10个在Stack Overflow上最常见的Python列表问题
来自现实生活的问题。

Stack Overflow 是一个信息宝库,在这里你可以找到关于软件、编码、数据科学和许多其他学科的成千上万个问题和答案。
如果你问内容创作者,他们预计学生在解决问题时会犯哪些错误,或者学生可能难以理解什么,你会惊讶地发现,内容创作者往往无法准确猜测。
我提到这个是为了说明 Stack Overflow 上的信息有多么宝贵。Stack Overflow 上的问题都来自于人们在工作中解决问题或者在使用软件工具时犯的错误。因此,Stack Overflow 很准确地反映了现实生活中的挑战。
在本文中,我们将介绍 Stack Overflow 上关于 Python 列表问题的前 10 个最常见的问题。
列表是 Python 中的内置数据结构。它由方括号中的数据点集合表示,可用于存储不同类型的数据。
我使用“python”和“list”标签搜索了这些问题,并按分数进行了排序。
让我们开始吧。
1. 在 ‘for’ 循环中访问索引
这个问题可以推广到其他可迭代对象,比如元组和字符串。它基本上是在问如何获取项的索引以及项本身。
回答这个问题最简洁和符合 Python 风格的方法是使用 enumerate 函数,它返回一个包含计数和从可迭代对象中迭代得到的值的元组。
names = ["John", "Jane", "Ashley"]for idx, x in enumerate(names): print(idx, x)# 输出0 John1 Jane2 Ashley计数默认从 0 开始,但可以使用 start 参数进行更改。
names = ["John", "Jane", "Ashley"]for idx, x in enumerate(names, start=10): print(idx, x)# 输出10 John11 Jane12 Ashley2. 如何将列表列表转换为平面列表?
下图说明了这个问题在问什么:
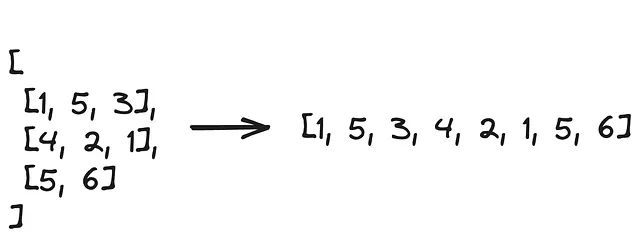
你可以使用列表推导式进行如下转换:
# 使用列表推导式mylist = [ [1, 5, 3], [4, 2, 1], [5, 6]]myflatlist = [item for sublist in mylist for item in sublist]print(myflatlist)# 输出[1, 5, 3, 4, 2, 1, 5, 6]上面的列表推导式也可以写成嵌套的 for 循环。这种写法更直观,更容易理解,但是当处理大型列表时,列表推导式的性能更好。
# 使用 for 循环mylist = [ [1, 5, 3], [4, 2, 1], [5, 6]]myflatlist = []for sublist in mylist: for item in sublist: myflatlist.append(item) print(myflatlist)# 输出[1, 5, 3, 4, 2, 1, 5, 6]如果你使用 Pandas,explode 函数可以很轻松地完成这个展平操作,但是你需要先将列表转换为 Pandas series。如果你希望最终输出是一个列表,那么可以使用列表构造函数将 explode 函数的输出转换为列表。
# 使用explode函数
import pandas as pd
myflatlist = list(pd.Series(mylist).explode())
print(myflatlist)
# 输出
[1, 5, 3, 4, 2, 1, 5, 6]3. 查找列表中项的索引
项的索引可以用于访问列表中的项。以下是一个示例来展示这种情况:
names = ["John", "Jane", "Ashley", "Max", "Jane"]
# 索引为2的项(即第三个项)
names[2]
# 输出
'Ashley'索引为2的项是第三个项,因为索引从0开始。
问题是如何找到该索引,可以使用内置的index方法来实现。
names = ["John", "Jane", "Ashley", "Max", "Jane"]
names.index("Ashley")
# 输出
2从开头开始,index方法按顺序搜索列表,直到找到匹配项,然后停止。因此,在有多个相同项的情况下,index方法返回第一个项的索引。
如果想要获取所有出现的索引,可以使用列表推导中的enumerate函数,如下所示:
names = ["John", "Jane", "Ashley", "Max", "Jane", "Abby", "Jane"]
janes_indexes = [idx for idx, item in enumerate(names) if item == "Jane"]
print(janes_indexes)
# 输出
[1, 4, 6]它返回给定项的索引值列表。
4. 如何在Python中连接两个列表?
可以通过使用“+”运算符简单地连接列表。
list_1 = [1, 3, 4]
list_2 = [12, 23, 30]
combined = list_1 + list_2
print(combined)
# 输出
[1, 3, 4, 12, 23, 30]也可以使用extend函数。它不会返回一个合并的列表,而是将第二个列表中的项扩展到第一个列表中。
list_1 = [1, 3, 4]
list_2 = [12, 23, 30]
list_1.extend(list_2)
print(list_1) # list_1现在是合并后的列表,list_2保持不变
# 输出
[1, 3, 4, 12, 23, 30]5. 如何检查列表是否为空?
