可视化多重共线性对多元回归模型的影响
使用Python进行数据可视化,解释多重共线性对多元回归的影响
什么是多重共线性?
在多元回归中,当一个预测变量(自变量)与模型中的另一个或多个预测变量高度相关时,就会出现多重共线性。
为什么它很重要?
### 多元回归方程:Y = β₀ + β₁X₁ + β₂X₂ + ... + βᵢXᵢ + ε理论上,如上方程所示,多元回归使用多个预测变量来预测因变量的值。
顺便说一下,多元回归是通过确定一个预测变量的单位均值变化对因变量的影响来工作的,同时保持其他预测变量不变。
如果一个预测变量与其他变量高度相关,则很难改变这个变量而不改变其他变量。
多重共线性的影响
简单来说,多重共线性会影响模型系数。在数据发生微小变化时,它会影响系数估计。因此,解释每个自变量的作用变得困难。
本文将通过应用数据可视化来解释和展示这一现象。在开始之前,让我们讨论如何确定模型是否具有多重共线性。

如何检测多重共线性?
### VIF(方差膨胀因子)方程:VIF = 1/(1 - Rᵢ²)我们可以使用VIF(方差膨胀因子)来估计由于多重共线性而膨胀的回归系数的方差。
这个计算是通过将一个预测变量对其他预测变量进行回归以获得R平方值来完成的。然后,所获得的R平方值将用于计算VIF值。方程中的“i”表示预测变量。
可以使用以下标准来解释结果:
#1:不相关#1-5:中度相关#> 5:高度相关现在,我们已经完成了解释部分。让我们继续创建模型部分。
多元回归模型
首先,准备多元回归模型以进行绘图。首先,我们将从数据集中创建两个模型;一个是具有中度相关变量的模型,另一个是具有高度相关变量的模型。
然后,我们将稍微修改数据,以查看哪个模型会受到小的修改的影响更大。首先导入库。
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline获取数据
例如,本文将使用具有公共域许可证的Cars Data数据集。它可以通过seaborn.load_dataset()函数从Seaborn库中免费直接下载。
该数据集包含1970-1982年美国、欧洲和日本392辆汽车的价格和特征。有关数据集的更多信息,请访问以下链接。
data = sns.load_dataset('mpg')data.dropna(inplace=True) #删除空行data.head()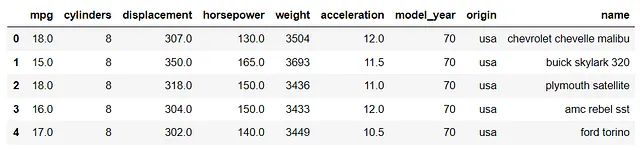
进行探索性数据分析以了解数据集始终是一个好主意。
data.describe()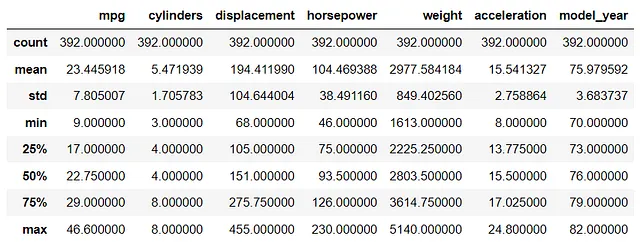
列中的范围(最大值-最小值)相当不同。因此,执行标准化可以帮助后面解释系数。
