基于设备的条件文本到图像生成的扩散插件
由杨兆和侯廷波,软件工程师,Core ML 发布
近年来,扩散模型在文本到图像生成方面取得了巨大成功,实现了高质量图像、改进的推理性能和拓展创作灵感。然而,高效地控制生成仍然具有挑战性,特别是对于难以用文本描述的条件。
今天,我们宣布MediaPipe扩散插件,可以在设备上运行可控文本到图像生成。在扩展我们之前关于在设备上进行大型生成模型的GPU推理的工作的基础上,我们引入了新的低成本解决方案,用于可控文本到图像生成,可以插入到现有的扩散模型及其低秩适应(LoRA)变体中。
 |
| 在设备上运行具有控制插件的文本到图像生成。 |
背景
使用扩散模型,图像生成被建模为一个迭代的去噪过程。从一个噪声图像开始,每一步,扩散模型逐渐去噪图像,揭示出目标概念的图像。研究表明,通过文本提示利用语言理解可以大大改善图像生成。对于文本到图像生成,文本嵌入通过交叉注意力层连接到模型。然而,有些信息很难用文本提示描述,例如物体的位置和姿态。为了解决这个问题,研究人员在扩散中添加了额外的模型,以从条件图像中注入控制信息。
控制文本到图像生成的常见方法包括Plug-and-Play,ControlNet和T2I Adapter。Plug-and-Play应用了广泛使用的去噪扩散隐式模型(DDIM)反演方法,从输入图像开始逆向生成过程,得到初始噪声输入,然后使用扩散模型的副本(860M参数用于稳定扩散1.5)来编码从输入图像中提取的条件。Plug-and-Play使用自注意力从复制的扩散中提取空间特征,并将它们注入文本到图像扩散中。ControlNet创建了扩散模型编码器的可训练副本,它通过一个具有零初始化参数的卷积层连接到编码条件信息,这些信息传递给解码器层。然而,由于结果,大小较大,仅为扩散模型的一半(430M参数用于稳定扩散1.5)。T2I Adapter是一个较小的网络(77M参数),在可控生成方面达到类似的效果。T2I Adapter只接受条件图像作为输入,并且其输出在所有扩散迭代中共享。然而,适配器模型并不适用于便携设备。
MediaPipe扩散插件
为了使条件生成高效、可定制和可扩展,我们设计了MediaPipe扩散插件作为一个单独的网络,它具有以下特点:
- 可插拔:可以轻松连接到预训练的基础模型。