有不同的方法可以检查列表是否为空。
一种选择是利用空序列和集合为False的事实,在if语句中用于检查列表是否为空。
names = []
if not names:
print("列表不为空!")
# 输出
列表不为空!还可以使用内置的len函数,它返回列表中的项数。如果这个值为0,则列表为空。
len(names)
# 输出
06. Python的列表方法append和extend之间的区别是什么?
append方法用于向列表中添加新的项。
names = ["Jane", "Max", "Ashley"]
names.append("John")
print(names)
# 输出
['Jane', 'Max', 'Ashley', 'John']无论值的类型是什么,它都会作为新的项添加到列表中。因此,如果附加一个值的列表,该列表就变成了一个单独的项。
names = ["Jane", "Max", "Ashley"]
new_names = ["John", "Adam"]
names.append(new_names)
print(names)
# 输出
['Jane', 'Max', 'Ashley', ['John', 'Adam']]上面的名字列表包含4个项目,因为“John”和“Adam”被作为一个列表附加到了名字列表中,所以“John”和“Adam”不是名字列表的项目。
让我们检查“John”是否存在于名字列表中:
"John" in names# 输出False这就是extend函数发挥作用的地方。它将当前列表与新列表中的项目扩展在一起。如果你使用extend函数来执行上面的示例,你会看到“John”和“Adam”作为单独的项目添加到了名字列表中。
names = ["Jane", "Max", "Ashley"]new_names = ["John", "Adam"]names.extend(new_names)print(names)# 输出['Jane', 'Max', 'Ashley', 'John', 'Adam']现在让我们检查“John”是否存在于名字列表中:
"John" in names# 输出True7. 如何将一个列表分割成相等大小的块?
下面的图示说明了这个问题的要求:
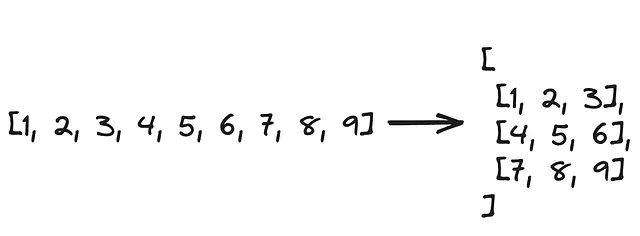
可以使用列表推导式来完成这个任务。
第一步是指定一个块大小,用于确定分割点。
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]chunk_size = 4[mylist[i:i + chunk_size] for i in range(0, len(mylist), chunk_size)]# 输出[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]可以随意尝试不同的块大小,看看输出如何变化。
8. 如何按照字典中的值对字典列表进行排序?
假设你有以下列表,其中包含字典作为其项目。
employees = [ {"name": "Max", "department": "sales"}, {"name": "Jane", "department": "engineering"}, {"name": "Ashley", "department": "hr"}]你想按照名字对项目(即字典)进行排序。可以使用Pandas内置的sorted函数来完成。为了按照名字排序,我们需要使用key参数来指定。
employees_sorted = sorted(employees, key = lambda x: x["name"])employees_sorted# 输出[{'name': 'Ashley', 'department': 'hr'}, {'name': 'Jane', 'department': 'engineering'}, {'name': 'Max', 'department': 'sales'}]key参数定义了如何排序项目。在这种情况下,使用lambda表达式来从字典中提取名字,然后用于排序。
9. 如何获取列表的最后一个元素?
最简单的方法是使用索引。
第一个项目的索引是0。你也可以从末尾开始索引。在这种情况下,第一个项目(即列表的最后一个项目)的索引是-1。
names = ["Jane", "Adam", "Matt", "Jennifer"]names[-1]# 输出'Jennifer'names[0]# 输出'Jane'10. 如何从列表中随机选择一个项目?
Python的random模块可以用于这个任务。
choice方法随机选择一个项目。
import randomnames = ["Jane", "Adam", "Matt", "Jennifer", "Abby"]random.choice(names)# 输出'Matt'如果你想要随机抽取n个项,你可以使用sample方法。
import randomnames = ["Jane", "Adam", "Matt", "Jennifer", "Abby"]random.sample(names, 2) # 随机抽取2个项# 输出['Abby', 'Matt']结论
列表是一个经常使用的数据结构。它是可变的,并且可以存储不同类型的数据,这使得它成为存储和管理数据的理想选择。为了编写高效的Python程序,您需要充分了解列表和其他内置数据结构(例如字典、集合、元组)。
本文中涉及的问题来自人们在使用列表时所面临的挑战。您可能会遇到相同的问题。即使您没有遇到,了解它们也是更好地理解列表特性的重要途径。
您可以成为小猪AI的会员,以解锁我写作的全部内容,以及其他小猪AI的内容。如果您已经是会员,请订阅,以便在我发布新文章时收到电子邮件提醒。
感谢您的阅读。如果您有任何反馈,请随时告诉我。





