在数据库中的分析:利用SQL的分析函数
学习各种SQL分析函数,如RANK(),NTILE(),CUME_DIST()等,以提升您的数据分析技能到更高的水平

我们都知道在今天的数据驱动世界中,数据分析的重要性以及它如何为我们提供有价值的洞察。但是有时候,对于数据分析师来说,数据分析变得非常具有挑战性和耗时。现在它变得繁忙的主要原因是生成的数据量爆炸以及需要外部工具对其进行复杂分析技术。
但是,如果我们在数据库内部分析数据,并使用大大简化的查询,会怎么样呢?这可以通过使用SQL分析函数来实现。本文将讨论可以在SQL服务器内部执行的各种SQL分析函数,并为我们提供有价值的结果。
- 停止使用 PowerPoint 进行机器学习演示,试试这个替代方案
- 始终学习:人工智能如何防止数据泄露
- 为什么深度学习总是在数组数据上进行?新的人工智能研究引入了“空间函数”,将从数据到函数的处理视为一个整体
这些函数根据一组行计算聚合值,并超越基本的行操作。它们为我们提供了用于排名、时间序列计算、窗口和趋势分析的工具。所以,不浪费任何时间,让我们开始逐一讨论这些函数,并提供一些详细的实例。本教程的先决条件是对SQL查询的基本实际知识。
创建演示表
我们将创建一个演示表,并在该表上应用所有分析函数,以便您可以轻松跟随本教程。
注意: 本教程中讨论的某些函数在SQLite中不存在。所以最好使用MySQL或PostgreSQL服务器。
该表包含几个大学生的数据,包含四列:学生ID、学生姓名、科目和最终成绩(满分100分)。
创建一个包含4列的学生表:
CREATE TABLE students
(
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