- 从头开始训练:不使用基础模型的预训练权重。
- 可移植:它在移动设备上运行,与基础模型推理相比成本可忽略。
| 方法 | 参数大小 | 可插拔 | 从头开始 | 可移植 | ||||
| Plug-and-Play | 860M* | ✔️ | ❌ | ❌ | ||||
| ControlNet | 430M* | ✔️ | ❌ | ❌ | ||||
| T2I Adapter | 77M | ✔️ | ✔️ | ❌ | ||||
| MediaPipe插件 | 6M | ✔️ | ✔️ | ✔️ |
| Plug-and-Play、ControlNet、T2I适配器和MediaPipe扩散插件的比较。*具体的扩散模型有所不同。 |
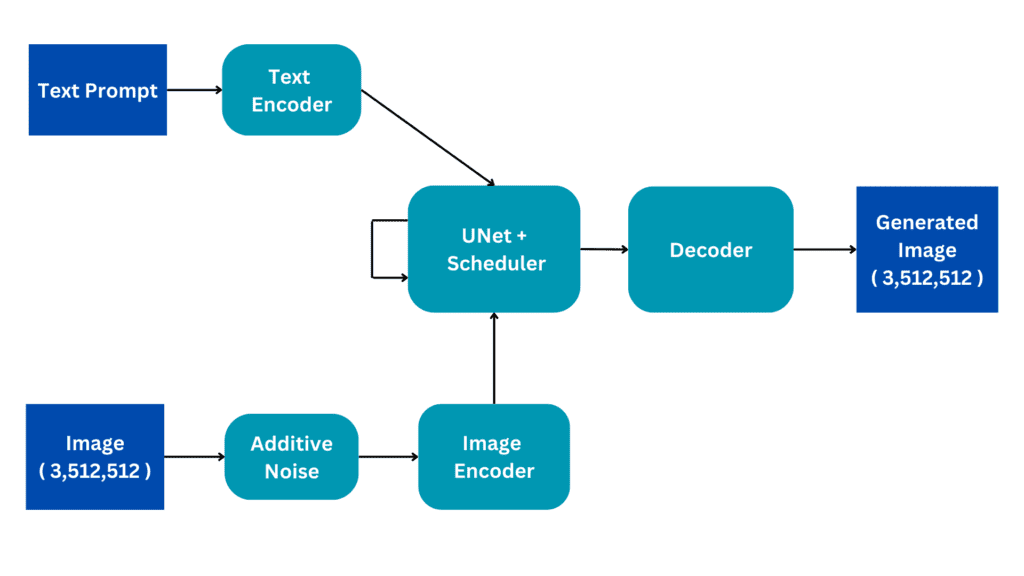
MediaPipe扩散插件是一种便携式的设备端模型,用于文本到图像的生成。它从一个条件图像中提取多尺度特征,并将其添加到相应级别的扩散模型的编码器中。当连接到文本到图像扩散模型时,插件模型可以为图像生成提供额外的条件信号。我们设计了插件网络,它是一个只有6M参数的轻量级模型。它使用MobileNetv2的深度卷积和反向瓶颈,在移动设备上进行快速推理。
