Pic2Word:将图片映射到词语,实现零样本组合图像检索
Pic2Word Combining image retrieval with zero-shot learning by mapping images to words.
由谷歌研究的学生研究员Kuniaki Saito和研究科学家Kihyuk Sohn发布,云AI团队的谷歌研究团队
图像检索在搜索引擎中起着至关重要的作用。通常,用户使用图像或文本作为查询来检索所需的目标图像。然而,基于文本的检索有其局限性,因为用词准确地描述目标图像可能是一项具有挑战性的任务。例如,当搜索时尚品项时,用户可能希望找到一个特定属性不同于网站上找到的属性的物品,例如标志的颜色或标志本身。然而,在现有搜索引擎中搜索该物品并不容易,因为通过文本准确地描述时尚品项是具有挑战性的。为了解决这一问题,组成图像检索(CIR)通过结合图像和提供如何修改图像以适应所需检索目标的文本示例的查询来检索图像。因此,CIR通过结合图像和文本实现了对目标图像的精确检索。
然而,CIR方法需要大量的标记数据,即1)查询图像,2)描述和3)目标图像的三元组。收集这样的标记数据是昂贵的,并且在这些数据上训练的模型通常针对特定的用例,限制了它们推广到不同数据集的能力。
为了解决这些挑战,在“Pic2Word: 将图片映射到单词进行零样本组合图像检索”中,我们提出了一项称为零样本CIR(ZS-CIR)的任务。在ZS-CIR中,我们旨在建立一个单一的CIR模型,执行各种CIR任务,如对象组合,属性编辑或域转换,而无需标记的三元组数据。相反,我们提出使用大规模的图像-标题对和未标记的图像来训练检索模型,这比规模化的监督CIR数据集要容易收集得多。为了促进可复现性并进一步推动这个领域的发展,我们还发布了代码。
