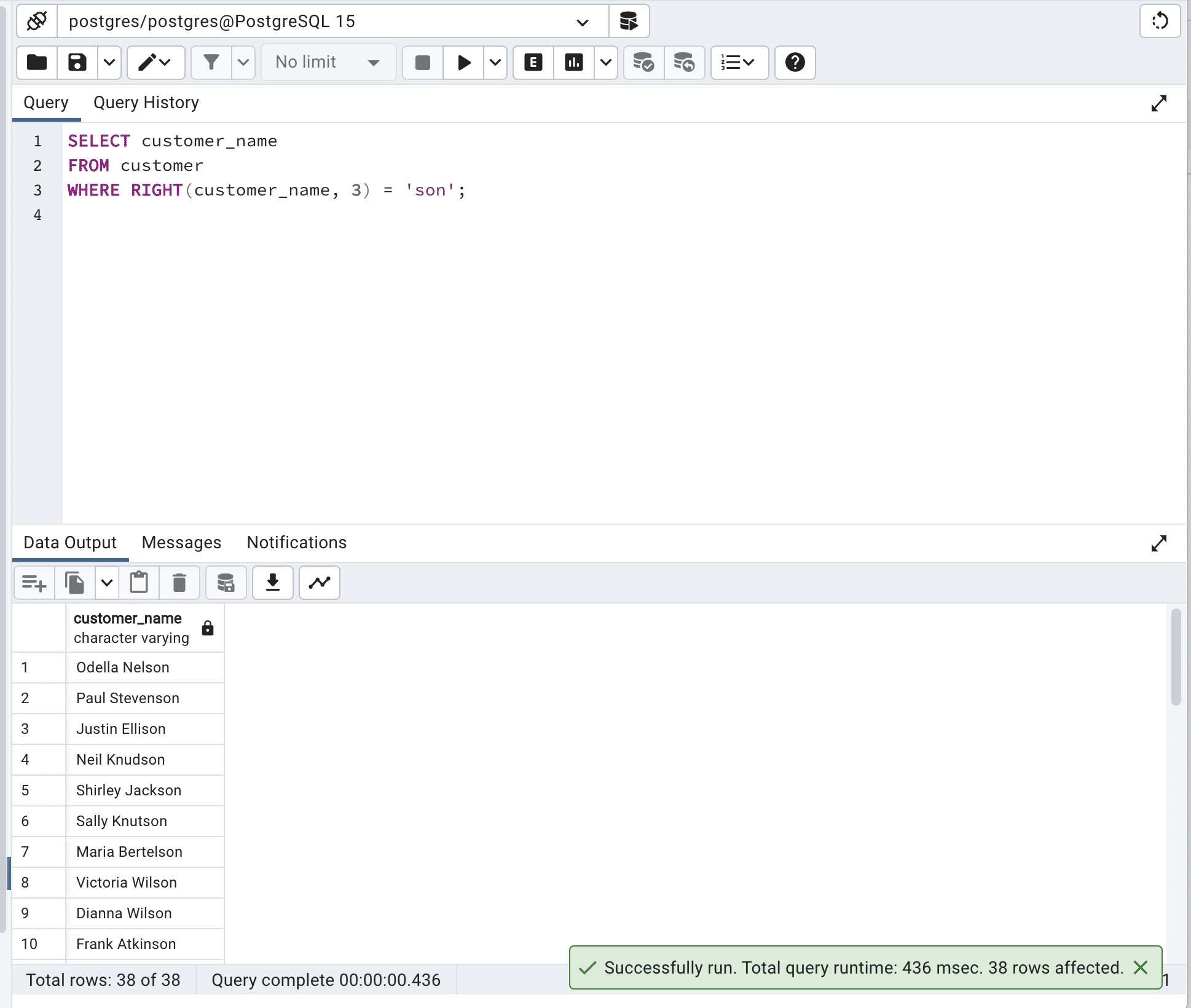
虽然此查询达到了所需的结果,但效率不高,因为必须将RIGHT()函数应用于表中的每一行。
让我们通过使用通配符来优化我们的代码。
SELECT customer_name
FROM customer
WHERE customer_name LIKE '%son';这是输出。
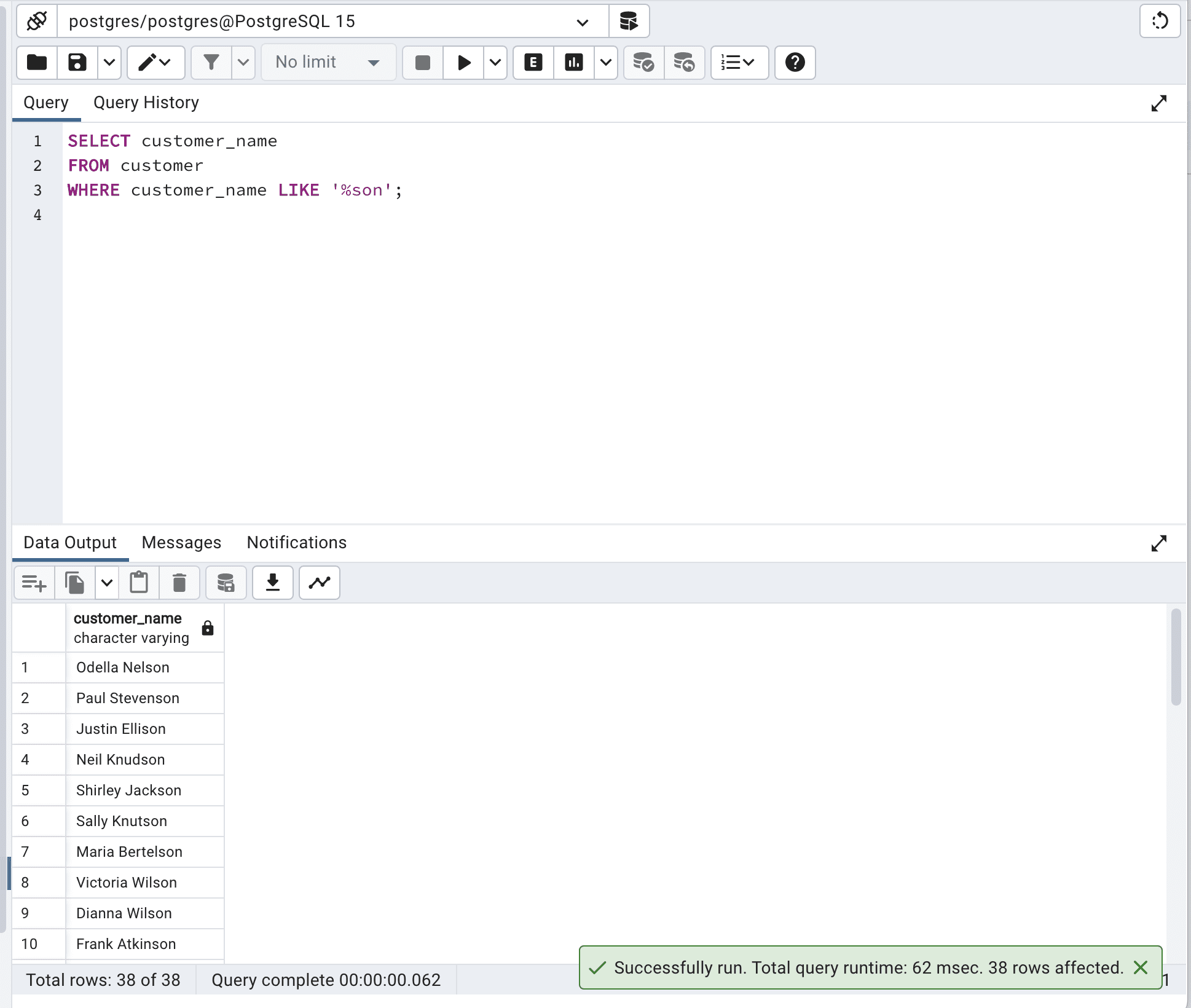
此优化的SQL查询使用LIKE运算符和通配符“%”来搜索customer_name列以“son”结尾的记录。
这种方法更有效,因为它利用了数据库引擎的模式匹配能力,如果可用,它可以更好地利用索引。
正如我们所看到的,总查询时间从436毫秒减少到62毫秒,快了近7倍。
使用Top或LIMIT限制样本结果的数量
