ChatGPT生成的食品行业评论:现实主义评估
探究聊天GPT生成数据如何支持食品行业公司的评论和调查收集
起源
过去,我的大部分研究都是使用生成式对抗网络(GAN)创建数据集中深度伪造图像。我想这样做是为了增加数据集中的信息多样性,从而预测会得到更好的物体检测模型(在此处了解更多有关此研究的信息!)。虽然这是与生成深度伪造图像创建完全不同的任务,但我想知道:“是否有一种方法可以增加我用于包含食品行业不同公司评论的数据集的大小?”
我能训练一个 GAN 吗?可以,但 GAN 不擅长生成表格数据,而对我而言,文本中的单词更符合电子表格中的数据。然后 ChatGPT 就来了。哇!我能否通过简单地要求 ChatGPT 生成不同的提示来为我的数据集创建新的评论?
为什么它很重要
我们想增加数据集的大小有几个原因。
缺乏足够的数据来训练模型。
偏见的数据集(因此我们需要用未代表的数据类来进行偏置)。
数据集内缺乏多样性
我正在创建的数据集(在今天的示例中使用的公司已经批准)缺乏负面评论、评论多样性和大小,因此需要实施数据集增强。
缺乏足够的数据来训练模型。如果试图使用缺乏数据的模型构建模型,可能会出现多种问题。一个问题可能是模型过度拟合数据,在实际世界的例子中表现不佳。
偏见的数据集。如果数据集由一个类主导,那么它缺乏其他类的表示,这将导致模型和分析不适用于所述类。我们希望有一个平衡的数据集,以确保我们的模型在我们感兴趣的所有数据类别的操作中表现良好。
数据集内缺乏多样性。现实世界是混乱的。如果我们的数据集缺乏多样性,那么我们的模型将无法很好地推广到样本细节的变化一旦投入生产。 泛化能力 是模型分类或知道样本属于某个类的能力,即使该样本包含与该类别中的特征不同或代表不足的特征。
分析
以下 API 用于今天的分析。
from gensim.models import Word2Vec,KeyedVectorsimport gensim.downloader as apiimport pandas as pd import matplotlib.pyplot as pltimport numpy as npimport seaborn as snsimport spacyimport spacy.cliimport spacyimport numpy as npfrom random import samplefrom sklearn.metrics.pairwise import cosine_similarityfrom sklearn.feature_extraction.text import TfidfVectorizer#To download spacy.cli.download("en_core_web_lg")数据集数据集
原始数据集是在公司 (Altomontes Inc) 的许可下编制的评论 (请参阅这两篇文章,我在其中展示了如何在评论上使用自然语言处理)。
机器学习不仅仅是大型技术公司的专属
使用自然语言处理支持小型企业。
towardsdatascience.com
小型企业的主题建模分析
介绍
towardsdatascience.com
原始评论的示例:
“强烈推荐!!!我之前从未听说过 Altomontes,直到最近一位朋友在我家里送了一顿饭。我和我丈夫决定去看看,当我们在那里时,我们遇到了业主,她是有史以来最甜美的人!她基本上给了我们一个旅游。我们买了鸡肉马萨拉的晚餐,它非常棒!我们还买了布鲁克林披萨作为午餐,它非常美味!我们品尝了他们的咖啡,他们让我们品尝了一个卡诺利、比斯科蒂和饼干。非常好吃!我们买了贝壳、马里纳拉酱、一瓶酒、一些奶酪等等。一切看起来都很好、味道很好,我们可以在那里度过几个小时!我们会回来的!!也许是今天?”