data = data.iloc[:,0:-2] # 选择列from sklearn.preprocessing import StandardScalerscaler = StandardScaler()df_s = scaler.fit_transform(data)df = pd.DataFrame(df_s, columns=data.columns)df.head()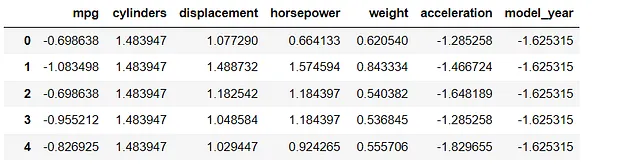
接下来通过绘制热图来显示变量之间的相关性。
plt.figure(figsize=(9, 6))sns.heatmap(df.corr(), cmap='coolwarm', annot=True)plt.show()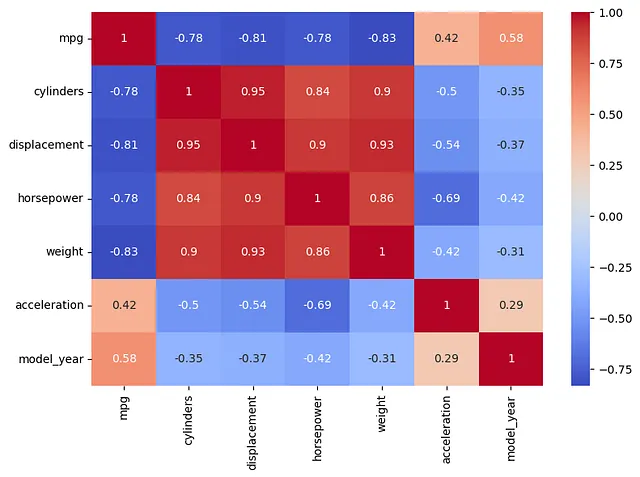
结果表明,有一些变量与其他变量高度相关。如果将每个预测变量放入多元回归模型中来预测“mpg”值,则多重共线性将影响模型。
计算 VIF 值
可以通过使用 Statsmodels 库计算 VIF 值来快速证明这一点。
from statsmodels.stats.outliers_influence import variance_inflation_factor as vifvif_data = pd.DataFrame()vif_data["feature"] = df.columns# 为每个特征计算 VIFvif_data["VIF"] = [vif(df.values, i) for i in range(len(df.columns))]print(vif_data)
一些 VIF 值相当高(>5),可以解释为高度相关。如果直接将每个预测变量放入多元回归模型中,模型可能会受到多重共线性问题的影响。
接下来,只选择一些预测变量。本文将使用两个模型:一个具有中度相关和另一个具有高度相关的预测变量。
第一个多元回归模型使用“气缸”和“加速度”来预测“mpg”,而第二个模型使用“气缸”和“排量”。让我们再次计算 VIF 值。
df1 = df[['mpg', 'cylinders', 'acceleration']]df2 = df[['mpg', 'cylinders', 'displacement']]# VIF 数据帧1vif_data1 = pd.DataFrame()vif_data1['feature'] = df1.columnsvif_data1['VIF'] = [vif(df1.values, i) for i in range(len(df1.columns))]print('model 1')print(vif_data1)# VIF 数据帧2vif_data2 = pd.DataFrame()vif_data2['feature'] = df2.columnsvif_data2['VIF'] = [vif(df2.values, i) for i in range(len(df2.columns))]print('model 2') print(vif_data2)