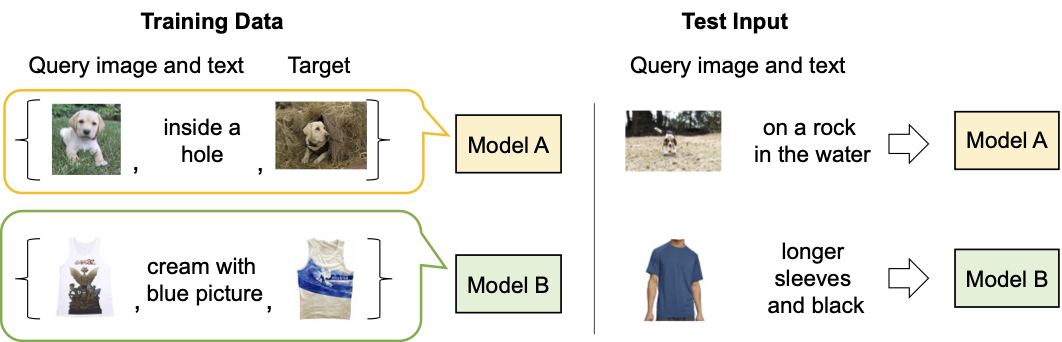 |
| 现有组成图像检索模型的描述。 |
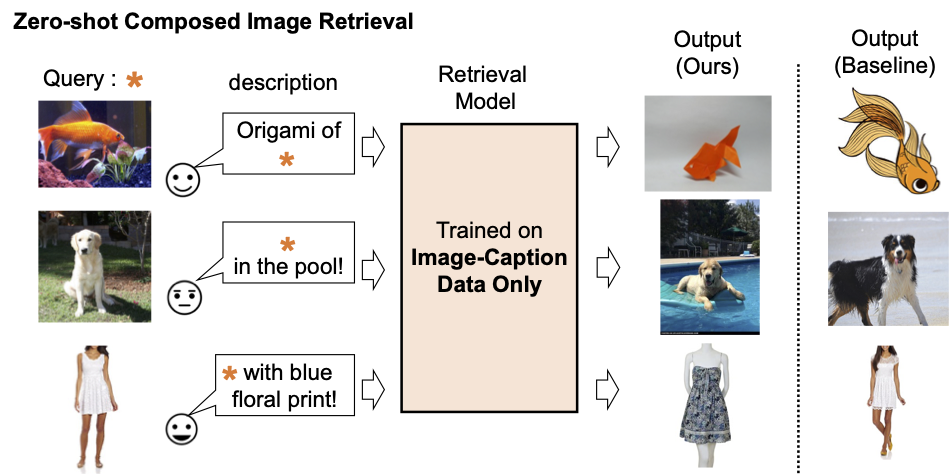 |
| 我们只使用图像-标题数据来训练组成图像检索模型。我们的模型可以检索与查询图像和文本组合对齐的图像。 |
方法概述
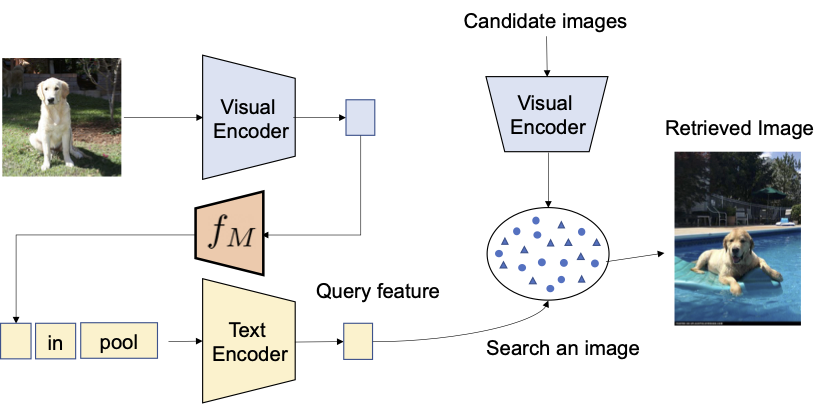
我们提出利用对比式语言-图像预训练模型(CLIP)中的语言编码器的语言能力,该模型在生成广泛范围的文本概念和属性的语义有意义的语言嵌入方面表现出色。为此,我们在CLIP中使用了一个轻量级的映射子模块,旨在将输入图片(例如一张猫的照片)从图像嵌入空间映射到文本输入空间中的单词符号(例如“猫”)。整个网络通过视觉-语言对比损失进行优化,以确保在给定图像和其文本描述对的情况下,视觉和文本嵌入空间尽可能接近。然后,查询图像可以被视为一个单词。这使得语言编码器可以灵活和无缝地组合查询图像特征和文本描述。我们称这种方法为Pic2Word,并在下图中概述了其训练过程。我们希望映射的符号s能够以单词符号的形式代表输入图像。然后,我们训练映射网络在语言嵌入p中重构图像嵌入。具体而言,我们采用CLIP中提出的对比损失,计算视觉嵌入v和文本嵌入p之间的对比损失。
 |
| 使用未标记的图像仅对映射网络(f M)进行训练。我们仅优化映射网络,并冻结视觉和文本编码器。 |
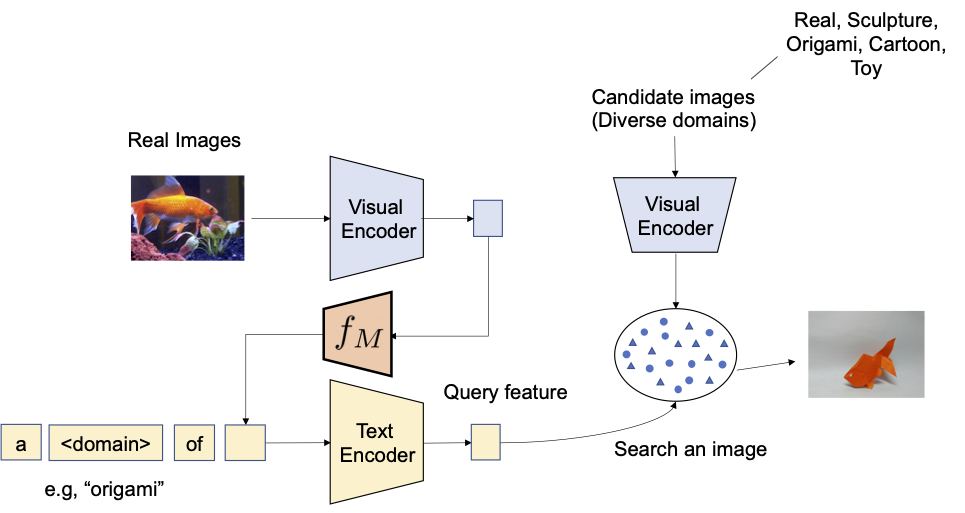
经过训练的映射网络后,我们可以将图像视为一个词元,并将其与文本描述配对,以灵活地组合成如下图所示的联合图像-文本查询。
 |
| 通过训练的映射网络,我们将图像视为一个词元,并将其与文本描述配对,以灵活地组合成联合图像-文本查询。 |