subject VARCHAR(30),
final_marks INT
); 现在,我们将向该表中插入一些虚拟数据。
INSERT INTO Students (id, name, subject, final_marks)
VALUES (1, 'John', 'Maths', 89),
(2, 'Kelvin', 'Physics', 67),
(3, 'Peter', 'Chemistry', 78),
(4, 'Saina', 'Maths', 44),
(5, 'Pollard', 'Chemistry', 91),
(6, 'Steve', 'Biology', 88),
(7, 'Jos', 'Physics', 89),
(8, 'Afridi', 'Maths', 97),
(9, 'Ricky', 'Biology', 78),
(10, 'David', 'Chemistry', 93),
(11, 'Jofra', 'Chemistry', 93),
(12, 'James', 'Biology', 65),
(13, 'Adam', 'Maths', 90),
(14, 'Warner', 'Biology', 45),
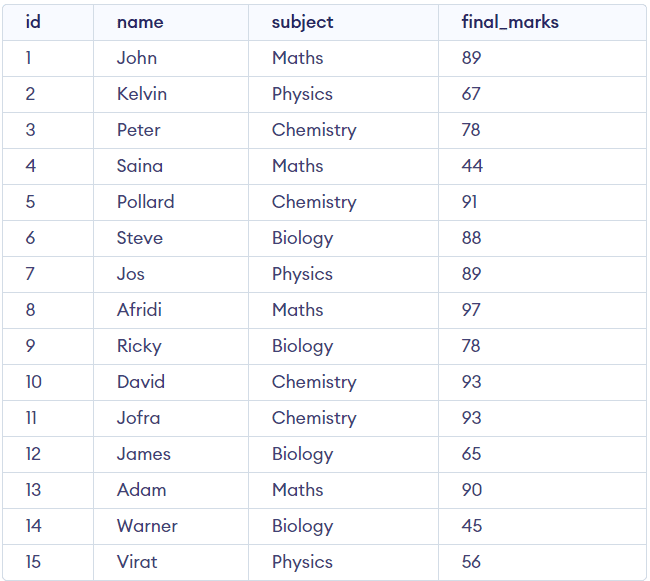
(15, 'Virat', 'Physics', 56);现在我们将可视化我们的表。
SELECT *
FROM students输出:
我们准备好执行分析函数了。
RANK() & DENSE_RANK()
RANK()函数将基于指定的顺序为每个分区内的每一行分配一个特定的排名。如果在同一分区内的行具有相同的值,则它们被赋予相同的排名。