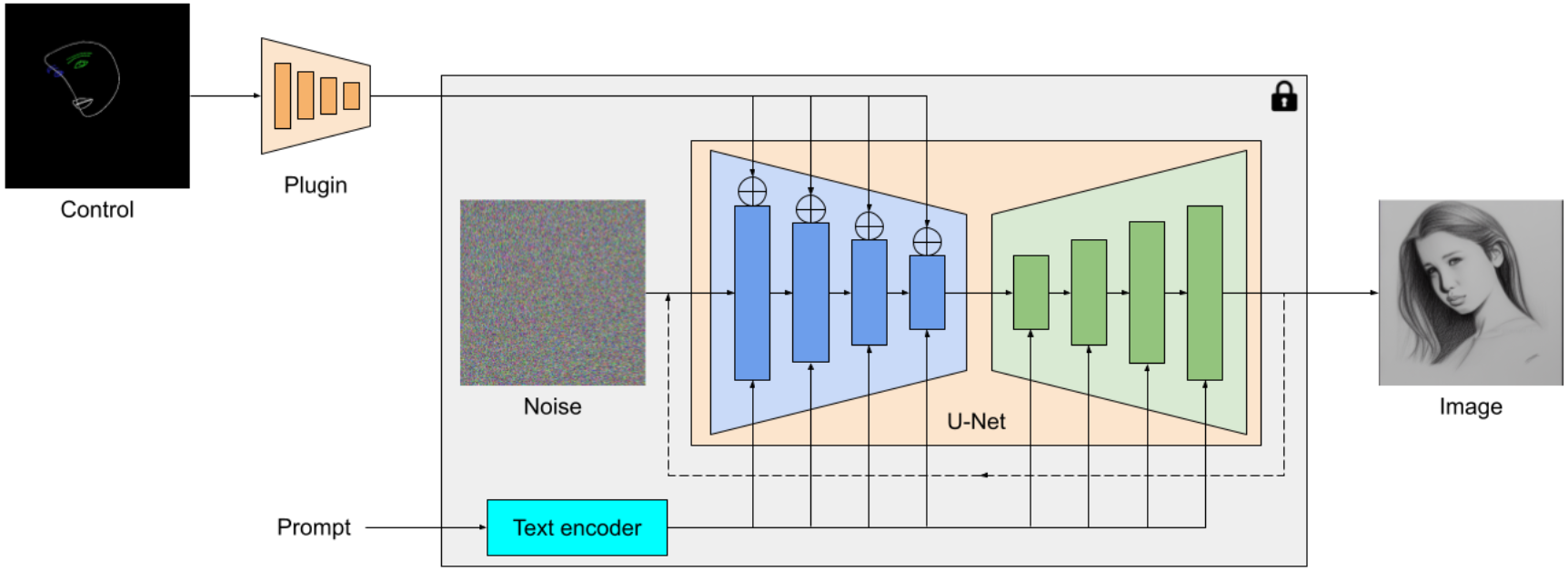 |
| MediaPipe扩散模型插件概述。插件是一个独立的网络,其输出可以插入到预训练的文本到图像生成模型中。插件提取的特征应用于扩散模型的相关下采样层(蓝色)。 |
与ControlNet不同,我们在所有扩散迭代中注入相同的控制特征。也就是说,我们只运行一次插件来生成一张图像,这样可以节省计算量。下面我们展示了一些扩散过程的中间结果。控制在每个扩散步骤中都是有效的,并且即使在早期步骤中也可以进行受控生成。增加迭代次数可以改善图像与文本提示的对齐,并生成更多的细节。
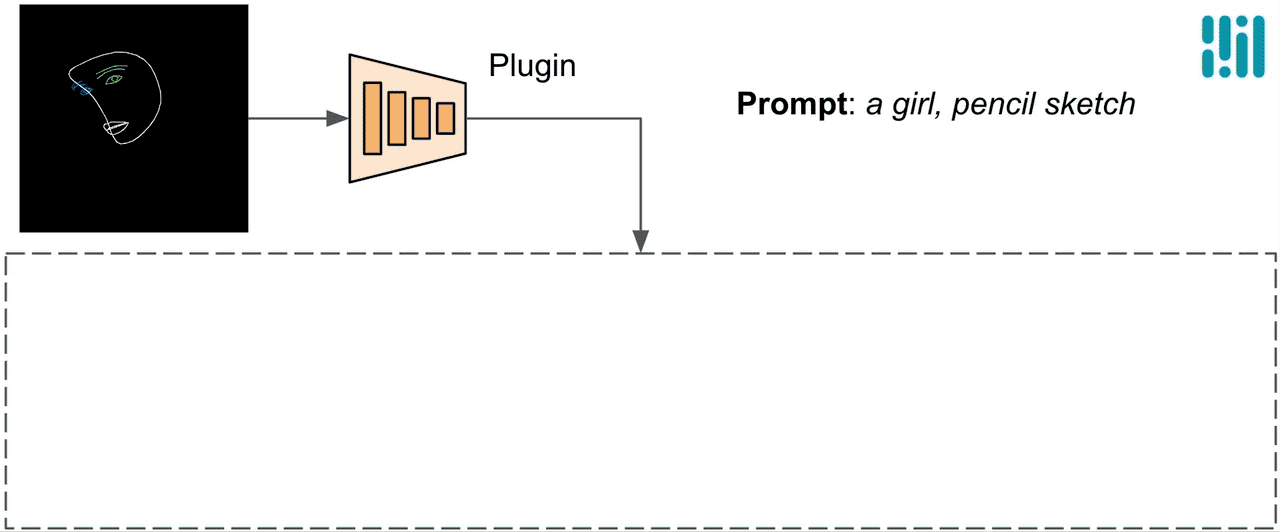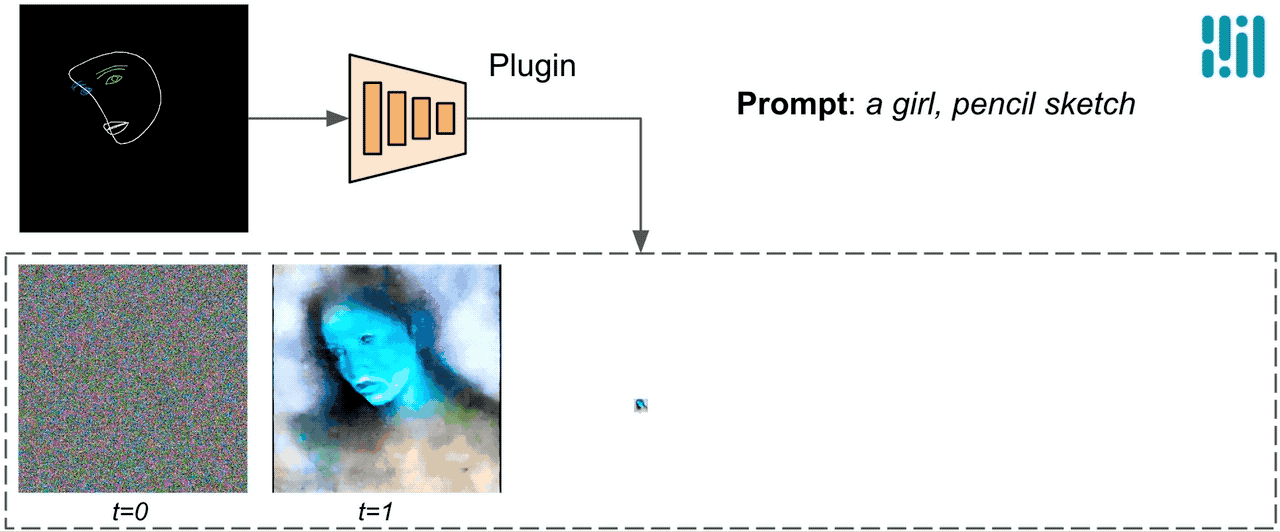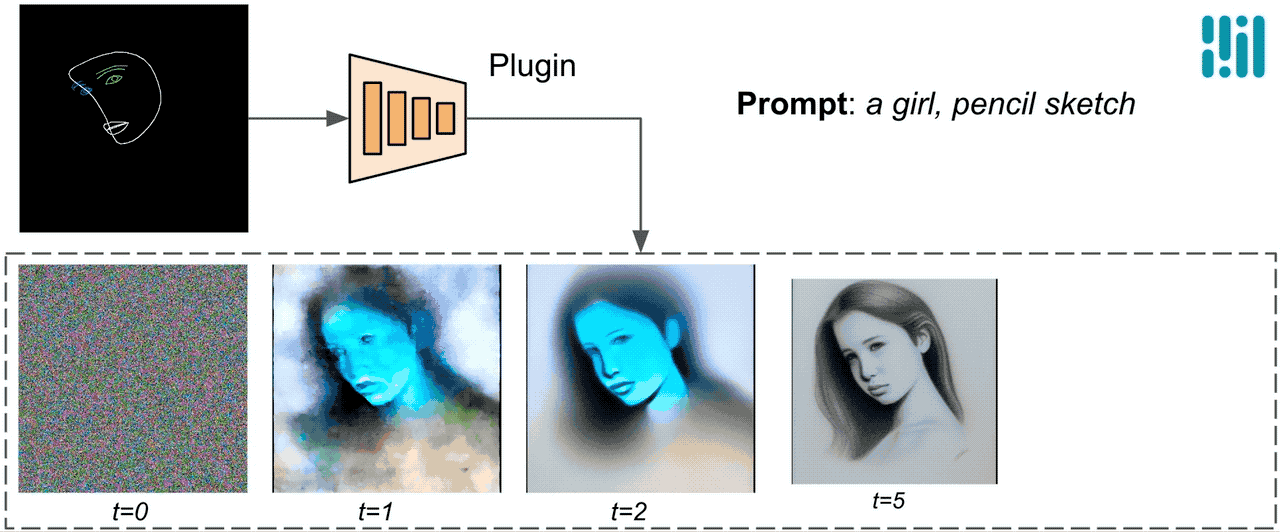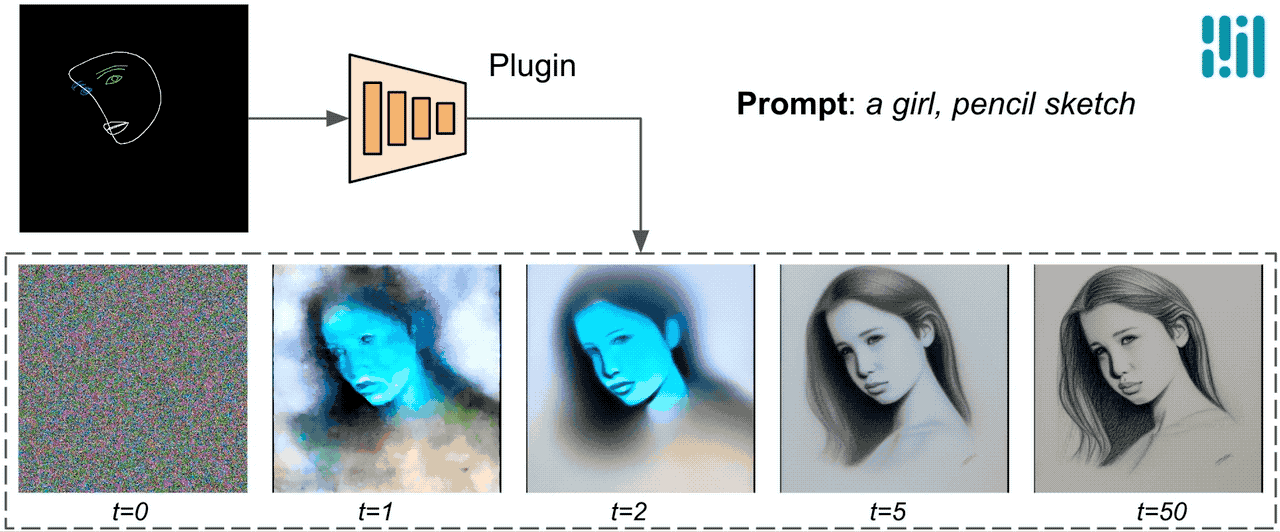 |
| 使用MediaPipe扩散插件的生成过程示意图。 |
