通过人类关注预测模型实现令人愉悦的用户体验
Google Research的高级研究科学家Junfeng He和员工研究科学家Kai Kohlhoff发布了这篇文章。
人类有着惊人的能力,可以接受大量信息(估计每秒输入视网膜的信息量为10 10比特),并且能够选择性地关注一些与任务相关且有趣的区域以进行进一步的处理(例如记忆、理解、行动)。因此,对人类注意力的建模(其结果通常被称为显着性模型)一直是神经科学、心理学、人机交互(HCI)和计算机视觉等领域的研究兴趣所在。预测哪些区域可能吸引注意力在众多重要应用领域具有重要意义,例如图形、摄影、图像压缩和处理以及视觉质量的测量。
我们之前曾讨论过使用机器学习和基于智能手机的凝视估计加速眼动研究的可能性,而这种技术以前需要高达每台设备3万美元的专门硬件。相关研究包括“看着说话”,它帮助有辅助需求(例如患有肌萎缩性侧索硬化症的人)的用户通过凝视与他人交流,以及最近公布的“差分隐私热图”技术,用于计算热图(例如注意力),同时保护用户的隐私。
在本文中,我们介绍两篇论文(一篇来自CVPR 2022,一篇刚刚被接受到CVPR 2023),强调我们最近在人类注意力建模领域的研究:“用于减少视觉干扰的深度显着性先验”和“从独特的视角学习:用户感知显着性建模”,以及与图像压缩相关的显着性驱动渐进式加载的最新研究(1,2)。我们展示了人类注意力的预测模型如何实现令人愉悦的用户体验,例如图像编辑以减少视觉混乱、干扰或瑕疵,图像压缩以更快地加载网页或应用程序,以及将ML模型引导到更直观的类人解释和模型性能。我们专注于图像编辑和图像压缩,并讨论了在这些应用程序的背景下建模的最新进展。
基于注意力的图像编辑
人类注意力模型通常将图像作为输入(例如自然图像或网页截图),并预测热图作为输出。在热图上评估图像与注意力数据的一致性,通常是通过眼动仪或鼠标悬停/点击来收集的。以前的模型利用视觉线索的手工制作特征,例如颜色/亮度对比度、边缘和形状,而更近期的方法则基于深度神经网络自动学习区分性特征,从卷积和循环神经网络到更近期的视觉变换器网络。
在“用于减少视觉干扰的深度显着性先验”(有关此项目网站的更多信息),我们利用深度显着性模型进行戏剧性而又视觉逼真的编辑,可以显著改变观察者对不同图像区域的注意力。例如,去除背景中的干扰物可以减少照片中的杂乱,从而增加用户满意度。同样,在视频会议中,减少背景中的杂乱可能增加对主讲人的关注(示例演示在此处)。