接下来,我使用ChatGPT创建了两个数据集。其中一个包含关于意大利市场及其销售商品的积极评价,而另一个包含关于意大利市场及其销售商品的消极评价。
ChatGPT生成的积极评价示例:
“我买的托斯卡纳佩科里诺奶酪味道浓郁,鲜美可口。它坚实而易碎的质地,略带草香,使它成为刨碎、切片或单独享用的绝佳选择。”
ChatGPT生成的消极评价示例:
“我尝试的意式火腿和芝麻菜披萨的芝麻菜已经枯萎,而火腿很硬。它并不开胃。”
一旦所有评价都被创建并放置到CSV文件中(在此处找到它们),我将它们格式化成一个字典,其中每个键都是源(源是原始的、生成的积极的或生成的消极的),项是其评价和一个元组列表,其中每个元组包含评价及其来源。
#字典:键=源,值=评价#列表:每个数据集的评价列表reviews = []reviews_dict = {}reviews_dict['原始评价'] = []reviews_dict['虚假积极评价'] = []reviews_dict['虚假消极评价'] = []#原始评价orig_reviews = pd.read_csv('/content/drive/MyDrive/reviews/Altomontes_reviews.csv')for rev in orig_reviews.Review: reviews_dict['原始评价'].append(rev) reviews.append((rev,'原始评价'))#积极评价pos_reviews = pd.read_csv('/content/drive/MyDrive/reviews/generated_positive_reviews - Sheet1.csv')for rev in pos_reviews.Review: reviews.append((rev,'虚假积极评价')) reviews_dict['虚假积极评价'].append(rev)#消极评价neg_reviews = pd.read_csv('/content/drive/MyDrive/reviews/generated_negative_reviews - Sheet1.csv')for rev in neg_reviews.Review: reviews.append((rev,'虚假消极评价')) reviews_dict['虚假消极评价'].append(rev)一个原始评价的例子:句子评估
真实性评估
首先,我想简单评估一下这些评价是否“真实”。这类似于计算给定文本和其连接的连贯性。我的初始想法是它们都将被认为是真实的,但我认为将原始评价、人工积极评价和人工消极评价的分数可视化也很有趣。
为了开始此评估,我们首先需要创建一个assess_sentence_realism函数。该函数旨在查看句子的连贯性以及输入句子是否“真实”反映了人类的解释。
def assess_sentence_realism(sentence, model): """ 一个函数,它接受一个句子和嵌入模型作为输入,并根据句子的连贯性和单词之间的相似性输出一个“真实性”分数 输入: sentence (str):单词字符串。 model (.model):嵌入模型(用户的选择) 返回值: avg_similarity:句子中单词之间的平均相似度。 """ tokens = sentence.split() # 计算相邻单词对之间的平均相似度 similarities = [] for i in range(len(tokens) - 1): word1 = tokens[i] word2 = tokens[i + 1] if word1 in model.key_to_index and word2 in model.key_to_index: word1_index = model.key_to_index[word1] word2_index = model.key_to_index[word2] similarity = model.cosine_similarities( model.get_vector(word1), [model.get_vector(word2)] )[0] similarities.append(similarity) # 计算平均相似度得分 if similarities: avg_similarity = sum(similarities) / len(similarities) else: avg_similarity = 0.0 return avg_similarity您需要下载一个嵌入模型来创建您的单词嵌入。我选择使用的模型是Google News 300模型(在此处查看它)。
