Learn more about Computer vision - Section 10

与Google学习生成式人工智能
通过Google的10门免费课程学习生成式人工智能掌握扩散模型、编码-解码架构、注意力机制等等立即开始吧!

通过代码生成实现模块化视觉问答
由加州大学伯克利分校的博士生Sanjay Subramanian和Google Research感知团队的研究科学家Arsha Nagrani发布 视觉问答(VQA)...

认识DragonDiffusion:一种细粒度图像编辑方法,可以在扩散模型上实现拖拽式操作
大规模文本到图像(T2I)扩散模型旨在根据给定的文本/提示生成图像,由于大量的训练数据和大规模的计算机容量的可用性,这些...
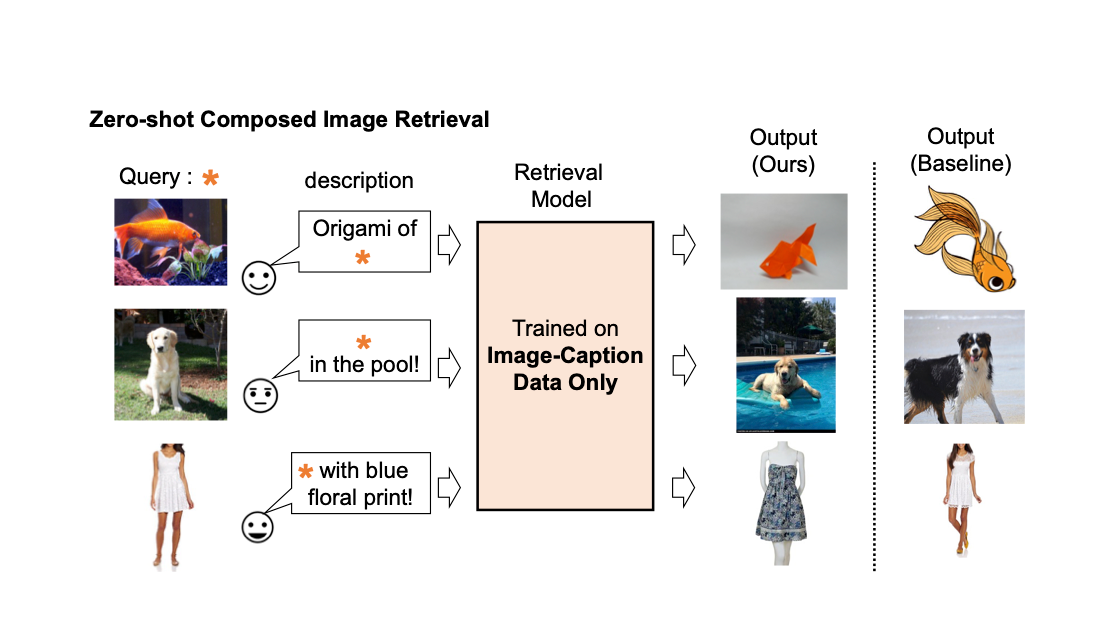
Pic2Word:将图片映射到词语,实现零样本组合图像检索
由谷歌研究的学生研究员Kuniaki Saito和研究科学家Kihyuk Sohn发布,云AI团队的谷歌研究团队 图像检索在搜索引擎中起着至关重...

在3D中玩“瓦尔多在哪里?”:OpenMask3D是一个可以用开放式词汇查询在3D中分割实例的AI模型
图像分割在过去十年中取得了长足的进展,得益于神经网络的发展。现在可以在复杂场景中以毫秒级别完成多个对象的分割,并且结...

来自威斯康星大学和字节跳动的研究人员介绍了PanoHead:第一个能够通过单视图图像合成视角一致的完整头部图像的3D GAN框架
在计算机视觉和图形领域,逼真的肖像图像合成一直备受强调,在虚拟化身、远程呈现、沉浸式游戏和许多其他领域都有广泛的应用...

当计算机视觉更像大脑时,它看起来更像人类看待事物
用来自真实大脑的数据训练人工神经网络可以使计算机视觉更加稳健

了解DiffComplete:一种有趣的人工智能方法,可以通过不完整的形状来完成3D对象
3D范围扫描中的形状补全是一项具有挑战性的任务,它涉及从不完整或部分输入数据中推断完整的3D形状。该领域的先前方法集中在...