这两个模型之间的差异是从变量“加速度”变为“排量”。然而,可以注意到第一个模型中没有任何 VIF 值大于 5,而第二个模型具有相对较高的 VIF 值,超过了 10。
创建多元回归模型
我们将使用 statsmodels 库中的 OLS 函数创建多元回归模型。
import statsmodels.api as smy1 = df1[['mpg']]X1 = df1[['cylinders', 'acceleration']]lm1 = sm.OLS(y1, X1)model1 = lm1.fit()model1.summary()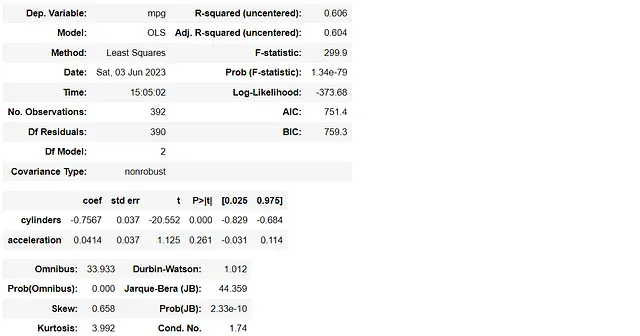
绘制模型
从所得的模型中,我们将定义一个函数,在网格上运行模型以供下一步使用。
def run_model(v1, v2, pd_): mesh_size = 0.02 x_min, x_max = pd_[[v1]].min()[0], pd_[[v1]].max()[0] y_min, y_max = pd_[[v2]].min()[0], pd_[[v2]].max()[0] xrange = np.arange(x_min, x_max, mesh_size) yrange = np.arange(y_min, y_max, mesh_size) xx, yy = np.meshgrid(xrange, yrange) return xx, yy, xrange, yrange现在来到了有趣的部分。让我们使用Plotly库绘制模型,这有助于轻松创建交互式图形。因此,我们可以与可视化进行交互,例如缩放或旋转。
import plotly.express as pximport plotly.graph_objects as gofrom sklearn.svm import SVR#运行并应用模型xx1, yy1, xr1, yr1 = run_model('cylinders', 'acceleration', X1)pred1 = model1.predict(np.c_[xx1.ravel(), yy1.ravel()])pred1 = pred1.reshape(xx1.shape)#绘制结果fig = px.scatter_3d(df1, x='cylinders', y='acceleration', z='mpg')fig.update_traces(marker=dict(size=5))fig.add_traces(go.Surface(x=xr1, y=yr1, z=pred1, name='pred1'))fig.show()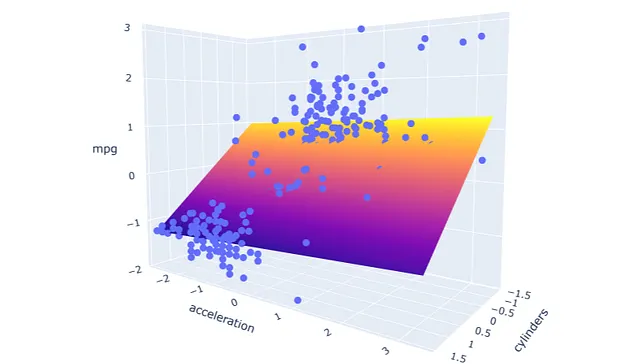
我们可以对第二个具有多重共线性问题的模型执行相同的过程。
y2 = df2[['mpg']]X2 = df2[['cylinders', 'displacement']]lm2 = sm.OLS(y2, X2)model2 = lm2.fit()model2.summary()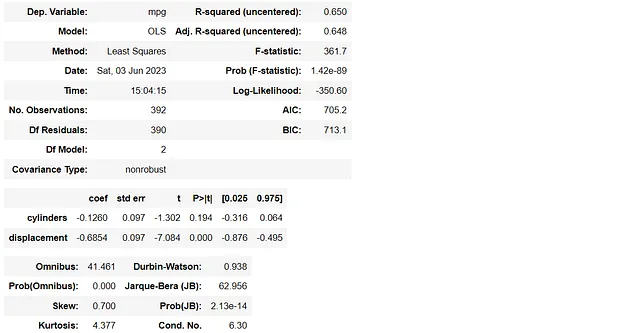