让我们通过以下示例更清楚地理解它。
SELECT *,
Rank()
OVER (
ORDER BY final_marks DESC) AS 'ranks'
FROM students;输出:
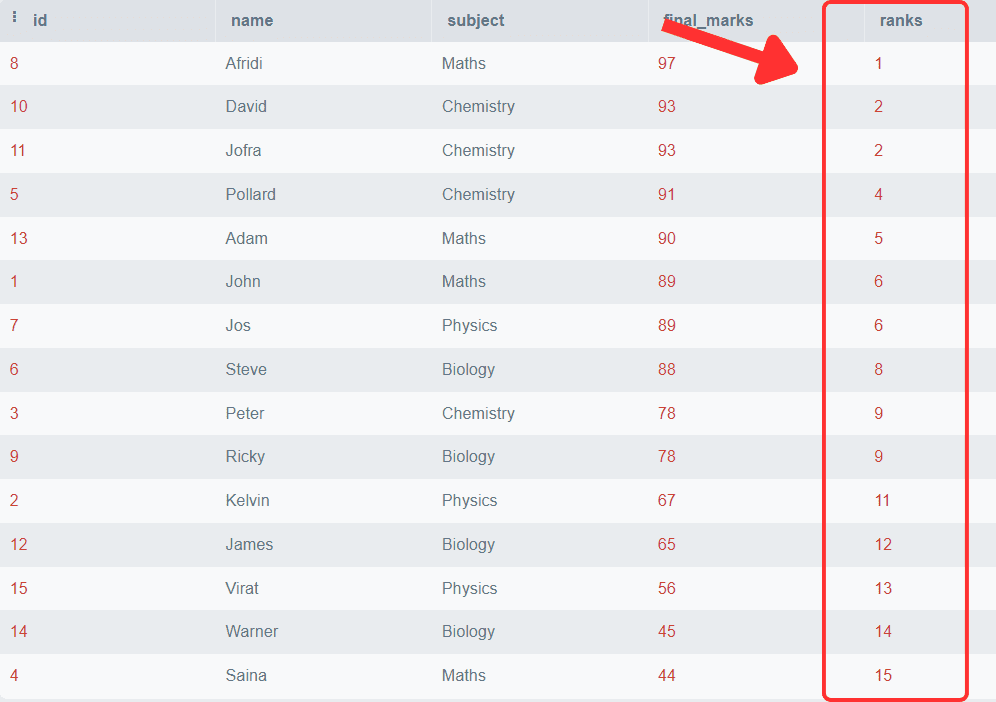
您可以观察到最终分数按降序排列,并且每一行都关联着一个特定的排名。您还可以观察到具有相同分数的学生获得相同的排名,并且在重复行之后,下一个排名被跳过。
我们还可以找到每个科目的前几名,即我们可以根据科目对排名进行分区。让我们看看如何做到这一点。
SELECT *,
Rank()
OVER (
PARTITION BY subject
ORDER BY final_marks DESC) AS 'ranks'
FROM students;输出:
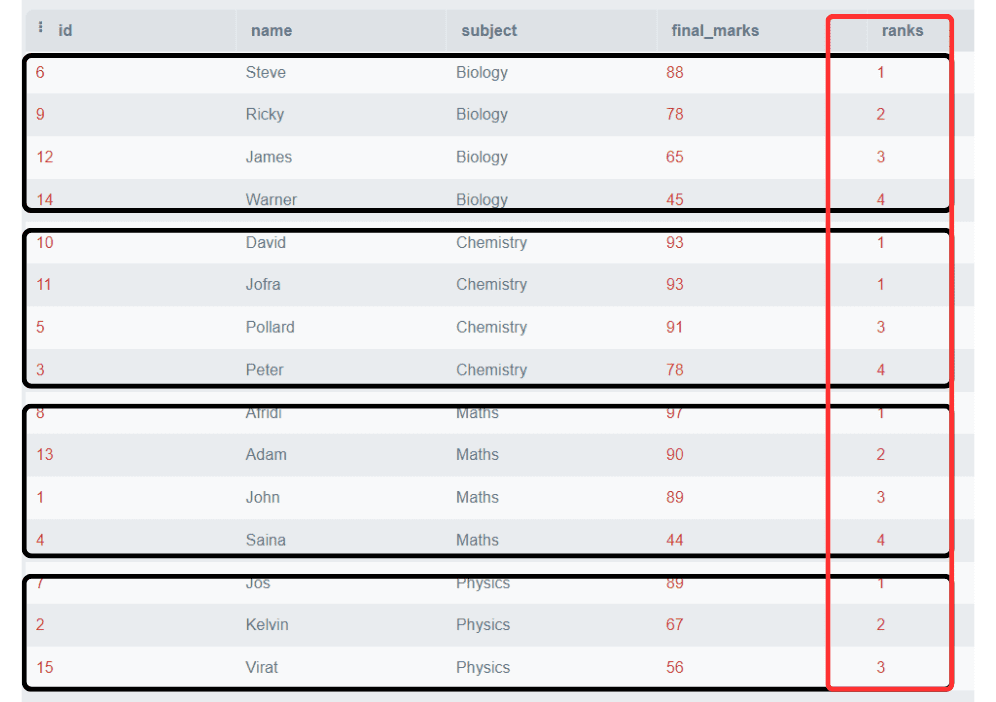
在这个例子中,我们根据科目对排名进行了分区,每个科目都分别分配了排名。
注意:请注意,化学科目中有两个学生获得了相同的分数,排名为1,而下一行的排名直接从3开始。跳过了排名为2的。
这是RANK()函数的特性,它并不总是必须按顺序产生排名。下一个排名将是前一个排名和重复数字之和。
为了解决这个问题,引入了DENSE_RANK(),它的工作方式类似于RANK()函数,但它总是按顺序分配排名。请参考以下示例:
SELECT *,
DENSE_RANK()
OVER (
PARTITION BY subject
ORDER BY final_marks DESC) AS 'ranks'
FROM students;输出:
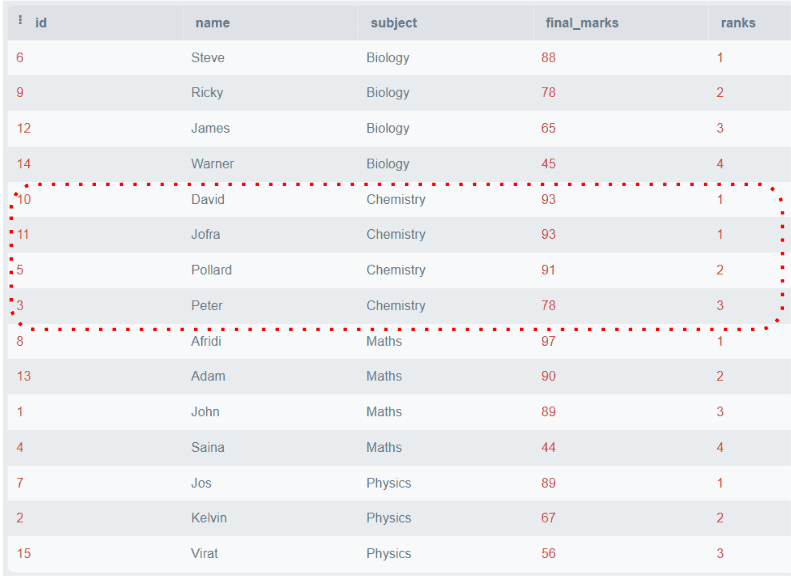 上图显示了所有排名都是连续的,即使相同分数在同一分区中。
上图显示了所有排名都是连续的,即使相同分数在同一分区中。
NTILE()
NTILE()函数用于将行分成指定数量(N)的大致相等大小的桶。每一行被分配一个从1到N(桶的总数)的桶号。
我们还可以在特定的分区或排序上应用NTILE()函数,这些分区或排序在PARTITION BY和ORDER BY子句中指定。
假设N不能完全被行数整除。那么函数将创建大小不同的桶,差值为1。
语法:
NTILE(n) OVER (PARTITION BY c1, c2 ORDER BY c3)NTILE()函数有一个必需的参数N,即桶的数量,还有一些可选的参数,如PARTITION BY和ORDER BY子句。 NTILE()将根据这些子句指定的顺序划分行。
让我们以考虑我们的“学生”表的例子为例。假设我们想根据他们的最终成绩将学生分成几个组。我们将创建三个组。第一组将包含最高分的学生。第二组将包含所有中等生,第三组将包含低分学生。
SELECT *,
NTILE(3)
OVER (
ORDER BY final_marks DESC) AS bucket
FROM students; 输出:
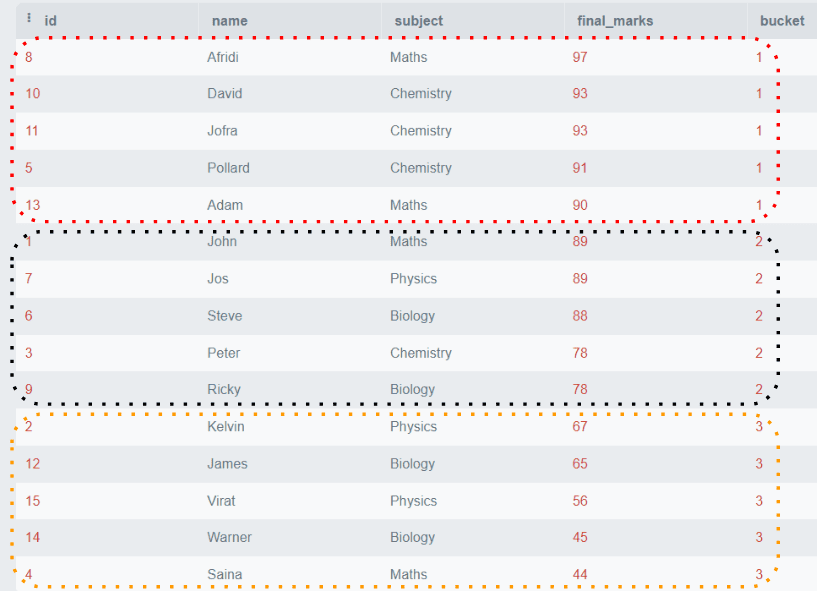
上面的例子显示,所有行都按final_marks排序,并分为包含每组五行的三个组。
NTILE()在我们想根据某些指定的标准将一些数据分成相等的组时非常有用,例如基于购买的项目进行客户分割或对员工绩效进行分类等。
CUME_DIST()
CUME_DIST()函数找到每一行中某个值在指定的分区或排序中的累积分布。累积分布函数(CDF)表示随机变量X小于等于x的概率。它用F(x)表示,其数学公式表示为:
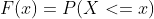
P(x)是概率分布函数。
简单地说,CUME_DIST()函数返回值小于等于当前行值的行的百分比。它有助于分析数据的分布以及一个值在集合中的相对位置。
SELECT *,
CUME_DIST()
OVER (
ORDER BY final_marks) AS cum_dis
FROM students; 输出:
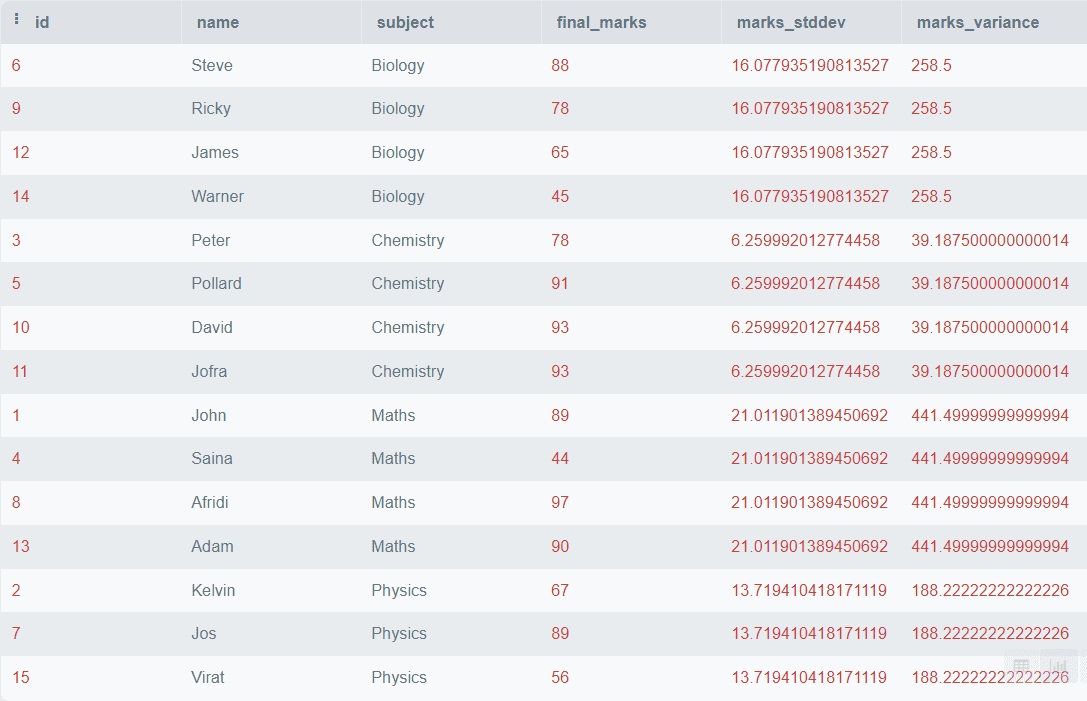
上面的代码将根据 final_marks 对所有行进行排序,并找到累积分布,但如果您想根据科目对数据进行分区,可以使用 PARTITION BY 子句。下面是如何执行的示例。
SELECT *,
CUME_DIST()
OVER (
PARTITION BY subject
ORDER BY final_marks) AS cum_dis
FROM students; 输出:
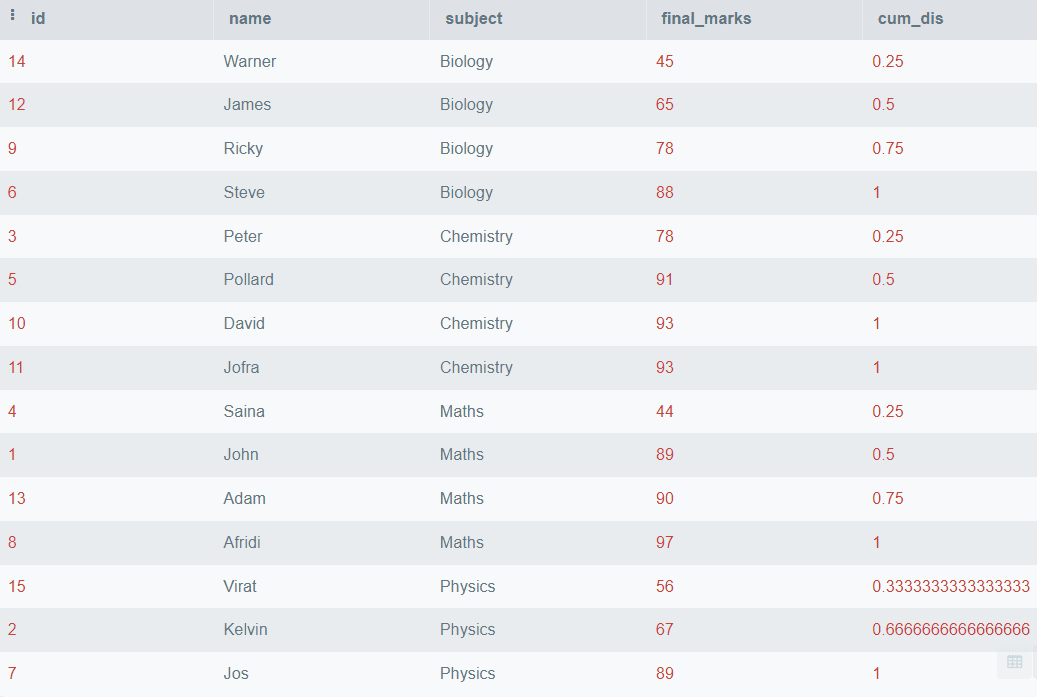
在上面的输出中,我们看到了按科目名称分区的 final_marks 的累积分布。
STDDEV() 和 VARIANCE()
VARIANCE() 函数用于在分区内查找给定值的方差。在统计学中,方差表示一个数字与其平均值之间的差异,或者表示数字之间的扩散程度。它用 ?^2 表示。
STDDEV() 函数用于在分区内查找给定值的标准差。标准差还可以测量数据的变异性,它等于方差的平方根。它用 ? 表示。
这些参数可以帮助我们找到数据中的离散度和变异性。让我们看看如何实际操作。