使用TOP或LIMIT限制样本结果对于优化SQL查询至关重要,特别是处理大型表时。
这些子句允许您仅从表中检索指定数量的记录,而不是所有记录,这对性能有益。
现在,让我们检索customer表中的所有信息。
SELECT *
FROM customer这是输出。
当处理更大的表时,此操作可能会增加I/O和网络延迟,这可能会降低SQL查询性能。
现在,让我们通过将输出限制为10来优化我们的代码。
SELECT *
FROM customer
LIMIT 10;这是输出。
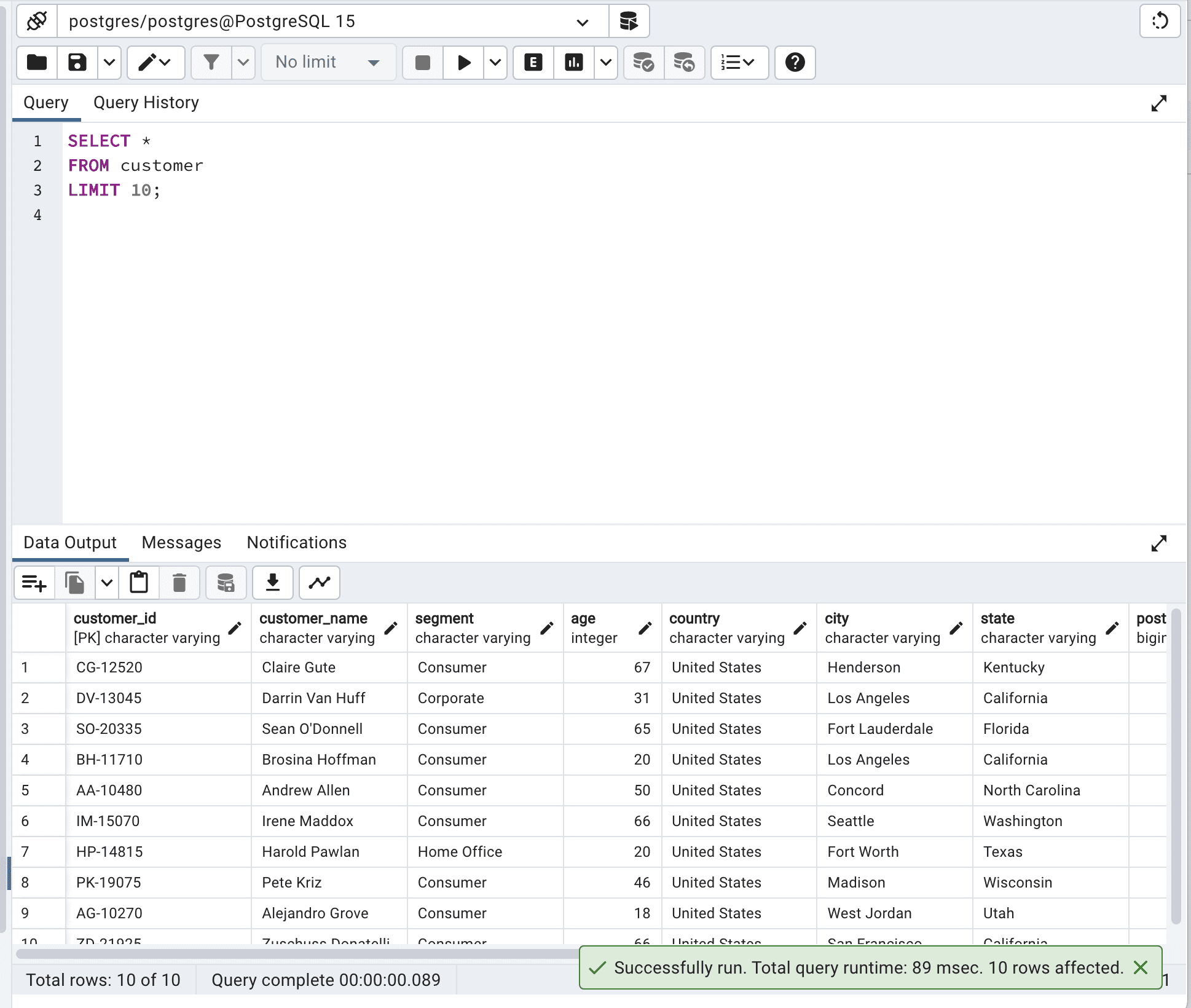
通过限制输出,您将减少网络延迟和内存使用,并提高响应时间,特别是在处理更大的表时。在我们的示例中,经过SQL查询优化后,总查询运行时间从260毫秒减少到89毫秒。