评估
我们进行了各种实验,以评估Pic2Word在各种CIR任务上的性能。
域转换
我们首先评估所提出方法在域转换上的组合能力 – 给定一张图像和所需的新图像域(例如雕塑、折纸、卡通、玩具),系统的输出应该是一张具有相同内容但在新的期望图像域或样式中的图像。如下所示,我们评估了在图像和文本分别作为图像和文本描述时,组合类别信息和域描述的能力。我们使用ImageNet和ImageNet-R评估从真实图像转换为四个域。
为了与不需要监督训练数据的方法进行比较,我们选择了三种方法:(i)仅使用图像进行检索,仅使用视觉嵌入,(ii)仅使用文本进行检索,仅使用文本嵌入,以及(iii)使用图像和文本的平均嵌入来组合查询。与(iii)的比较显示了使用语言编码器组合图像和文本的重要性。我们还与在Fashion-IQ或CIRR上训练CIR模型的Combiner进行比较。
 |
| 我们的目标是将输入查询图像的领域转换为以文本描述的领域,例如折纸。 |
如下图所示,我们提出的方法在性能上远远超过基准线。
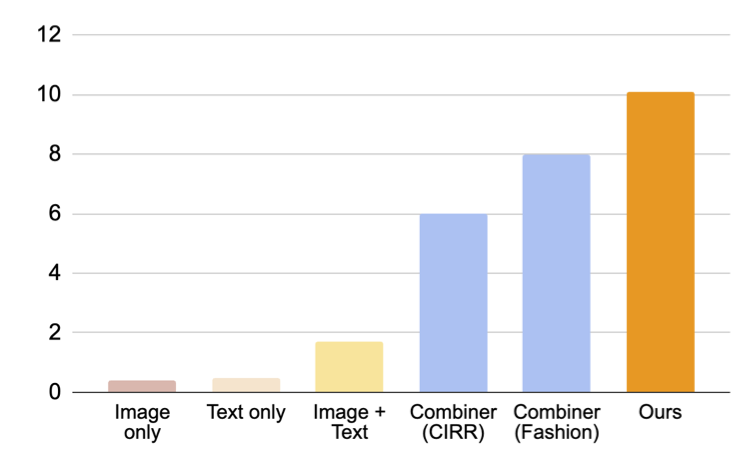 |
| 对于域转换的组合图像检索,结果(召回率@10,即前10个检索到的相关实例的百分比)。 |
时尚属性组合
接下来,我们使用时尚智力问答数据集评估时尚属性的组合,例如衣服的颜色、标志和袖子的长度。下图显示了给定查询的期望输出。
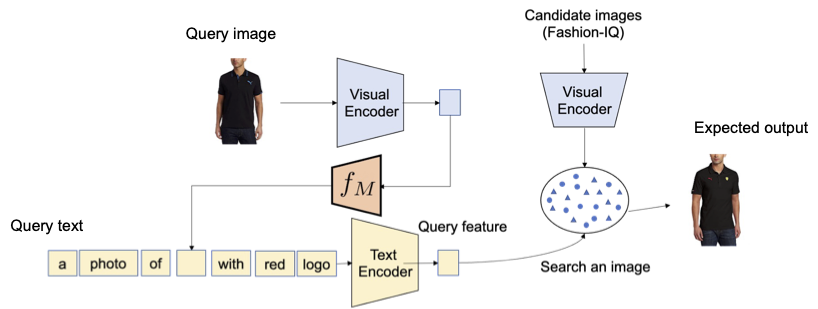 |
| 时尚属性组合的CIR概述。 |
在下图中,我们与基准线进行了比较,包括使用三元组训练CIR模型的有监督基线:(i) CB使用与我们方法相同的架构,(ii) CIRPLANT, ALTEMIS, MAAF使用更小的主干网络,例如ResNet50。与这些方法的比较将帮助我们了解我们的零样本方法在此任务上的表现。