示例
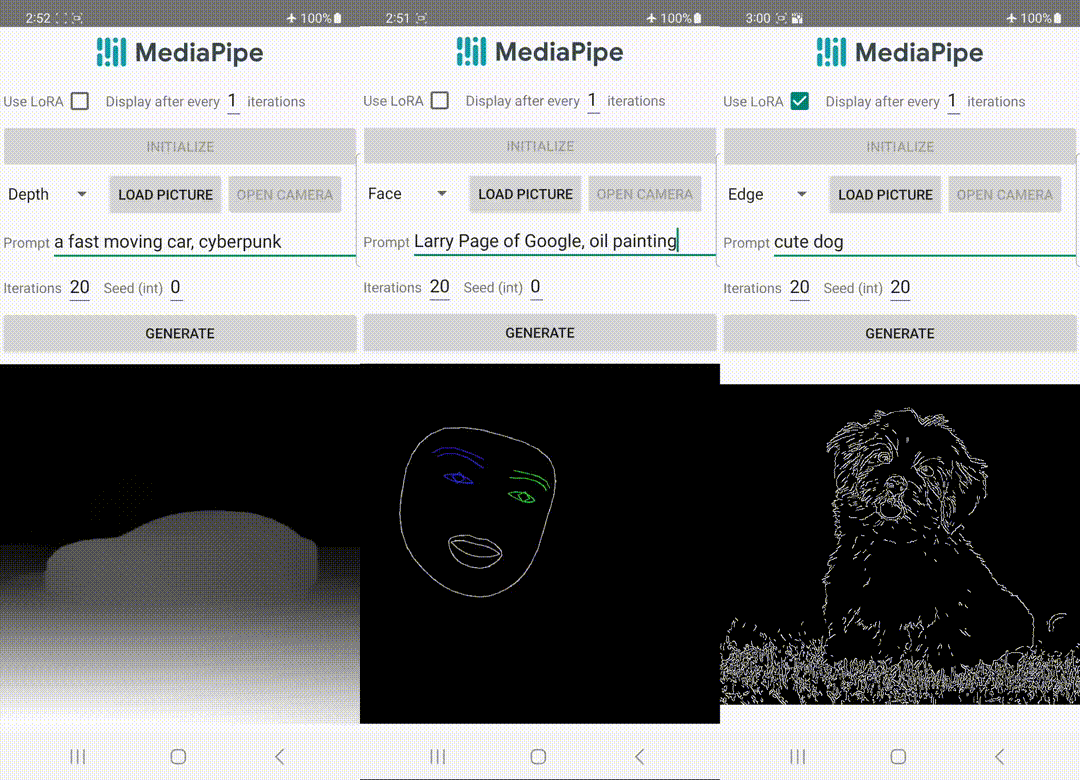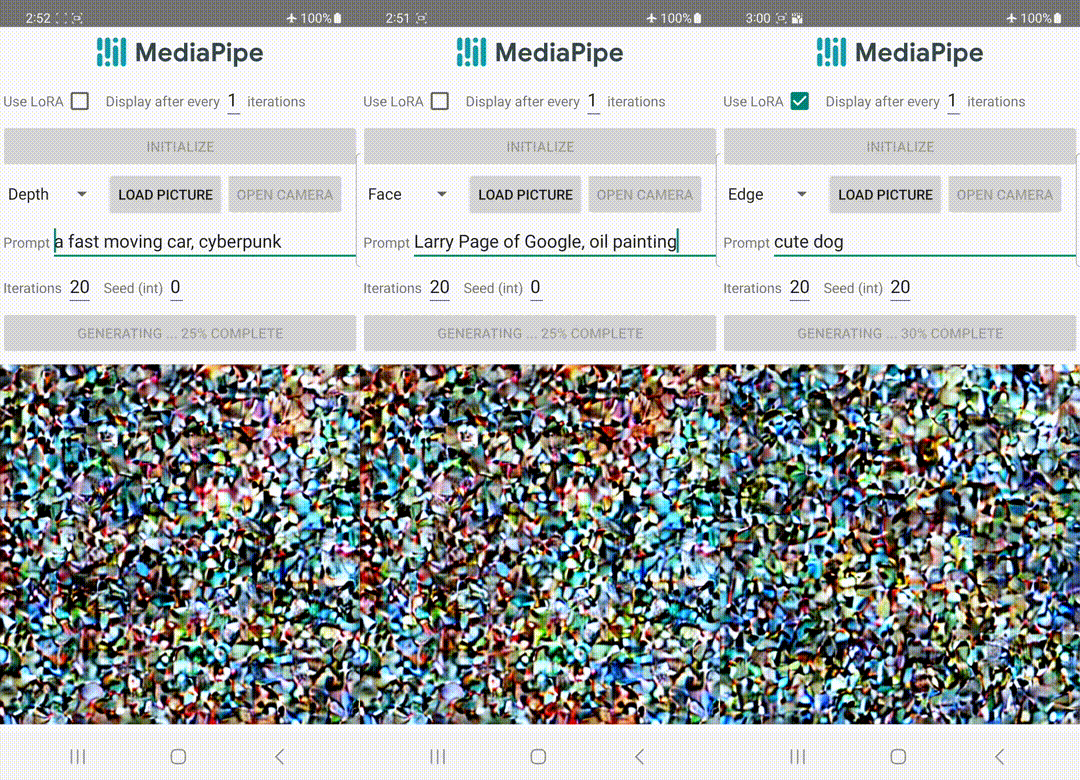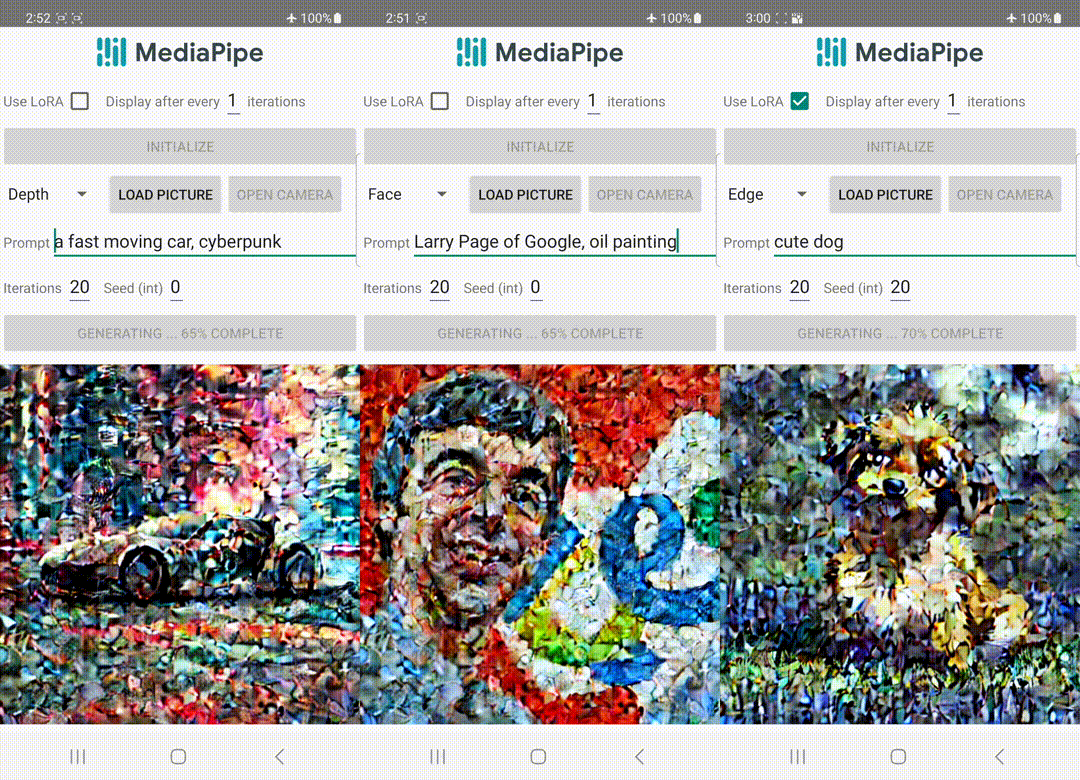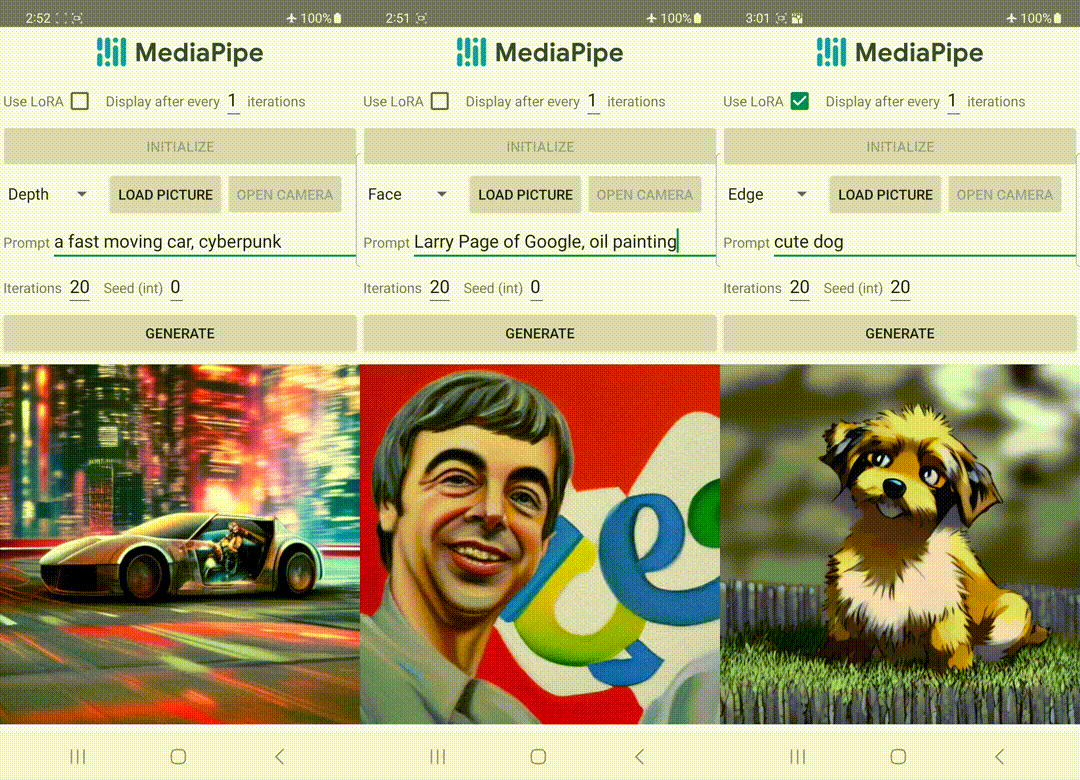
在这项工作中,我们使用MediaPipe面部标志、MediaPipe整体标志、深度图和Canny边缘为基于扩散的文本到图像生成模型开发了插件。对于每个任务,我们从一个网络规模的图像文本数据集中选择约10万张图像,并使用相应的MediaPipe解决方案计算控制信号。我们使用PaLI的优化标题来训练这些插件。
面部标志
MediaPipe面部标志任务计算人脸的478个标志点(带有注意力)。我们使用MediaPipe中的绘图工具来渲染人脸,包括脸部轮廓、嘴巴、眼睛、眉毛和虹膜,使用不同的颜色。下表显示了通过条件为面部网格和提示生成的随机样本。作为比较,ControlNet和插件都可以通过给定的条件控制文本到图像的生成。
