Learn more about Multimodal Learning

通过代码生成实现模块化视觉问答
由加州大学伯克利分校的博士生Sanjay Subramanian和Google Research感知团队的研究科学家Arsha Nagrani发布 视觉问答(VQA)...
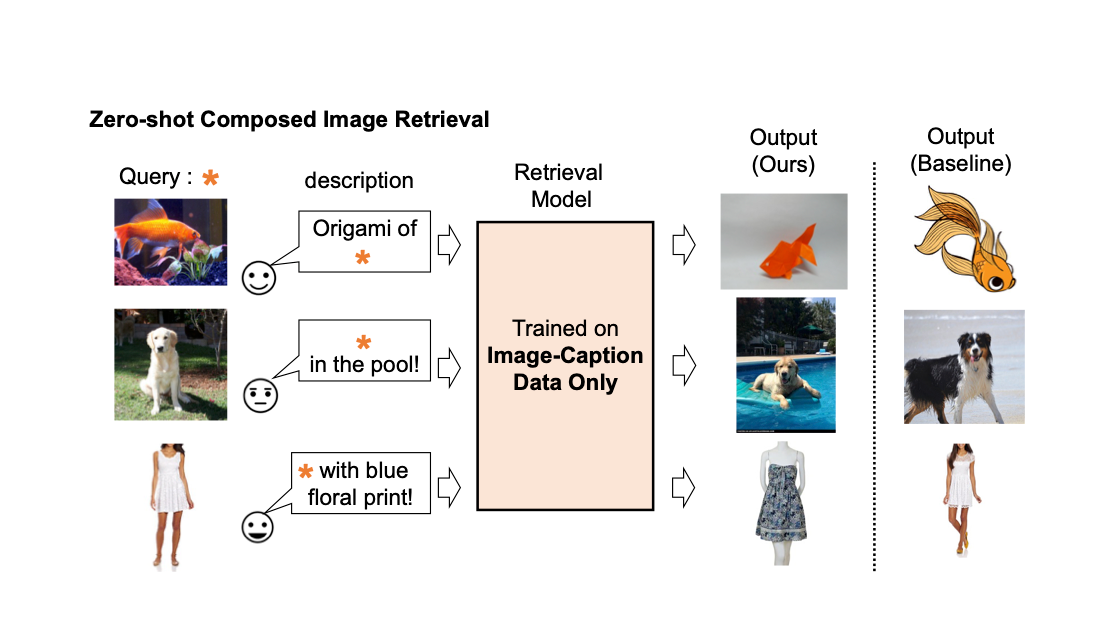
Pic2Word:将图片映射到词语,实现零样本组合图像检索
由谷歌研究的学生研究员Kuniaki Saito和研究科学家Kihyuk Sohn发布,云AI团队的谷歌研究团队 图像检索在搜索引擎中起着至关重...
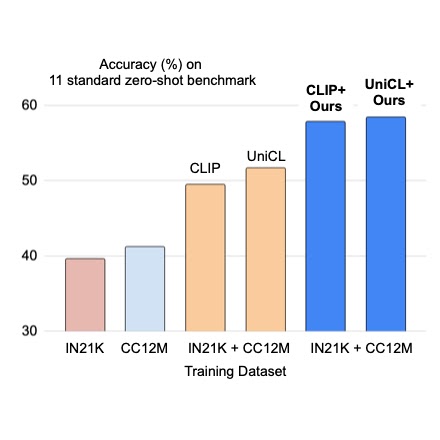
使用前缀条件统一图像说明和图像分类数据集
作者:齐藤邦明(学生研究员,云端AI团队)和孙起赫(研究科学家,感知团队) 最近,通过在大规模图像字幕数据集上对视觉语言...

检索增强的视觉语言预训练
作者:胡子牛(Ziniu Hu),学生研究员,法提阿利(Alireza Fathi),研究科学家,Google研究,感知团队 大型模型(例如T5,G...

- You may be interested
- 见到YaRN:一种计算高效的方法,可以扩展...
- 使用React和Express构建一个由ChatGPT驱动...
- 介绍私有中心:一种新的用于构建机器学习...
- 通过ChatGPT发现客户洞察
- 用Python掌握长短期记忆:释放LSTM在自然...
- 建立具有自定义镜头的良好架构的 IDP 解决...
- 人工智能吞食互联网的一年’ (Rén Gō...
- 自然语言处理(NLP)、神经网络(NN)、时...
- ID vs. 多模态推荐系统:迁移学习的视角
- 揭示检索增强生成(RAG) | AI与人类知识相遇
- Hugging Face 的开源文本生成和 LLM 生态系统
- 10款最佳的Mac数据恢复工具(2023年7月)
- 一个关于大型语言模型的简单介绍
- Python for Data Engineers’ 的翻译...
- “在线大规模推荐的双增强双塔模型”