SELECT *,
STDDEV(final_marks)
OVER (
PARTITION BY subject) AS marks_stddev,
VARIANCE(final_marks)
OVER (
PARTITION BY subject) AS marks_variance
FROM students; 输出: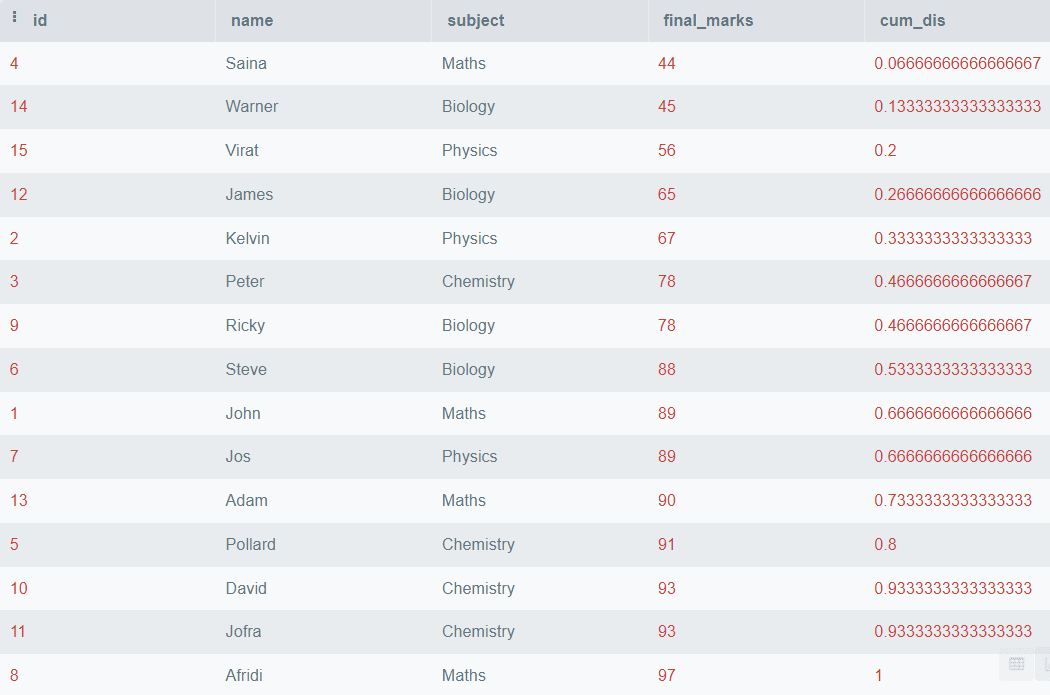 上面的输出显示了每个科目的 final marks 的标准差和方差。
上面的输出显示了每个科目的 final marks 的标准差和方差。
FIRST_VALUE() 和 LAST_VALUE()
FIRST_VALUE() 函数将根据指定的排序输出分区的第一个值。类似地,LAST_VALUE() 函数将输出该分区的最后一个值。当我们想要识别指定分区的第一次和最后一次出现时,可以使用这些函数。
语法:
SELECT *,
FIRST_VALUE(col1)
OVER (
PARTITION BY col2, col3
ORDER BY col4) AS first_value
FROM table_name结论
SQL 分析函数为我们提供了在 SQL 服务器内执行数据分析的函数。使用这些函数,我们可以发掘数据的真正潜力,并从中获得有价值的见解,以提高业务。除了上面讨论的函数之外,还有许多其他出色的函数可以快速解决复杂的问题。您可以从 Microsoft 的这篇文章中阅读更多关于这些分析函数的信息。Aryan Garg 是一名电气工程学士学位学生,目前正在本科最后一年。他对 Web 开发和机器学习领域很感兴趣。他已经追求了这个兴趣,并渴望在这些方向上更多地工作。