尽管CB的性能优于我们的方法,但我们的方法比使用较小主干网络的有监督基线表现更好。这个结果表明,通过利用强大的CLIP模型,我们可以训练出一个高效的CIR模型,而无需注释的三元组。
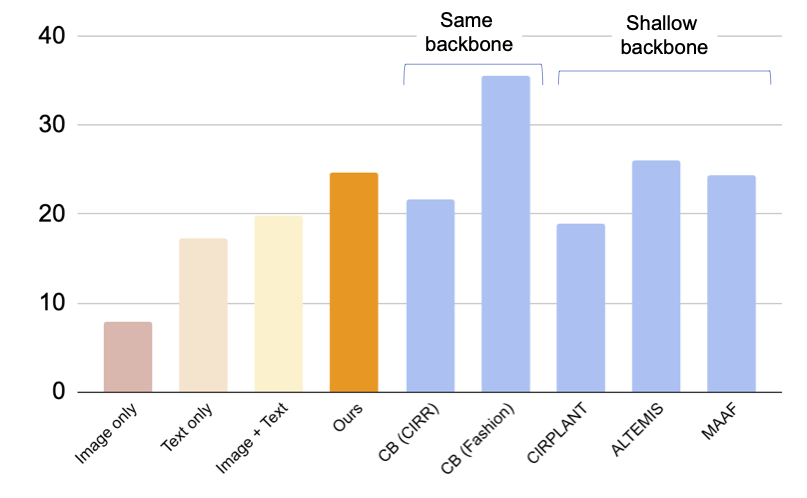 |
| 对于时尚智力问答数据集的组合图像检索的结果(召回率@10,即前10个检索到的相关实例的百分比)(越高越好)。浅蓝色柱表示使用三元组训练模型。请注意,我们的方法在与这些有监督基线使用较浅(更小)主干网络上表现相当。 |
定性结果
下图展示了几个示例。与不需要受监督训练数据的基准方法(文本+图像特征平均)相比,我们的方法在正确检索目标图像方面表现更好。
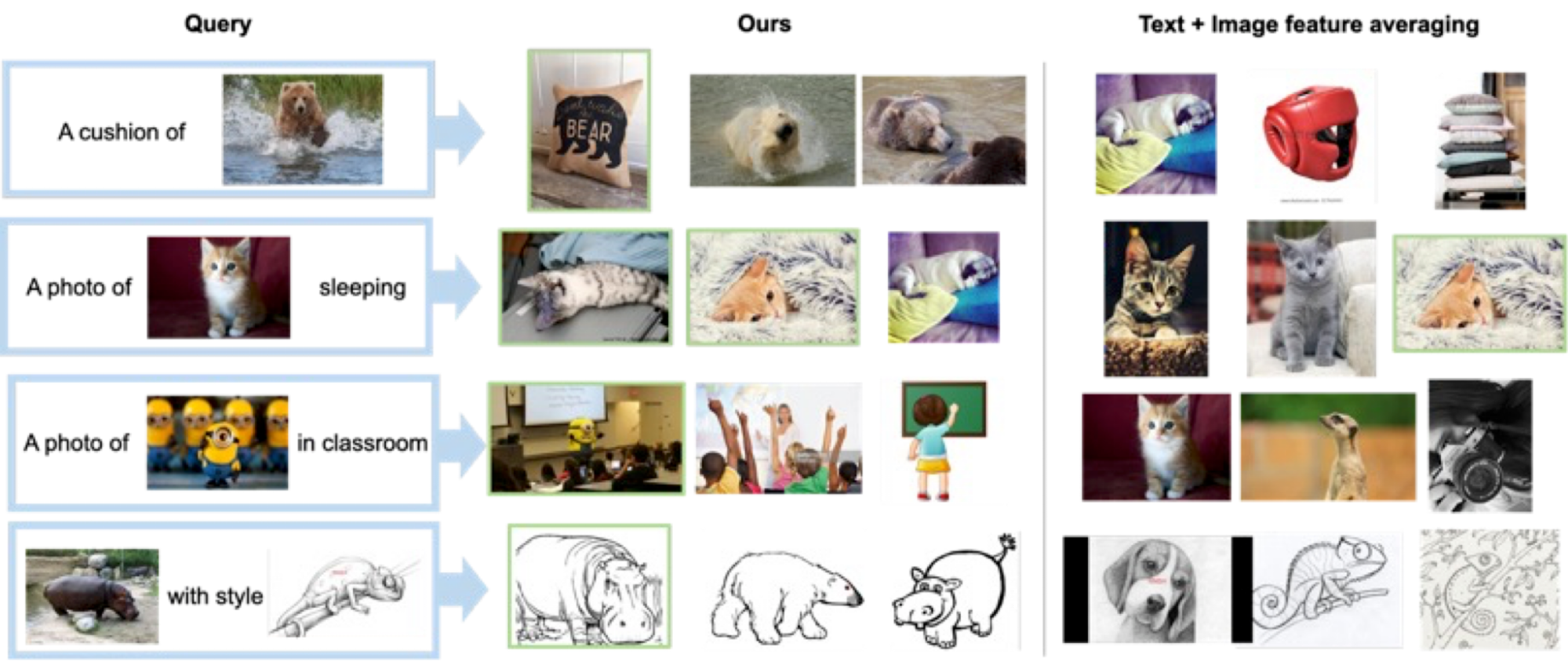 |
| 多样化的查询图像和文本描述的定性结果。 |
结论和未来工作
在本文中,我们介绍了Pic2Word,一种用于将图片映射到词语的ZS-CIR方法。我们建议将图像转换为一个词语令牌,以仅使用图像-字幕数据集来实现CIR模型。通过各种实验,我们验证了训练模型在不同的CIR任务上的有效性,表明在图像-字幕数据集上进行训练可以构建一个强大的CIR模型。一个潜在的未来研究方向是利用字幕数据来训练映射网络,尽管我们在当前工作中仅使用图像数据。
致谢
此研究由Kuniaki Saito、Kihyuk Sohn、Xiang Zhang、Chun-Liang Li、Chen-Yu Lee、Kate Saenko和Tomas Pfister进行。还要感谢Zizhao Zhang和Sergey Ioffe提供的宝贵反馈。