所以我们的查询变得快了近3倍。
使用索引
这次,我们将识别并创建用于WHERE、JOIN和ORDER BY子句中使用的列的适当索引,以提高查询性能。
通过索引经常访问的列,数据库可以更快地检索数据。
现在,让我们先运行以下查询。
SELECT customer_id,
customer_name
FROM customer
WHERE segment = 'Corporate';这是输出。 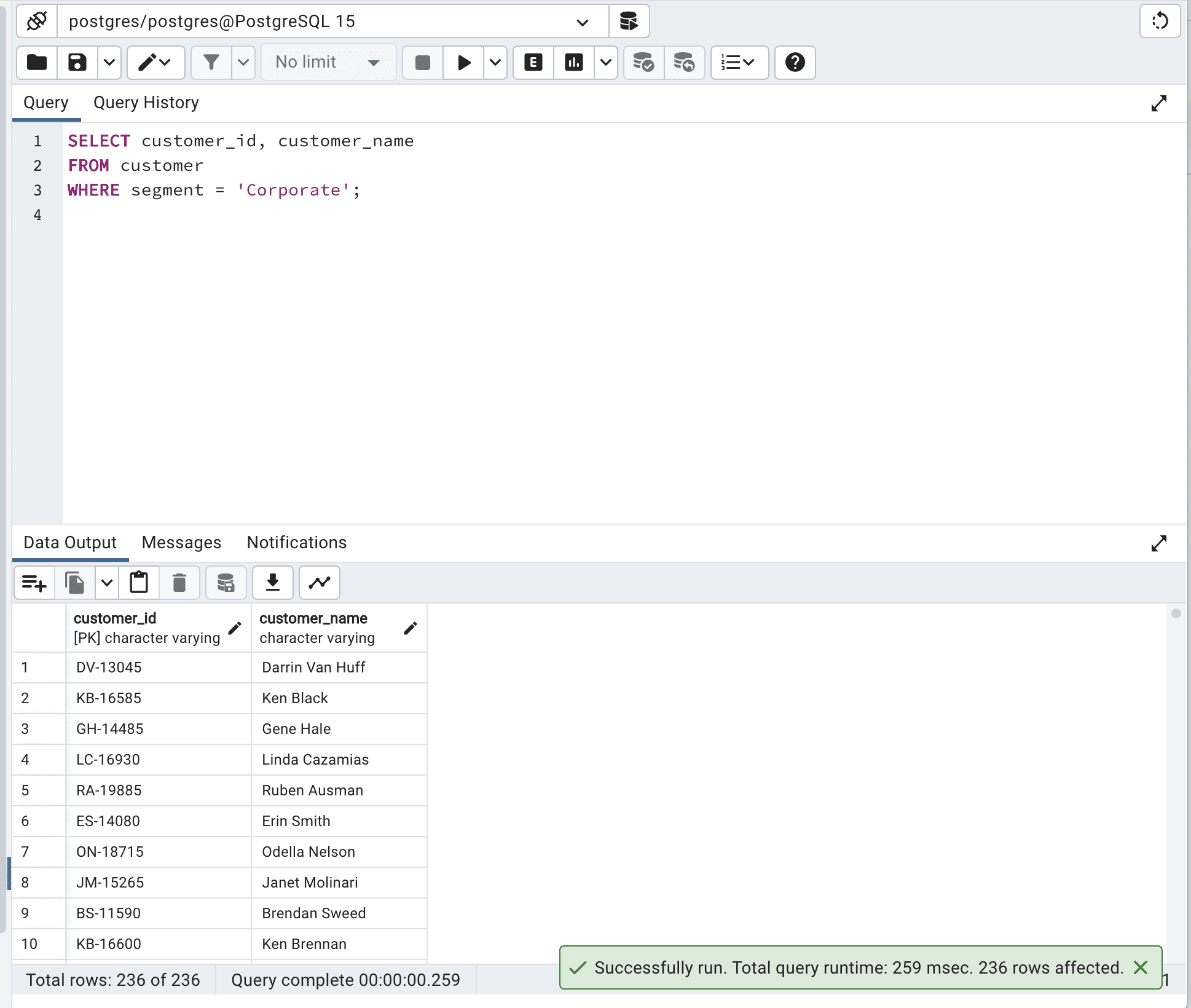
我们的查询运行时间为259毫秒。
让我们通过创建索引来改进查询。
CREATE INDEX idx_segment ON customer (segment);太好了,现在让我们再次运行代码。
SELECT customer_id,
