使用Python进行数据缩放
如何对数据进行缩放,使其适合模型构建

在机器学习过程中,数据缩放属于数据预处理或特征工程的范畴。在模型构建之前对数据进行缩放可以达到以下效果:
- 缩放确保特征具有相同的值范围
- 缩放确保在模型构建中使用的特征是无量纲的
- 缩放可以用于检测异常值
有几种方法可以对数据进行缩放。最重要的两种缩放技术是归一化和标准化。
使用归一化进行数据缩放
使用归一化对数据进行缩放时,可以使用以下公式来计算转换后的数据:
其中 。
归一化的Python实现
可以使用以下代码在Python中实现使用归一化进行缩放:
from sklearn.preprocessing import Normalizer
norm = Normalizer()
X_norm = norm.fit_transform(data)假设给定数据X的最大值为 。
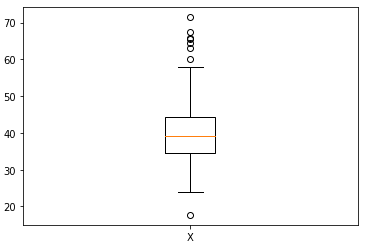
归一化后的X在下图中显示:
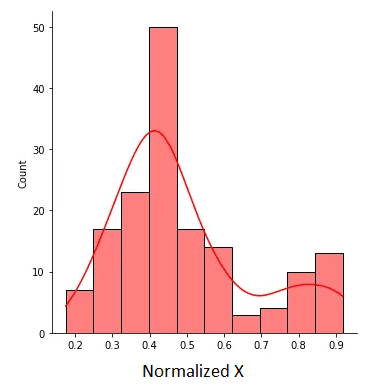 图2. 归一化后的X值介于0和1之间。作者提供的图像。
图2. 归一化后的X值介于0和1之间。作者提供的图像。
使用标准化进行数据缩放
理想情况下,当数据服从正态分布或高斯分布时应使用标准化。可以按以下方式计算标准化后的数据:
这里,是数据的均值,
是标准差。标准化值通常应位于范围[-2, 2],表示95%的置信区间。小于-2或大于2的标准化值可以视为异常值。因此,标准化可用于异常值检测。
标准化的Python实现
可以使用以下代码在Python中实现使用标准化进行缩放:
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(data)使用上述描述的数据,标准化后的数据如下所示:
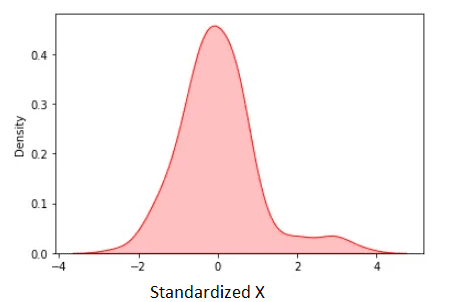 图3. 标准化后的X。作者提供的图像。
图3. 标准化后的X。作者提供的图像。
标准化的均值为零。从上图可以看出,除了一些离群值外,大部分标准化后的数据都位于范围[-2, 2]内。
结论
总之,我们讨论了两种最流行的特征缩放方法,即:标准化和归一化。归一化数据的范围在[0, 1]之间,而标准化数据通常在[-2, 2]之间。标准化的优点在于可以用于异常值检测。Benjamin O. Tayo是一位物理学家、数据科学教育家和作家,同时也是DataScienceHub的所有者。以前,Benjamin曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程和物理学。