你必须推动这些维度:DreamEditor是一个使用文本提示编辑3D场景的AI模型
近年来,3D计算机视觉领域涌现出了大量的NeRF技术。它们作为一种开创性的技术,在场景的重建和合成中实现了突破。NeRF技术可...

Binghamton大学的研究人员为大家引入了一种增强隐私的匿名化系统(我的脸,我的选择),以便每个人都能在社交照片分享网络中对自己的脸部拥有控制权
在面部识别和身份验证算法的背景下,匿名化是一个关键问题。随着这些技术的产品化趋势,关于个人隐私和安全的伦理关切也随之...

遇见FastSAM:具有最小计算负载的突破性实时解决方案,实现高性能分割
分割任何物体模型(Segment Anything Model,SAM)是该领域的一个较新提议。这是一个被誉为突破的视觉基础概念。它可以使用多...

遇见DORSal:一种用于生成和对象级别编辑3D场景的3D结构扩散模型
人工智能随着生成式 AI 和大型语言模型(LLMs)的引入而不断发展。著名的模型如 GPT、BERT、PaLM 等是长列表中引人注目的 LLM...
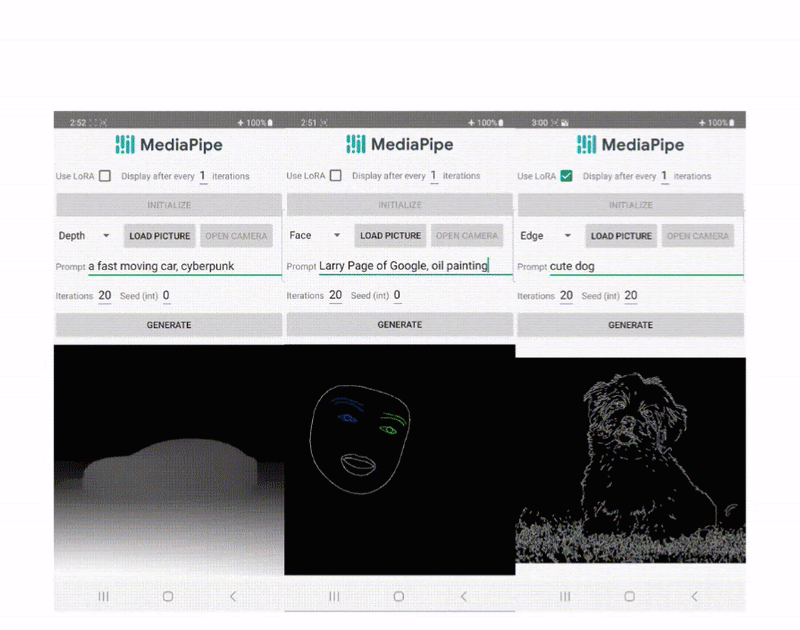
基于设备的条件文本到图像生成的扩散插件
由杨兆和侯廷波,软件工程师,Core ML 发布 近年来,扩散模型在文本到图像生成方面取得了巨大成功,实现了高质量图像、改进的...
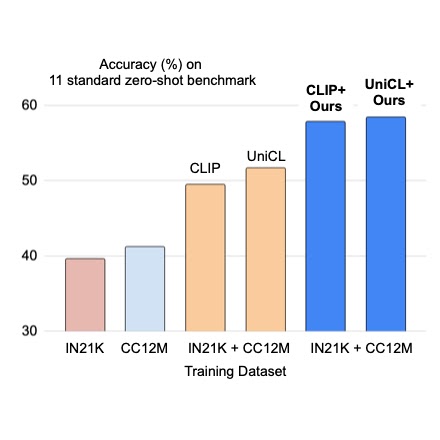
使用前缀条件统一图像说明和图像分类数据集
作者:齐藤邦明(学生研究员,云端AI团队)和孙起赫(研究科学家,感知团队) 最近,通过在大规模图像字幕数据集上对视觉语言...
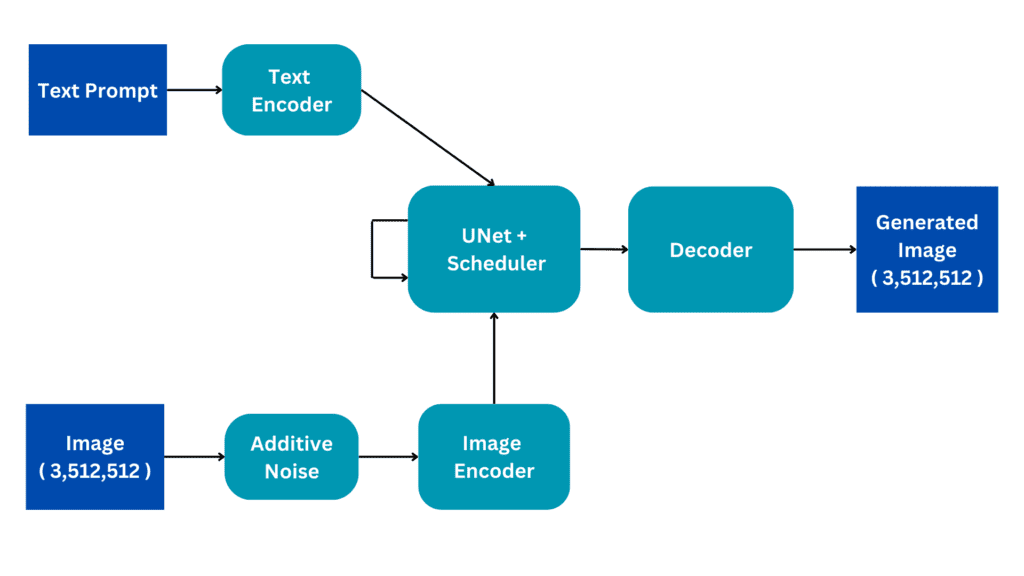
稳定扩散:生成式人工智能背后的基本直觉
本文提供了稳定扩散的总体概述,并重点介绍了如何建立对生成式人工智能工作原理的基本理解