#运行并应用模型xx2, yy2, xr2, yr2 = run_model('cylinders', 'displacement', X2)pred2 = model2.predict(np.c_[xx2.ravel(), yy2.ravel()])pred2 = pred2.reshape(xx2.shape)#绘制结果fig = px.scatter_3d(df2, x='cylinders', y='displacement', z='mpg')fig.update_traces(marker=dict(size=5))fig.add_traces(go.Surface(x=xr2, y=yr2, z=pred2, name='pred2'))fig.show()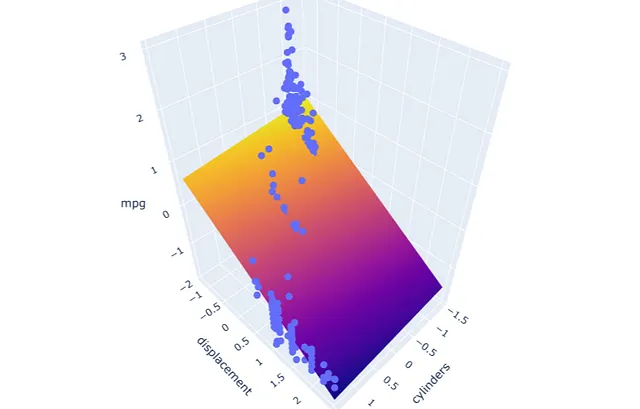
修改数据集
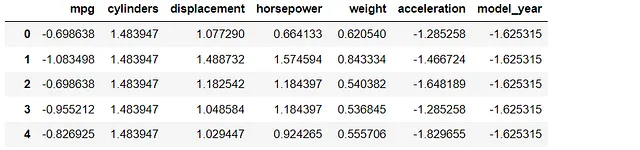
如先前提到的,数据的小修改可以影响系数估计。为了证明这一点,我们将随机选择一行并更改值。例如,它们将乘以1.25。
之后,我们可以进行相同的过程,并在同一图形中绘制新的和原始的多元回归模型以查看结果。
# 随机修改数据框中的一行
from random import *
x = randint(1, len(df))
mod_list = [i*1.25 for i in df.iloc[x,:]] #乘以1.25
df_m = df.copy()
df_m.iloc[x] = mod_list
df_m
计算VIF值
从修改后的数据集中计算VIF值以比较差异。
df_m1 = df_m[['mpg', 'cylinders', 'acceleration']]
df_m2 = df_m[['mpg', 'cylinders', 'displacement']]
# VIF dataframe1
vif_data1 = pd.DataFrame()
vif_data1['feature'] = df_m1.columns
vif_data1['VIF'] = [vif(df_m1.values, i) for i in range(len(df_m1.columns))]
print('model m1')
print(vif_data1)
#### VIF dataframe2
vif_data2 = pd.DataFrame()
vif_data2['feature'] = df_m2.columns
vif_data2['VIF'] = [vif(df_m2.values, i) for i in range(len(df_m2.columns))]
print('model m2')
print(vif_data2)