#下载预训练的Word2Vec模型#model_name = 'word2vec-google-news-300' # 示例模型名称#model = api.load(model_name)#model.save('/content/drive/MyDrive/models/word2vec-google-news-300.model') pretrained_model_path = '/content/drive/MyDrive/models/word2vec-google-news-300.model'model = KeyedVectors.load(pretrained_model_path)scores = {}sources = []#评估每个句子的真实性分数并存储在分数字典中for sentence, source in reviews: realism_score = assess_sentence_realism(sentence, model) if source in scores: scores[source].append(realism_score) else: scores[source] = [realism_score] sources.append(source) #print(f"Realism Score for {source}: {realism_score}")#计算每个源的平均分数mean_scores = {source: np.mean(score_list) for source, score_list in scores.items()}#在散点图中绘制平均分数colors = {'原始评价': 'green','虚假积极评价':'blue','虚假消极评价':'red'}sns.set_style("darkgrid", {"axes.facecolor": ".9"})plt.figure(figsize=(8, 6))plt.bar(mean_scores.keys(), mean_scores.values(),color=['green','blue','red'])plt.xlabel("来源")plt.ylabel("平均真实性分数")plt.title("来源的平均真实性分数")plt.show()→ 原始数据集评分:0.17
→ ChatGPT生成的正面数据集评分:0.15
→ ChatGPT生成的负面数据集评分:0.16
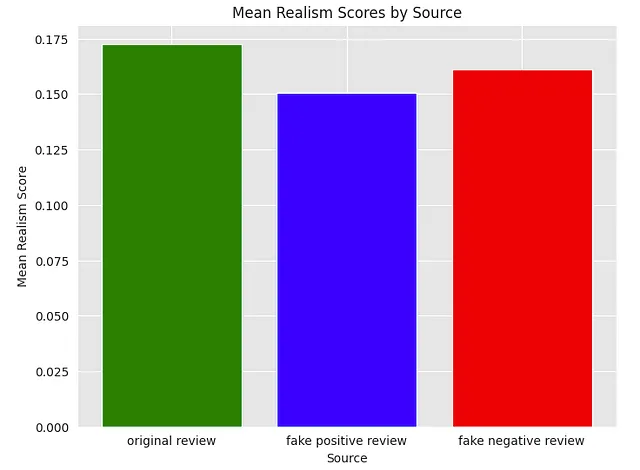
正如我们所预料的(也许),原始评论被评分为最真实的。这可能是为什么呢?首先,它们是真实的评论。我怀疑ChatGPT的评分较低的一个重要原因与它生成的评论有一定的模式有关。有些评论非常接近,ChatGPT只是简单地改变了一些单词。
(即。 披萨不好吃,很干→意大利面不好吃,很干)
与真实评论相比,ChatGPT的评论也缺乏多样性,这是可以预料的(想想吧,有多个人写真实评论,而只有一个模型创建了虚假评论)。尽管如此,与原始评论相比,ChatGPT创建的评论仍然得分相对较高,我认为在未来训练模型时值得一试。
在这样做之前,让我们也对这些评论进行相似度评估。
相似度评估
接下来,我想查看生成评论的每一批次与原始评论之间的相似之处。为此,我们可以使用余弦相似度计算每个来源的不同句子向量之间的相似度。首先,我们可以创建一个余弦相似度矩阵,该矩阵将使用TfidVectorizer()将我们的句子转换为向量,然后计算两个新句子向量之间的余弦相似度。
def cosine_similarity(sentence1, sentence2): """ 一个接受两个句子作为输入并输出它们的余弦相似度的函数 输入: sentence1(str):一串单词 sentence2(str):一串单词 返回: cosine_sim:两个输入句子的余弦相似度分数 """ #初始化TfidfVectorizer vectorizer = TfidfVectorizer() #创建TF-IDF矩阵 tfidf_matrix = vectorizer.fit_transform([sentence1, sentence2]) #计算余弦相似度 cosine_sim = cosine_similarity(tfidf_matrix[0], tfidf_matrix[1]) return cosine_sim[0][0]我遇到的一个问题是数据集现在已经变得非常大,计算时间过长(有时在Google Colab上我没有足够的RAM继续计算)。为解决此问题,我从每个数据集中随机抽样了200个评论来计算相似性。