从田间到餐桌:初创公司为食品行业提供人工智能自助餐
它就像魔法一样奏效。在一个数据中心中运行的计算机视觉算法发现了一种疾病即将在印度的一个遥远的小麦田中爆发。 十六天后,...

普林斯顿的研究人员推出Infinigen:一种自然界照片级3D场景的程序生成器
普林斯顿大学的研究团队在最近的一篇论文中介绍了 Infinigen,这是一款划时代的程序生成器,可用于生成逼真的三维场景,论文...

来自 Allen Institute for AI 的研究人员介绍了 VISPROG:一种神经符号化方法,用于根据自然语言指令解决复杂和组合的视觉任务
寻找通用人工智能系统推动了具备能力的可训练模型的发展,其中许多旨在为用户提供简单的自然语言接口。大规模无监督预训练后...

Meta AI的另一个革命性大规模模型——DINOv2用于图像特征提取
Mete AI 推出了一款名为 DINOv2 的图像特征提取模型的新版本,该模型可以自动从图像中提取视觉特征这是人工智能领域的又一次...

认识Video-ControlNet:一款新的游戏改变型文本到视频扩散模型,塑造可控视频生成的未来
近年来,基于文本的视觉内容生成得到了快速发展。通过大规模的图像-文本对进行训练,目前的文本到图像(T2I)扩散模型已经展...

- You may be interested
- 人工智能图像:对生成对抗网络(GANs)的...
- 银行如何利用负责任的人工智能应对金融犯罪
- 如何获得数据科学工作?[8个简单步骤解析]
- Meta AI的另一个革命性大规模模型——DINOv2...
- 这项AI研究提出了随机切片混合数据增强(R...
- 围绕人工智能的扩展和采用存在的5个问题
- 使用新的Amazon Kendra Alfresco连接器对...
- 结识TensorRT-LLM:一款在NVIDIA Tensor C...
- “先有梦想,后学习:DECKARD是一种利用LLM...
- 「AI技术用于更安全的自行车头盔和更好的...
- 仿真优化:帮助我的朋友对他公司的支持服...
- 谷歌脑科学家联合创始人声称科技公司夸大...
- Meta 和GeorgiaTech的研究人员发布了一项...
- CDF与PDF:有什么区别?
- 实时了解您的数据