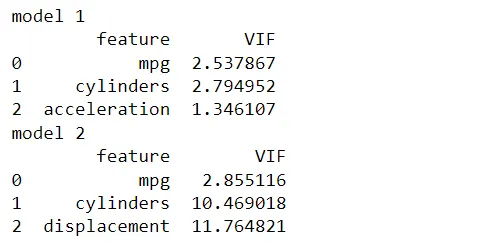

从修改后的数据集计算的新VIF值略有变化。两个模型仍然具有相同的条件:第一个和第二个模型的预测变量分别是中度相关和高度相关的。
创建多元回归模型
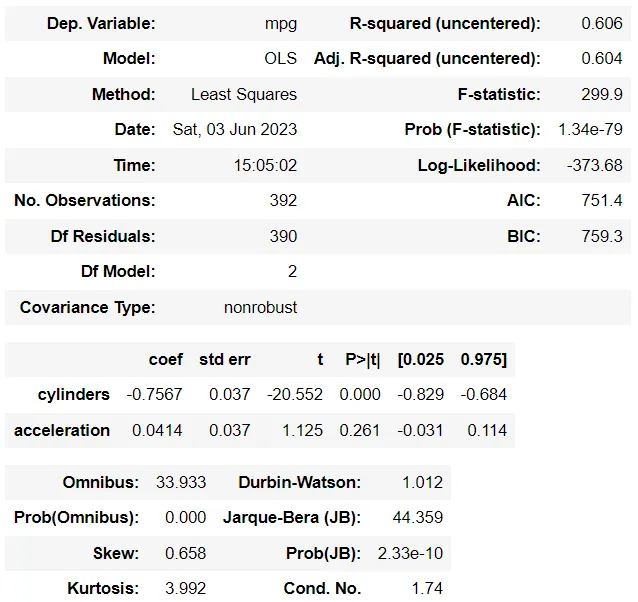
为了比较模型系数的变化,让我们构建新数据集的模型来绘制它们。
y_m1 = df_m1[['mpg']]
X_m1 = df_m1[['cylinders', 'acceleration']]
lm_m1 = sm.OLS(y_m1, X_m1)
model_m1 = lm_m1.fit()
model_m1.summary()
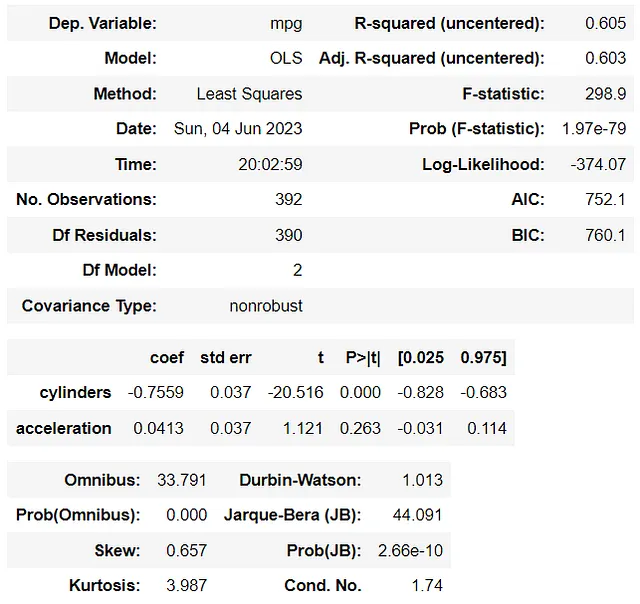
接下来,对具有高度相关预测变量的第二个模型进行相同的处理。
y_m2 = df_m2[['mpg']]
X_m2 = df_m2[['cylinders', 'displacement']]
lm_m2 = sm.OLS(y_m2, X_m2)
model_m2 = lm_m2.fit()
model_m2.summary()
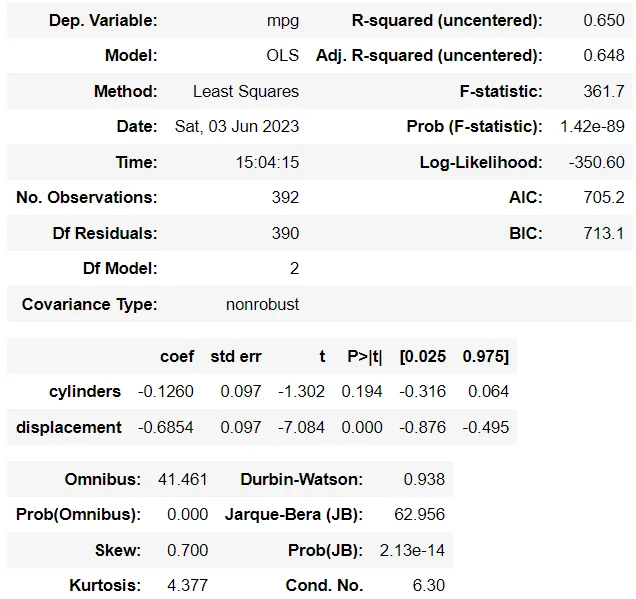
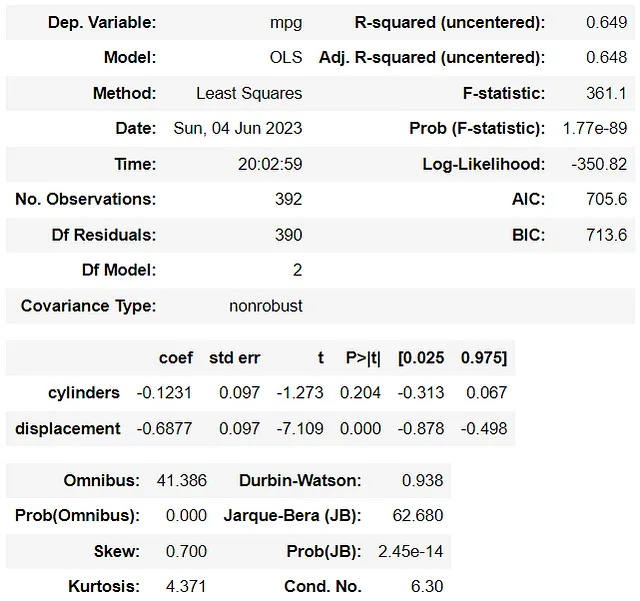
从上面的表格中,它们的系数似乎有一些变化。但是,这是因为我们随机修改了数据集中的一行。这不足以,并且为时过早地假设多重共线性会影响模型系数。
通过我们迄今为止所做的概念和代码,Python中的for循环函数将被应用于逐行修改值。然后,将绝对系数变化与原始模型进行比较。
从定义比较系数值的函数开始。
def compare_cef(base_m, mod_m, col): val_base = base_m.summary().tables[1].as_html() ml = pd.read_html(val_base, header=0, index_col=0)[0] val_diff = mod_m.summary().tables[1].as_html() ml_m = pd.read_html(val_diff, header=0, index_col=0)[0] df_ = pd.DataFrame(abs(ml.iloc[:,0] - ml_m.iloc[:,0])) df_.rename(columns={'coef': 'r '+str(col+1)}, inplace=True) return df_使用for循环函数逐行修改行。