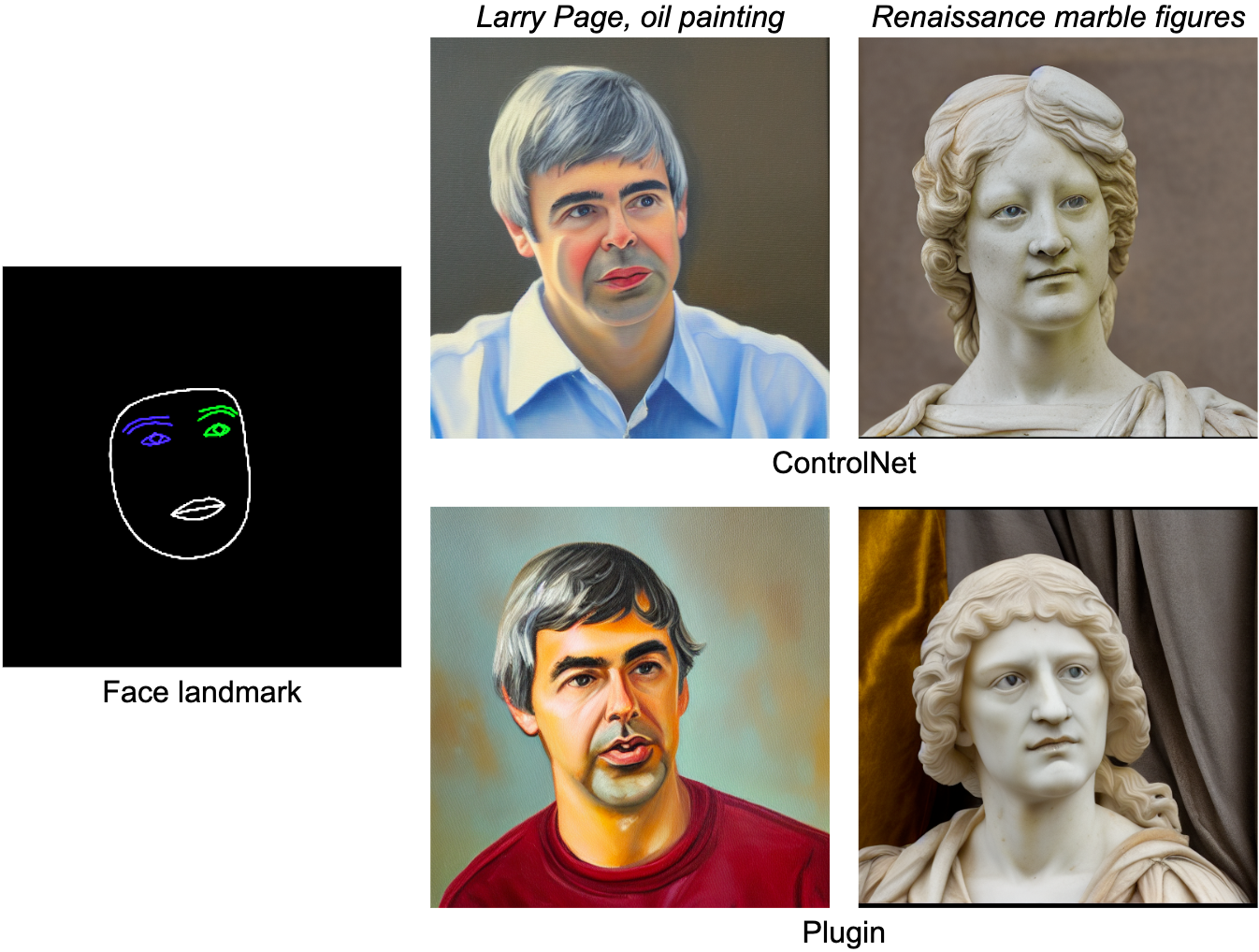 |
| 用于文本到图像生成的面部标志插件,与ControlNet进行比较。 |
整体地标
MediaPipe整体地标任务包括身体姿势、手部和面部网格的地标。在下面,我们通过对整体特征进行条件化生成各种风格化图像。
 |
| 针对文本到图像生成的整体地标插件。 |
深度
 |
| 针对文本到图像生成的深度插件。 |
Canny边缘
 |
| 针对文本到图像生成的Canny边缘插件。 |
评估
我们对面部地标插件进行定量研究,以展示模型的性能。评估数据集包含5千个人类图像。我们通过广泛使用的指标,Fréchet Inception Distance (FID)和CLIP分数来比较生成质量。基础模型是预训练的文本到图像扩散模型。这里我们使用了稳定扩散v1.5。
如下表所示,无论是ControlNet还是MediaPipe扩散插件,在FID和CLIP分数方面,都比基础模型有更好的样本质量。与ControlNet不同,MediaPipe插件每生成一张图像只运行一次扩散步骤。我们在服务器机器(带有Nvidia V100 GPU)和手机(Galaxy S23)上测量了这三种模型的性能。