遇见DORSal:一种用于生成和对象级别编辑3D场景的3D结构扩散模型


人工智能随着生成式 AI 和大型语言模型(LLMs)的引入而不断发展。著名的模型如 GPT、BERT、PaLM 等是长列表中引人注目的 LLMs,它们正在改变人类和计算机的互动方式。在图像生成方面,扩散模型已引起研究人员的广泛关注,因为这些模型捕捉了图像数据集的复杂概率分布,并生成类似于训练数据的新样本。3D 场景理解也在不断发展,使得可以开发出可以在大规模场景数据集上进行训练的无几何神经网络来学习场景表示。这些网络对未见过的场景和物体具有很好的泛化能力,只需从单个或少数几个输入图像中渲染视图,并且训练时只需要每个场景的少量观察。
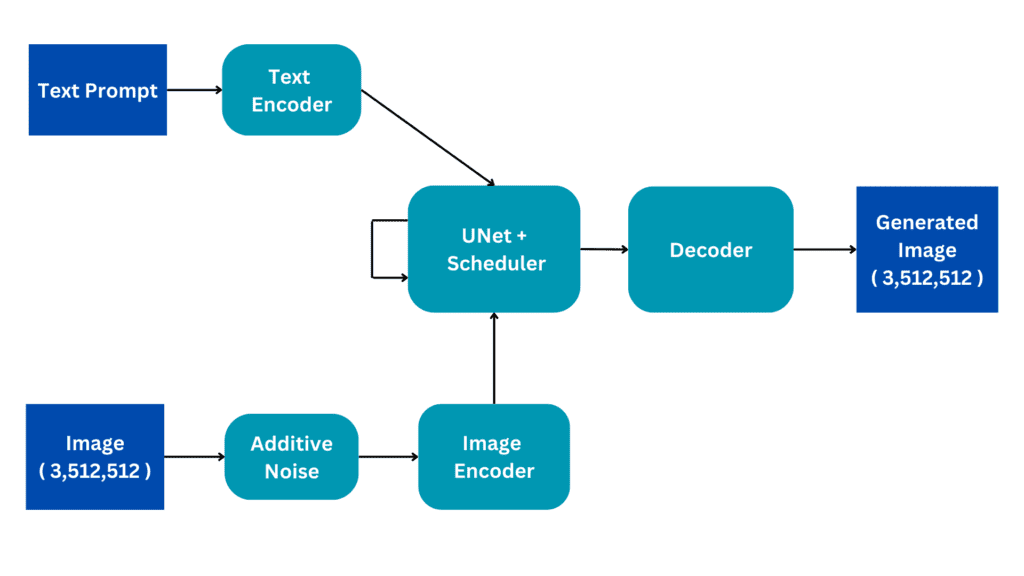
通过结合扩散模型和3D场景表示学习模型的能力,加州大学伯克利分校、谷歌研究和谷歌DeepMind的研究人员提出了DORSal(Diffusion for Object-centric Representations of Scenes et al.),这是一种通过将物体表示与扩散解码器相结合来生成三维场景中新颖视角的方法。DORSal是无几何的,因为它纯粹从数据中学习3D场景结构,而不需要任何昂贵的体积渲染。
为了创建3D场景,DORSal利用了最初用于图片合成目的的视频扩散架构。其主要概念是依赖于场景的物体为中心的插槽化表示来约束扩散模型。这些描绘捕捉了场景物体及其特征的重要细节。通过在这些物体为中心的表示上配置扩散模型,DORSal促进了对3D场景创新视角的高保真合成。它还保持了物体级别场景编辑的能力,使用户可以更改和修改场景中的特定物体。
团队分享的主要贡献如下:
- DORSal是一种用于3D新视图合成的方法,利用扩散模型和物体为中心的场景表示的优势来提高渲染视图的质量。
- DORSal在3D场景理解文献中优于先前的方法,并能够生成更精确的视图,Fréchet Inception Distance(FID)提高了5倍至10倍。
- 与先前关于3D扩散模型的工作相比,DORSal在处理更复杂的场景方面表现出卓越性能。在对真实世界的街景数据进行评估时,DORSal在渲染质量方面表现显著优于其他方法。
- DORSal能够将扩散模型条件化为结构化的基于对象的场景表示。通过使用这种表示,DORSal学会使用单个对象组合场景,使得推理过程中可以进行基本的物体级别场景编辑,允许用户操纵和修改场景中的特定对象。
总之,DORSal的有效性可以通过在复杂的合成多物体场景和Google Street View等真实世界大规模数据集上进行的实验来看出。它成功地实现了可扩展的神经渲染3D场景和物体级别编辑,使其成为未来的有希望的方法。其改进的渲染质量显示了推进3D场景理解的潜力。