keep_df1, keep_df2 = [], []for n in range(len(df)): mod_list = [i*1.25 for i in df.iloc[n,:]] df_m = df.copy() df_m.iloc[n] = mod_list df_m1 = df_m[['mpg', 'cylinders', 'acceleration']] y_m1, X_m1 = df_m1[['mpg']], df_m1[['cylinders', 'acceleration']] lm_m1 = sm.OLS(y_m1, X_m1) mdl_m1 = lm_m1.fit() df_m2 = df_m[['mpg', 'cylinders', 'displacement']] y_m2, X_m2 = df_m2[['mpg']], df_m2[['cylinders', 'displacement']] lm_m2 = sm.OLS(y_m2, X_m2) mdl_m2 = lm_m2.fit() df_diff1 = compare_cef(model1, mdl_m1, n) df_diff2 = compare_cef(model2, mdl_m2, n) keep_df1.append(df_diff1) keep_df2.append(df_diff2) df_t1 = pd.concat(keep_df1, axis=1)df_t2 = pd.concat(keep_df2, axis=1)df_t = pd.concat([df_t1, df_t2], axis=0)df_t
用热图可视化所获得的DataFrame。
plt.figure(figsize=(16,2.5))sns.heatmap(df_t, cmap='Reds')plt.xticks([])plt.show()
从热图中可以看出,前两行展示了具有适度相关变量的模型之间系数的绝对变化,这是针对数据的微小变化之前和之后的比较。
最后两行比较了具有高度相关变量的模型之间的同样的东西,这是在数据稍微改动之后进行的。
可以解释为,具有高度相关预测变量的模型在数据发生变化时,系数更不稳定,而具有适度相关预测变量的模型则受到较小影响。
绘制多元回归模型
为了可视化系数的变化,例如,我将修改数据集中的一行,创建一个新的模型并将其与原始模型一起绘制。新模型将使用“viridis”颜色板(黄绿色)显示,而原始模型则使用默认颜色(橙蓝色)绘制。
如果您想手动选择和修改其他行,请更改以下代码。
x = 6 #选择行号mod_list = [i*1.25 for i in df.iloc[x,:]]df_m = df.copy()df_m.iloc[x] = mod_listy_m1 = df_m[['mpg']]X_m1 = df_m[['cylinders', 'acceleration']]lm_m1 = sm.OLS(y_m1, X_m1)model_m1 = lm_m1.fit()y_m2 = df_m[['mpg']]X_m2 = df_m[['cylinders', 'displacement']]lm_m2 = sm.OLS(y_m2, X_m2)model_m2 = lm_m2.fit()运行并绘制具有适度相关性预测变量的多元回归模型。