在服务器上,我们使用50个扩散步骤运行了所有三个模型,在手机上,我们使用MediaPipe图像生成应用程序进行了20个扩散步骤。与ControlNet相比,MediaPipe插件在保持样本质量的同时,推理效率明显优势。
| 模型 | FID↓ | CLIP↑ | 推理时间 (s) | |||||
| Nvidia V100 | Galaxy S23 | |||||||
| 基础 | 10.32 | 0.26 | 5.0 | 11.5 | ||||
| 基础 + ControlNet | 6.51 | 0.31 | 7.4 (+48%) | 18.2 (+58.3%) | ||||
| 基础 + MediaPipe插件 | 6.50 | 0.30 | 5.0 (+0.2%) | 11.8 (+2.6%) |
| FID、CLIP 和推理时间的定量比较。 |
我们在从中档到高端的各种移动设备上测试了插件的性能。我们在下表中列出了一些代表性设备上的结果,涵盖了 Android 和 iOS。
| 设备 | Android | iOS | ||||||||||
| Pixel 4 | Pixel 6 | Pixel 7 | Galaxy S23 | iPhone 12 Pro | iPhone 13 Pro | |||||||
| 时间 (ms) | 128 | 68 | 50 | 48 | 73 | 63 |
| 插件在不同移动设备上的推理时间(ms)。 |
结论
在这项工作中,我们提出了 MediaPipe,一种可移植的条件文本到图像生成插件。它将从条件图像中提取的特征注入到扩散模型中,从而控制图像生成。可移植插件可以连接到在服务器或设备上运行的预训练扩散模型。通过在设备上完全运行文本到图像生成和插件,我们实现了生成式人工智能更灵活的应用。
致谢
我们要感谢所有为这项工作做出贡献的团队成员:Raman Sarokin 和 Juhyun Lee 提供的 GPU 推理解决方案;Khanh LeViet、Chuo-Ling Chang、Andrei Kulik 和 Matthias Grundmann 提供的领导力。特别感谢 Jiuqiang Tang、Joe Zou 和 Lu wang,他们使这项技术和所有演示在设备上运行。