#随机抽样200个评论o_review = sample(reviews_dict['original review'],200)p_review = sample(reviews_dict['fake positive review'],200)n_review = sample(reviews_dict['fake negative review'],200)r_dict = {'original review': o_review, 'fake positive review': p_review, 'fake negative review':n_review}现在,我们有了随机选择的样本,可以查看不同数据集之间的余弦相似性。
#余弦相似度计算source = ['original review','fake negative review','fake positive review']source_to_compare = ['original review','fake negative review','fake positive review']avg_cos_sim_per_word = {}for s in source: count = [] for s2 in source_to_compare: if s != s2: for sent in r_dict[s]: for sent2 in r_dict[s2]: similarity = calculate_cosine_similarity(sent, sent2) count.append(similarity) avg_cos_sim_per_word['{0} to {1}'.format(s,s2)] = np.mean(count)results = pd.DataFrame(avg_cos_sim_per_word,index=[0]).T
对于原始数据集,负面评论更加相似。我的假设是这是因为我使用更多提示来创建负面评论而不是正面评论。毫不意外,ChatGPT生成的评论之间显示了最高的相似性迹象。
太好了,我们有余弦相似性,但是我们还能采取其他步骤来评估评论的相似性吗? 有的! 让我们将句子视觉化为向量。 为此,我们必须嵌入句子(将它们转换为数字向量),然后我们可以在2D空间中将它们可视化。 我使用Spacy来嵌入我的向量并将它们可视化。
# 加载预训练的GloVe模型nlp = spacy.load('en_core_web_lg')source_embeddings = {}for source,source_sentences in reviews_dict.items(): source_embeddings [source] = [] for sentence in source_sentences: # 使用spaCy标记化句子 doc = nlp(sentence) # 检索单词嵌入 word_embeddings = np.array([token.vector for token in doc]) # 保存源的单词嵌入 source_embeddings [source] .append(word_embeddings)def legend_without_duplicate_labels(figure): handles,labels = plt.gca()。get_legend_handles_labels() by_label = dict(zip(labels,handles)) figure.legend(by_label.values(),by_label.keys(),loc ='lower right ')# 根据源的颜色绘制嵌入fig,ax = plt.subplots()colors = ['g','b','r'] # 每个来源的颜色i = 0for source,embeddings in source_embeddings.items(): for embedding in embeddings: ax.scatter(embedding [:,0],embedding [:,1],c = colors [i],label = source) i + = 1legend_without_duplicate_labels(plt)plt.show()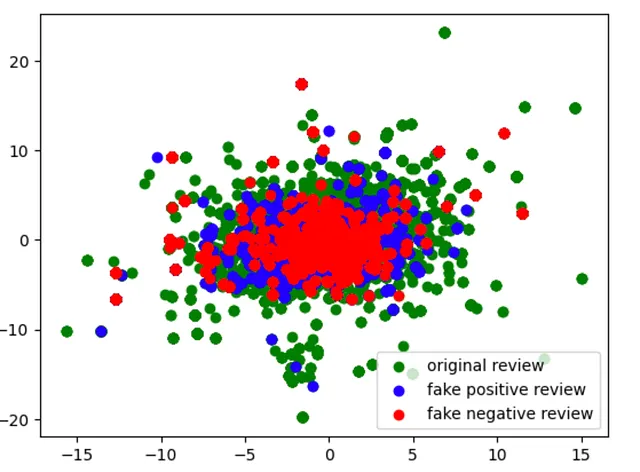
好消息是我们可以清楚地看到句子向量的嵌入和分布密切对齐。