为了探索可以实现哪些类型的编辑效果以及这些效果如何影响观众的注意力,我们开发了一个优化框架,用于使用可微、预测性显着性模型来指导图像中的视觉注意力。我们的方法采用最先进的深度显着性模型。给定输入图像和表示干扰器区域的二进制掩码,掩码内的像素将在预测性显着性模型的指导下进行编辑,以降低掩码区域内的显着性。为确保编辑后的图像自然而逼真,我们精心选择了四个图像编辑运算符:两个标准的图像编辑操作,即重新着色和图像变形(移位);两个学习的运算符(我们没有明确定义编辑操作),即多层卷积滤波器和生成模型(GAN)。
借助这些运算符,我们的框架可以产生各种强大的效果,如下图所示,包括重新着色、修复、伪装、对象编辑或插入以及面部特征编辑。重要的是,所有这些效果都仅由单个、预先训练的显着性模型驱动,没有任何额外的监督或训练。请注意,我们的目标不是与专门用于产生每个效果的方法竞争,而是展示多个编辑操作如何受深度显着性模型内嵌的知识所指导。
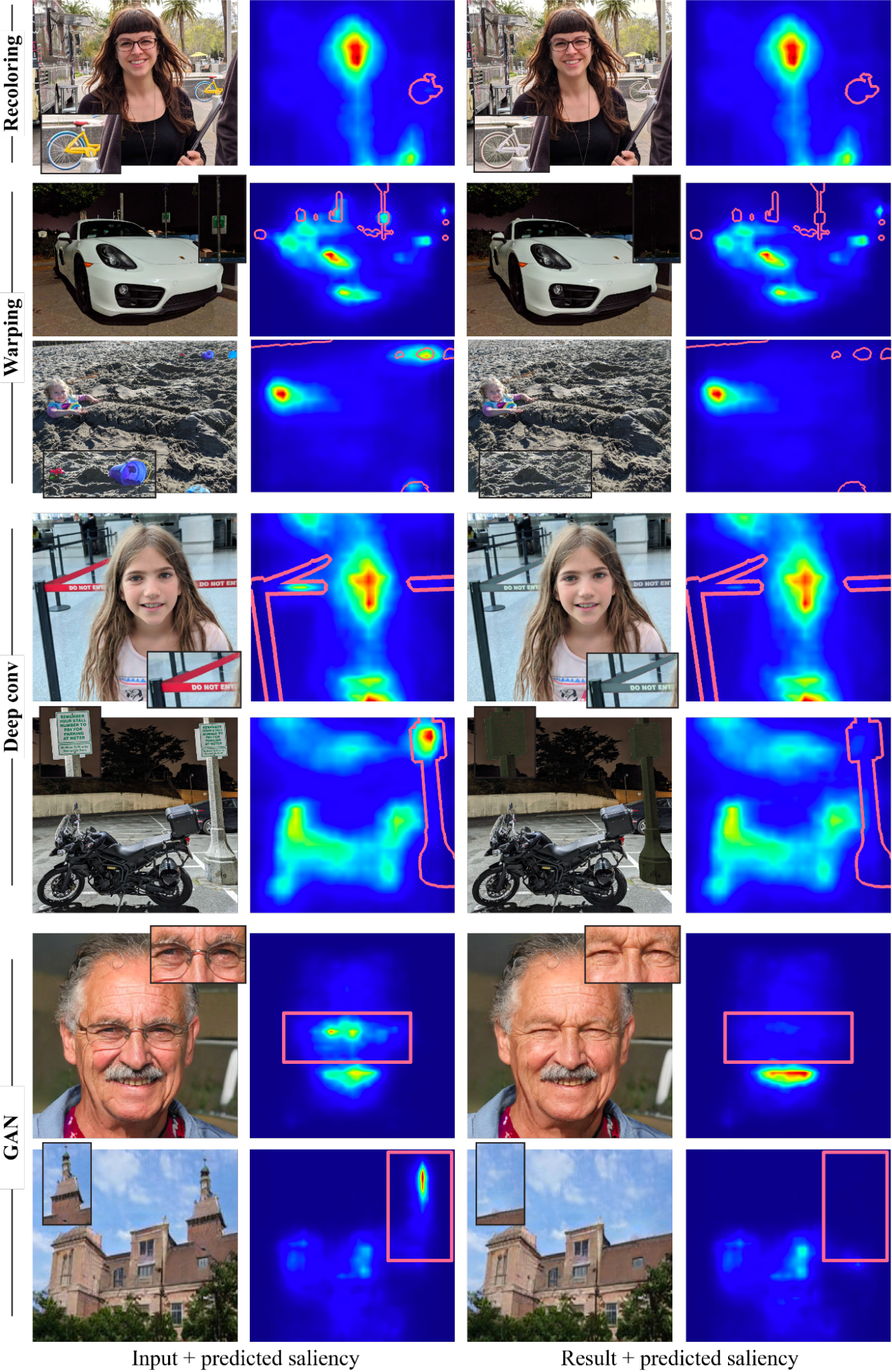 |
| 减少视觉干扰的示例,由具有几个运算符的显着性模型指导。在每个示例中,干扰区域在显着性图上标记为红色边框。 |
用户感知显著性建模丰富体验
以往的研究假设整个人群只有一个显著性模型。然而,人类的注意力在个体之间存在差异——尽管显著线索的检测相当一致,但它们的顺序、解释和凝视分布可能大不相同。这为为个人或群体创建个性化用户体验提供了机会。在“从独特视角学习:用户感知显著性建模”中,我们介绍了一种用户感知显著性模型,它是第一个可以预测一个用户、一组用户和整个人群的关注点的模型。
如下图所示,该模型的核心是将每个参与者的视觉喜好与每个用户的关注点图和自适应的用户蒙版相结合。这需要在训练数据中提供每个用户的关注注释,例如,自然图像的OSIE移动凝视数据集;Web页面的FiWI和WebSaliency数据集。该模型预测每个用户关注的热图,以编码个体的关注模式,而不是预测代表所有用户关注的单个显著性地图。此外,该模型采用用户蒙版(大小等于参与者数量的二进制向量)来指示当前样本中参与者的存在,从而可以选择一组参与者并将其偏好组合成一个热图。
 |
| 用户感知显著性模型框架概览。示例图像来自OSIE图像集。 |
在推理过程中,用户蒙版允许针对任意参与者组合进行预测。在下图中,前两行是两个不同参与者组(每组三人)在图像上的关注预测。传统的关注预测模型将预测相同的关注热图。我们的模型可以区分两个组(例如,第二组比第一组更关注食物而不是脸部)。同样地,最后两行是针对两个不同参与者在网页上的预测,我们的模型显示不同的偏好(例如,第二个参与者比第一个参与者更关注左侧区域)。
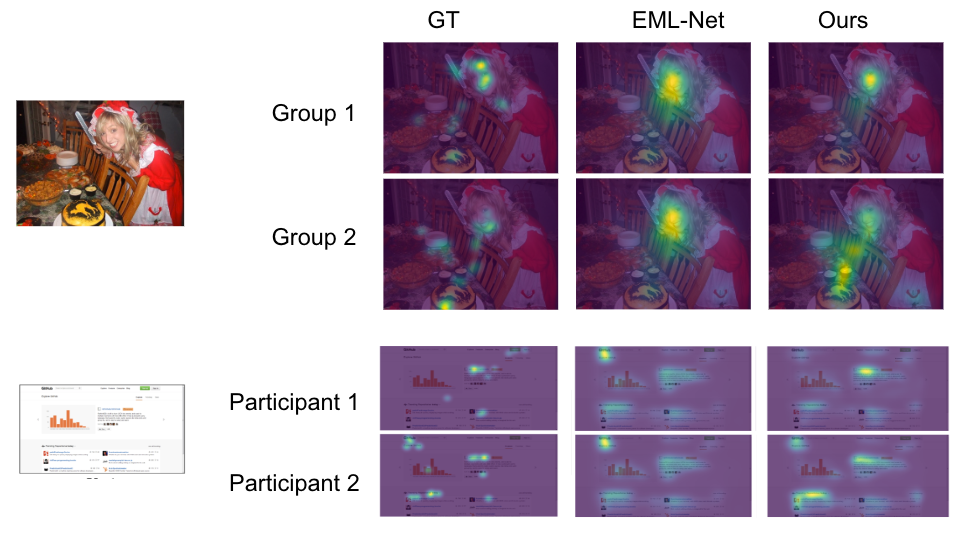 |
| 预测的关注点 vs. 真值(GT)。EML-Net:来自最先进模型的预测,将为两个参与者/组的预测相同。我们的模型:来自我们提出的用户感知显著性模型的预测,可以正确预测每个参与者/组的独特偏好。第一幅图像来自OSIE图像集,第二幅图像来自FiWI。 |
