认识Video-ControlNet:一款新的游戏改变型文本到视频扩散模型,塑造可控视频生成的未来


近年来,基于文本的视觉内容生成得到了快速发展。通过大规模的图像-文本对进行训练,目前的文本到图像(T2I)扩散模型已经展示出了基于用户提供的文本提示生成高质量图像的惊人能力。图像生成的成功也被扩展到视频生成。一些方法利用T2I模型以一次或零次方式生成视频,而从这些模型生成的视频仍然不一致或缺乏多样性。通过扩展视频数据,文本到视频(T2V)扩散模型可以创建具有文本提示的一致视频。然而,这些模型生成的视频缺乏对生成内容的控制。
最近的一项研究提出了一种T2V扩散模型,允许使用深度图作为控制。然而,需要大规模的数据集才能实现一致性和高质量,这是资源不友好的。此外,对于T2V扩散模型来说,生成一致、任意长度和多样性的视频仍然具有挑战性。
为了解决这些问题,引入了一种可控的T2V模型Video-ControlNet。Video-ControlNet具有以下优点:通过使用运动先验和控制图提高一致性,通过采用第一帧调节策略生成任意长度的视频,通过从图像到视频的知识转移实现域通用性,通过使用有限批量大小实现更快的收敛性来节省资源。
- Python和R中机器学习算法的比较
- UC Berkeley和Meta AI研究人员提出了一种拉格朗日动作识别模型,通过融合3D姿态和上下文化外观来跟踪轨迹
- 认识CoDi:一种新的跨模态扩散模型,可用于任意合成
Video-ControlNet的体系结构如下图所示。
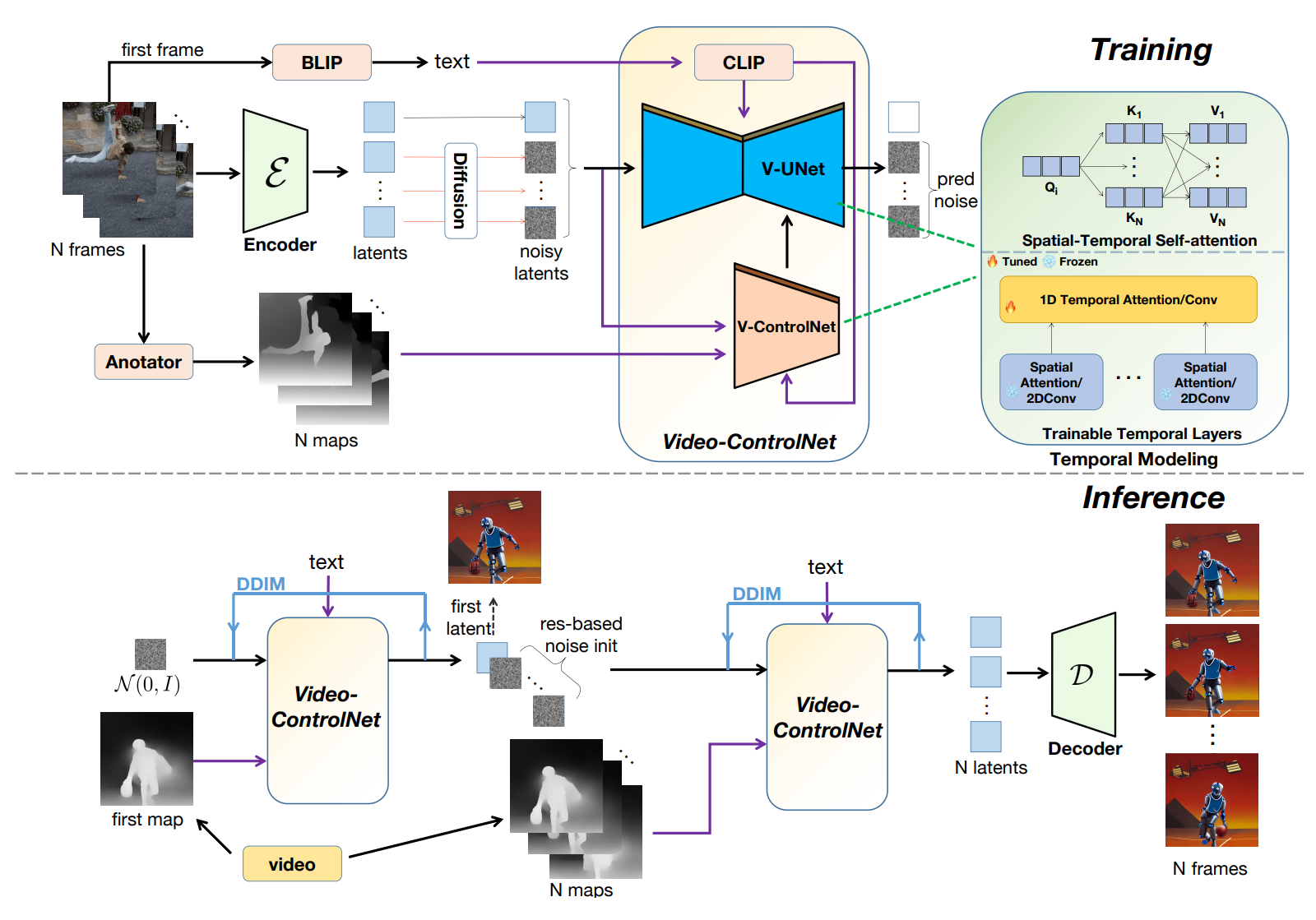

生成模型是通过重新组织预先训练的可控T2I模型、并加入额外的可训练时间层、以及提供一种空间-时间自注意机制来开发的,从而实现了带有文本和参考控制图的视频生成。这种方法即使在没有进行广泛训练的情况下,也允许创建内容一致的视频。
为了确保视频结构的一致性,作者提出了一种开创性的方法,将源视频的运动先验引入到噪声初始化阶段的去噪过程中。通过利用运动先验和控制图,Video-ControlNet能够产生更少闪烁且更接近输入视频运动变化的视频,同时还避免了其他基于运动的方法中的错误传播,这是由于多步去噪过程的性质造成的。
此外,为了避免以前的方法直接训练模型生成整个视频,本研究引入了一种创新的训练方案,该方案基于初始帧生成视频。通过这种简单而有效的策略,更容易分离内容和时间学习,因为前者呈现在第一帧和文本提示中。
模型只需要学习如何生成后续帧,从图像领域继承生成能力,减少对视频数据的需求。在推理过程中,第一帧生成的条件是第一帧的控制图和文本提示。然后,后续帧是基于第一帧、文本和后续控制图生成的。此外,这种策略的另一个好处是,模型可以自回归地生成无限长的视频,方法是将上一次迭代的最后一帧作为初始帧。
这就是它的工作原理。让我们看看作者报告的结果。下图显示了有限批量的样本结果和与最先进方法的比较。

这是关于Video-ControlNet的摘要,这是一种新颖的扩散模型,用于T2V生成,具有最先进的质量和时间一致性。如果您有兴趣,可以在下面的链接中了解更多关于这种技术的信息。