# 运行模型pred_m1 = model_m1.predict(np.c_[xx1.ravel(), yy1.ravel()])pred_m1 = pred_m1.reshape(xx1.shape)# 绘制结果fig = px.scatter_3d(df_m, x='cylinders', y='acceleration', z='mpg')fig.update_traces(marker=dict(size=5))fig.add_traces(go.Surface(x=xr1, y=yr1, z=pred1, name='pred'))fig.add_traces(go.Surface(x=xr1, y=yr1, z=pred_m1, name='pred_m1', colorscale = 'viridis_r'))fig.show()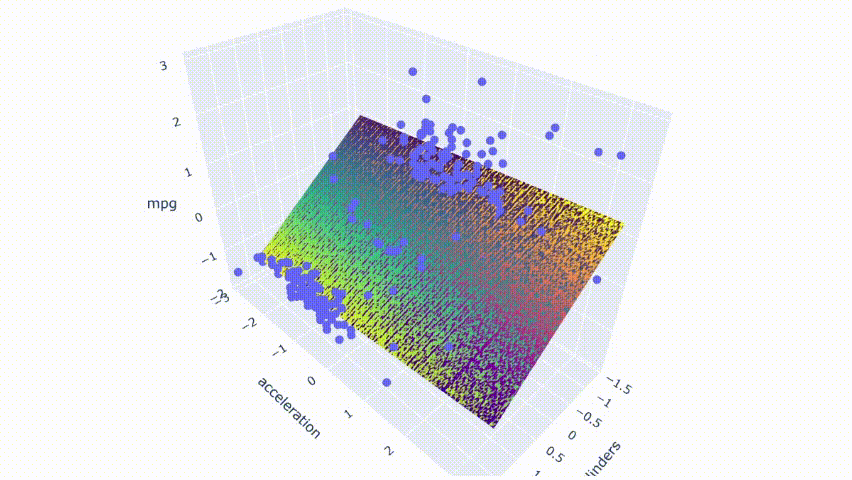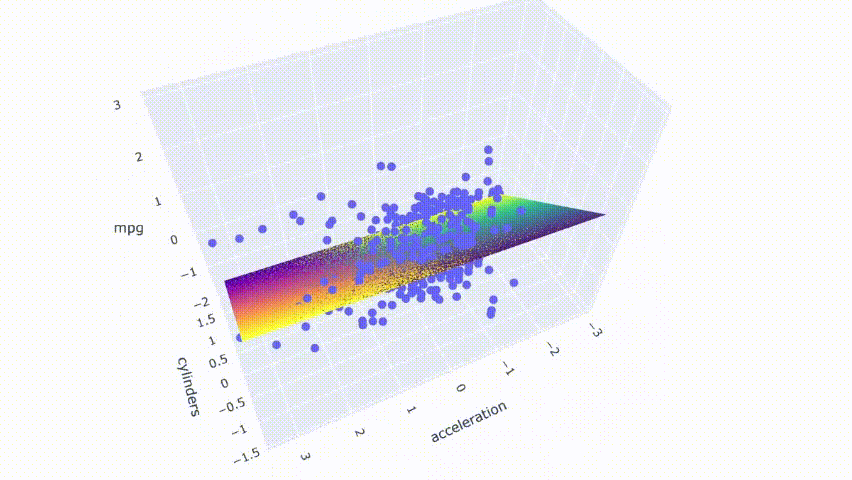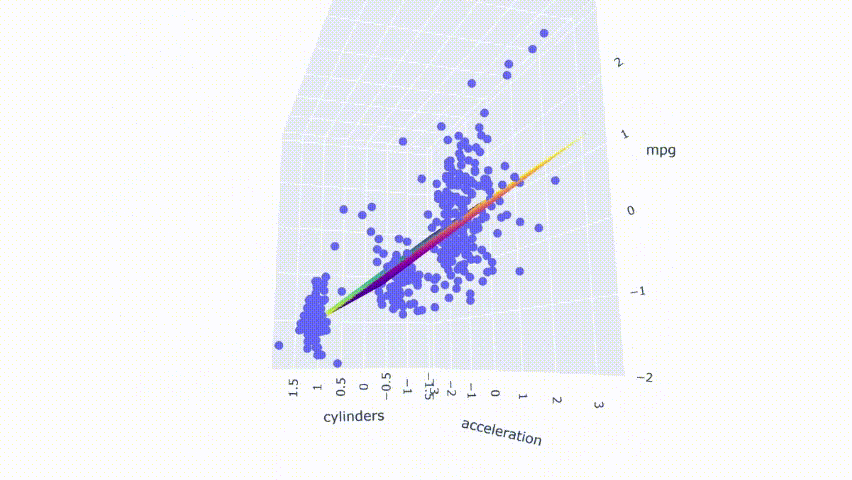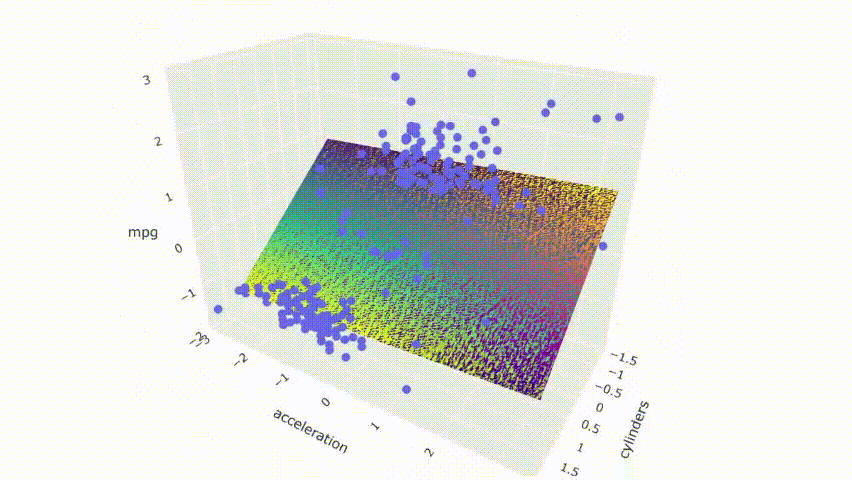
可以看到两个模型重叠,因为两个平面的颜色在结果中混合在一起。最后,使用具有适度相关性预测变量的模型进行相同的过程。
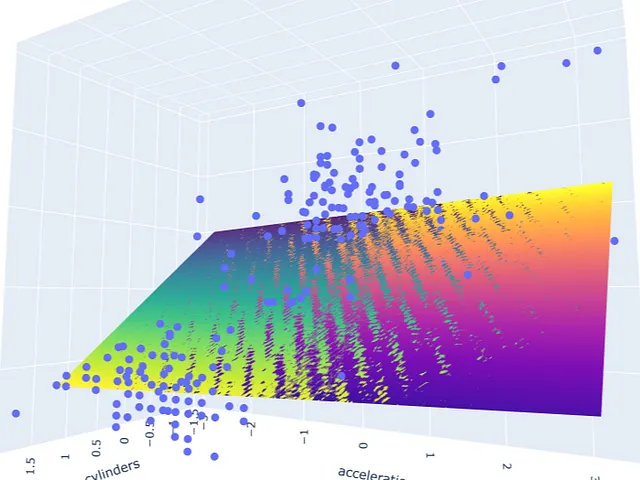
# 运行模型pred_m2 = model_m2.predict(np.c_[xx2.ravel(), yy2.ravel()])pred_m2 = pred_m2.reshape(xx2.shape)# 绘制结果fig = px.scatter_3d(df_m, x='cylinders', y='displacement', z='mpg')fig.update_traces(marker=dict(size=5))fig.add_traces(go.Surface(x=xr2, y=yr2, z=pred2, name='pred'))fig.add_traces(go.Surface(x=xr2, y=yr2, z=pred_m2, name='pred_m2', colorscale = 'viridis_r'))fig.show()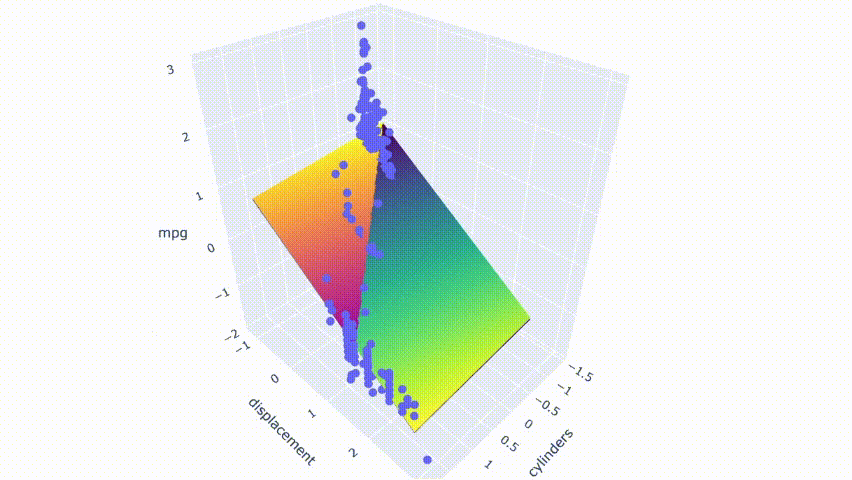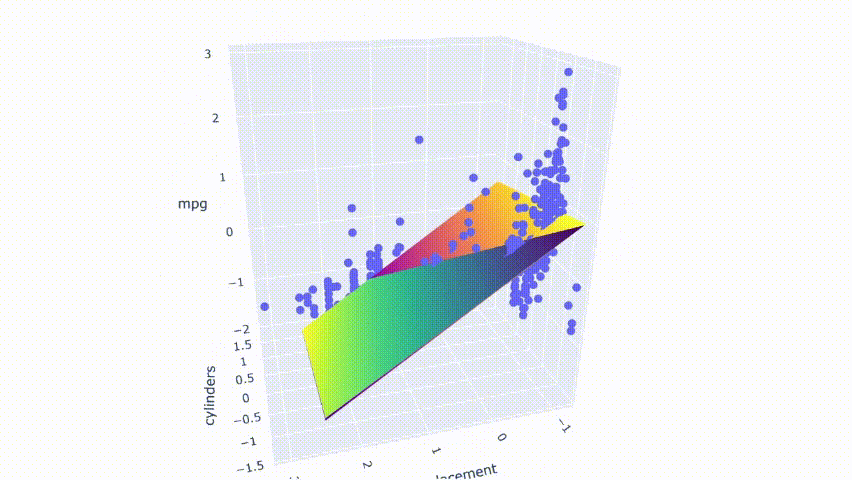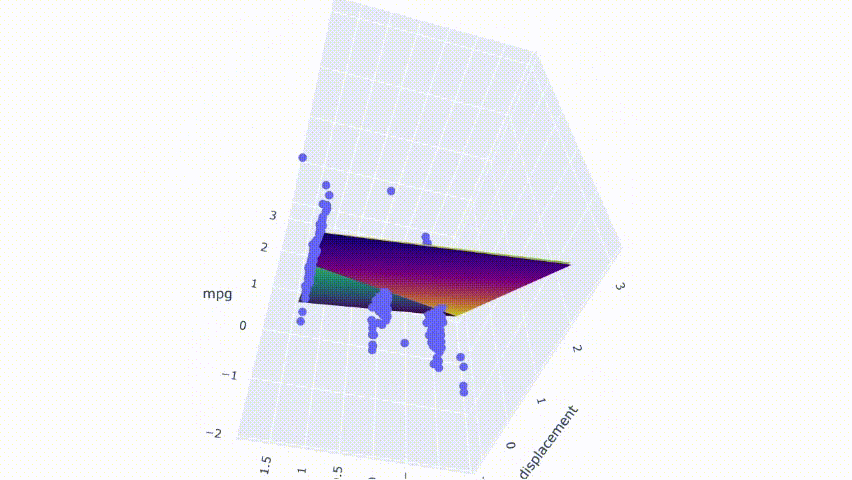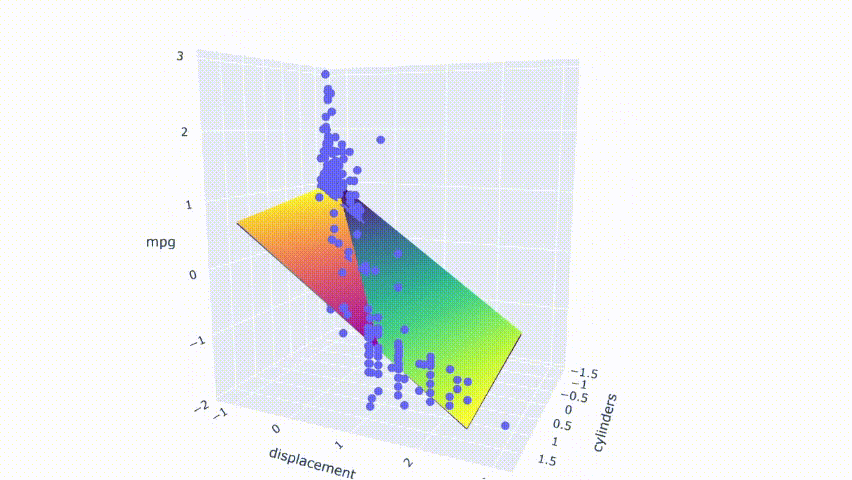
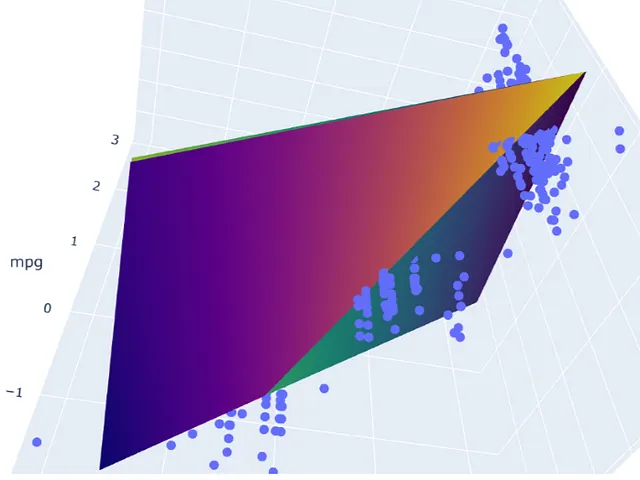
结果显示两个模型不完全重叠。它们相互交错并在模型之间产生了一点间隙。