视觉检查显示原始评论的分布具有更大的可变性,支持断言它们更为多样化。由于ChatGPT生成了正面和负面评论,我们会怀疑它们的分布是相同的。然而,请注意,假的负面评论实际上具有比正面评论更宽的分布和更多的方差。为什么会这样?可能部分原因是我不得不欺骗ChatGPT创建假的负面评论(ChatGPT旨在说出积极的陈述),而我实际上必须提供更多提示给ChatGPT才能获得足够的负面评论与正面评论。这有助于数据集,因为有了数据集中的额外多样性,我们可以训练性能更高的机器学习模型。
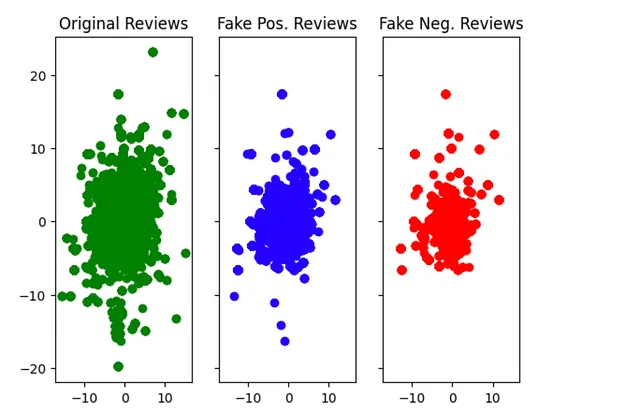
接下来,我们可以检查三个不同评论分布之间的差异,看看是否有任何显着模式。
我们看到了什么?从视觉上看,我们可以看到数据集的大部分评论都位于原点周围,并从-10到10。这是一个积极的迹象,并支持使用假评论来训练预测模型。方差有些相同,但是原始评论在其分布上横向和纵向的方差更大,这是词汇表中更多多样性的代理。 ChatGPT的评论明显具有相似的分布,但是积极评论具有更多的异常值。如上所述,这些差异可能是由于我如何提示系统生成评论所致。
缺陷和不足
虽然增加数据集的大小和多样性有许多附加好处,但这种方法也存在弱点和缺陷。新生成的数据可能不代表或接近真实数据的格式。虽然我们可以进行一些数学计算和可视化来支持相似性,但我们永远无法确定评论在机器语言中将如何被解释。我们可以使用此数据开发用于阅读食品业公司的调查和评论的模型,但是当给出来自真实世界的非结构化“脏”数据时,该模型可能会崩溃,因为我们已经更多地使用了遵循潜在模式的生成假数据进行了训练。
另一个问题是,一旦添加了虚假数据,我们就放弃了进行各种分析技术以进行信息提取的能力。例如,如果我使用这个新数据集进行主题建模分析,那么这些主题将不仅仅定义原始数据,还将定义虚假数据,这对我的客户毫无意义。如果我创建虚假评论,并声称“意大利面条很干”,那么我的客户为什么要关心“意大利面条很干”是一个主题呢?这是我的问题,而不是他们的问题。坦率地说,这个过程阻碍了我们进行探索性数据分析(EDA)的能力。我认为这是最大的折衷:使用这个数据集,我们可以创建分类和预测模型,这些模型可能适合解释新评论(甚至可能更好,因为数据集的大小增加了,但您需要建立测试这些模型的过程),但代价是我们无法从公司已有的数据中推断出更多的信息(如果我们使用这个数据集)。
我对任何使用生成数据的人最大的警告是,不要忘记你收集的原始数据。不要忘记你试图解决的原始问题和难题。忘记这一点可能会让你陷入一个问题的兔子洞,这个问题在于虚假数据本身!
结论
数据科学中出现的一个问题是缺乏数据和数据的多样性。有多种方法可以生成新数据,今天展示了如何使用ChatGPT为数据集创建更多数据。今天的发现对那些在食品行业工作的人特别有帮助。这样做可以缓解数据集的不平衡和缺乏多样性的问题,从而导致模型在训练后在真实世界数据上表现更好。
今天展示了什么?
ChatGPT数据可以帮助你的下一个自然语言处理项目(NLP),特别是如果你正在为食品行业的企业实施数据科学技术。我要提醒的是,首先尝试收集真实数据总是好的。如果你发现你的数据集需要更多的数据,探索像生成对抗网络(GAN)或大型语言模型(LLM)(比如ChatGPT)这样的选项可能不会有害。最后,我总是想强调,特别是在使用生成AI时,重要的是要在对所有影响方面使用这些工具的道德和积极方式。
你可能会想知道,使用这些工具的道德意味着什么?你应该使用生成AI来支持人们并给他们的生活带来积极的影响。有些人使用深度伪造技术来伤害一个人的形象,这是不可以接受的。此外,生成AI不应该用来欺骗某人或通过虚假不实的数据改变他们的想法。今天的例子是一个完美的用例,说明我们可以创建数据,用于为公司培训模型,了解客户评论的情感。它将帮助公司改变其产品和流程,以迎合客户的需求,对双方产生积极影响!
如果你喜欢今天的阅读,请关注我,并让我知道是否有其他主题你想让我探索!如果你没有小猪AI账户,请通过我的链接此处注册(当你这样做时,我会收到一小笔佣金)!此外,加我为LinkedIn的联系人,或随时与我联系!感谢阅读!
参考资料
- 数据使用由Altomontes公司批准。
- 完整代码在此处