customer_name
FROM customer WITH (INDEX(idx_segment))
WHERE segment = 'Corporate';这是输出。
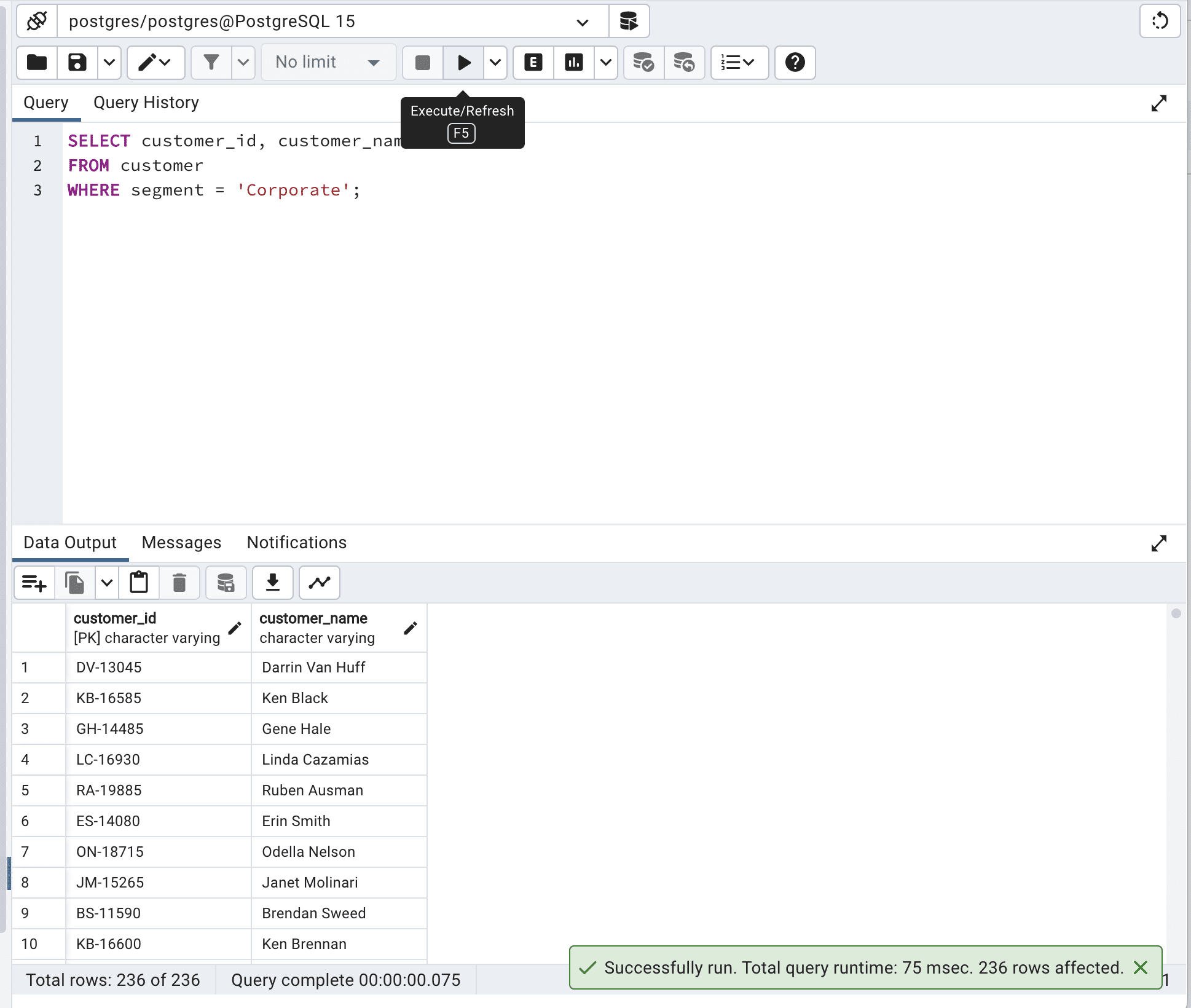
通过在INDEX()中使用idx_segment,数据库引擎能够根据segment列高效地搜索customer表,使查询运行更快-它将总查询时间从259毫秒减少到75毫秒。
奖励部分:使用SQL查询优化工具
由于长代码和高度复杂的查询的复杂性,您可能考虑使用查询优化工具。
这些工具可以分析您的查询执行计划,识别缺少的索引,并建议替代的查询结构,以帮助优化查询。一些流行的查询优化工具包括:
- SolarWinds数据库性能分析器:该工具帮助您监视和提高数据库性能。它显示查询问题以及它们如何运行。它可以与不同的数据库系统一起使用,例如SQL Server,Oracle和MySQL。
您可以在此处找到它。
- SQL诊断管理器的SQL查询调谐器:该工具具有改进查询的高级功能,例如性能提示,索引检查和显示查询运行方式。它通过查找和修复问题来帮助您使SQL查询更好。
- SQL Server管理工具(SSMS):SSMS具有用于检查性能和改进查询的内置工具,例如Activity Monitor,Execution Plan Analysis和Index Tuning Wizard。
- EverSQL: EverSQL是一种在线工具,通过查看数据库结构和查询运行方式自动改进您的查询。它向您提供建议并重写SQL查询,使其工作更快。
使用SQL查询优化工具和资源对于改进查询至关重要。通过这些工具,您可以了解查询的工作原理,发现问题并使用最佳实践来更快地获取数据并改进应用程序。
如果您想简化复杂的SQL查询,请查看此“如何简化复杂的SQL查询”。
最后的注意事项
通过优化上述SQL查询所做的更改可能由于其规模(毫秒)而显得微不足道。但随着您处理的数据量增加,这些毫秒将增加到秒,分钟甚至可能是小时。那时,您将意识到这些SQL查询优化技术的重要性。
如果您想寻找更多信息,请查看前30个SQL查询面试问题,这将有助于那些在学习时还想准备面试的人。
谢谢阅读! Nate Rosidi是一位数据科学家,产品战略师。他还是一位副教授,教授分析,并是StrataScratch的创始人,这是一个平台,可以通过来自顶级公司的真实面试问题帮助数据科学家为其面试做准备。在Twitter上与他联系:StrataScratch或LinkedIn。