以显著特征为中心的渐进式图像解码
除了图像编辑外,人类注意力模型还可以提高用户的浏览体验。在浏览带有图像的网页时,最令人沮丧和恼人的用户体验之一是等待网页加载图像,尤其是在网络连接较差的情况下。在这种情况下,改善用户体验的一种方法是使用渐进式图像解码,该方法解码并显示逐渐高分辨率的图像部分,直到完整分辨率图像就绪。渐进式解码通常按顺序进行(例如,从左到右,从上到下)。有了预测性的注意力模型(1,2),我们可以根据显著性解码图像,这样就可以首先发送显示最显著区域细节所需的数据。例如,在肖像中,可以优先处理面部的字节,而不是模糊的背景。因此,用户可以更早地感知到更好的图像质量,并且等待时间显著缩短。有关更多详细信息,请参阅我们的开源博客文章(文章1,文章2)。因此,预测性注意力模型可以帮助图像压缩、更快加载带有图像的网页,提高大型图像和流媒体/VR应用程序的渲染质量。
结论
我们展示了如何通过人类注意力的预测模型,在图像编辑等应用中,为用户提供愉悦的用户体验,这些应用可以为用户减少图像或照片中的混乱、干扰或伪影,并且渐进式图像解码可以大大减少用户等待图像完全渲染的时间。我们的用户感知显著性模型可以进一步为个人用户或组提供个性化的上述应用,从而实现更丰富、更独特的体验。
预测性注意力模型的另一个有趣方向是,它们是否可以帮助提高计算机视觉模型在目标分类或检测等任务中的鲁棒性。例如,在“教师生成的空间注意力标签提高对比模型的鲁棒性和准确度”中,我们展示了预测人类注意力模型可以指导对比学习模型实现更好的表示,并提高分类任务(在ImageNet和ImageNet-C数据集上)的准确性/鲁棒性。在这个方向上的进一步研究可以实现应用,例如使用放射科医师对医学图像的注意力来改善健康筛查或诊断,或者使用人类在复杂驾驶场景中的注意力来指导自动驾驶系统。
致谢
这项工作涉及到软件工程师、研究人员和跨职能贡献者组成的多学科团队的协作努力。我们要感谢所有论文/研究的共同作者,包括Kfir Aberman、Gamaleldin F. Elsayed、Moritz Firsching、Shi Chen、Nachiappan Valliappan、Yushi Yao、Chang Ye、Yossi Gandelsman、Inbar Mosseri、David E. Jacobes、Yael Pritch、Shaolei Shen和Xinyu Ye。我们还要感谢团队成员Oscar Ramirez、Venky Ramachandran和Tim Fujita的帮助。最后,我们要感谢Vidhya Navalpakkam在发起和监督这项工作中的技术领导力。