请注意,这些图是通过随机修改数据集中的一行来选择的。第一个模型不是没有多重共线性的。它仍然具有适度相关性的预测变量。从热图中可以看出,它在某些情况下也会受到变化的影响。但是,与第二个模型相比,变化产生的影响较小。
总结
本文应用数据可视化来比较两个模型,一个具有适度相关性的预测变量,另一个具有高度相关性的预测变量,以表达多重共线性对多元回归模型的影响。还修改了原始数据以查看哪些模型会更容易受到数据的微小变化的影响。
结果表明,模型具有高度相关性的预测变量越多,模型系数受不稳定变化的影响就越大。因此,对具有多重共线性问题的模型中的每个预测变量进行解释可能很困难。
以下是您可能会感兴趣的我的数据可视化文章:
- 使用Python处理多个时间序列数据的8种可视化方法(链接)
- 比条形图更引人注目的9种Python可视化方法(链接)
- 表达随时间排名变化的7种Python可视化方法(链接)
- Battle Royale-比较用于交互式金融图表的7个Python库(链接)
参考文献
- Wikimedia Foundation. (2023, February 22). Multicollinearity . Wikipedia. https://en.wikipedia.org/wiki/Multicollinearity
- Choueiry, G. (2020, June 1). Quantifying health . QUANTIFYING HEALTH. https://quantifyinghealth.com/vif-threshold/
- Frost, J. (2023, January 29). Multicollinearity in regression analysis: Problems, detection, and solutions . Statistics By Jim. https://statisticsbyjim.com/regression/multicollinearity-in-regression-analysis/
- Rob Taylor, P. (2022, December 1). Multicollinearity: Problem, or not? 小猪AI. https://towardsdatascience.com/multicollinearity-problem-or-not-d4bd7a9cfb91
- Stephanie. (2020, December 16). Variance inflation factor . Statistics How To. https://www.statisticshowto.com/variance-inflation-factor/
- Cars data — dataset by dataman-udit . data.world. (2020, May 24). https://data.world/dataman-udit/cars-data