你必须推动这些维度:DreamEditor是一个使用文本提示编辑3D场景的AI模型


近年来,3D计算机视觉领域涌现出了大量的NeRF技术。它们作为一种开创性的技术,在场景的重建和合成中实现了突破。NeRF技术可以从多视图图像的集合中捕捉并建模底层的几何和外观信息。
通过利用神经网络,NeRF技术提供了一种超越传统方法的数据驱动方法。NeRF技术中的神经网络学习表示场景几何、光照和视角相关外观之间复杂关系的能力,实现高度详细和逼真的场景重建。NeRF技术的关键优势在于其能够从场景中的任意视角生成逼真的图像,甚至在原始图像集未捕捉到的区域。
NeRF技术的成功为计算机图形学、虚拟现实和增强现实带来了新的可能性,实现了与现实世界场景非常相似的沉浸式和交互式虚拟环境的创建。因此,该领域对进一步推进NeRF技术表现出了浓厚的兴趣。
- 这项人工智能研究证实,当使用外部存储器增强时,基于Transformer的大型语言模型具有计算普适性
- 斯坦福大学的研究人员介绍了Parsel:一种人工智能AI框架,可以通过代码实现和验证复杂算法,并支持大型语言模型LLMs的自动化实施
- Binghamton大学的研究人员为大家引入了一种增强隐私的匿名化系统(我的脸,我的选择),以便每个人都能在社交照片分享网络中对自己的脸部拥有控制权
NeRF技术的一些缺点限制了它们在现实场景中的适用性。例如,由于高维神经网络特征隐式编码了形状和纹理信息,编辑神经场是一个巨大的挑战。尽管一些方法试图使用已探索的编辑技术来解决这个问题,但它们往往需要大量用户输入,并且难以实现精确和高质量的结果。
编辑NeRF技术的能力可以为现实应用带来新的可能性。然而,迄今为止,所有的尝试都不足以解决这些问题。好了,我们在这个领域有了一个新的参与者,它被称为DreamEditor。

DreamEditor是一个用户友好的框架,可以使用文本提示直观和方便地修改神经场。通过使用基于网格的神经场表示场景,并采用逐步编辑框架,DreamEditor可以实现广泛的编辑效果,包括重新纹理化、对象替换和对象插入。
网格表示通过将2D编辑掩码转换为3D编辑区域,实现精确的局部编辑,同时解耦几何和纹理以防止过度变形。逐步框架将预训练的扩散模型与得分蒸馏采样相结合,使得基于简单文本提示的编辑高效准确。
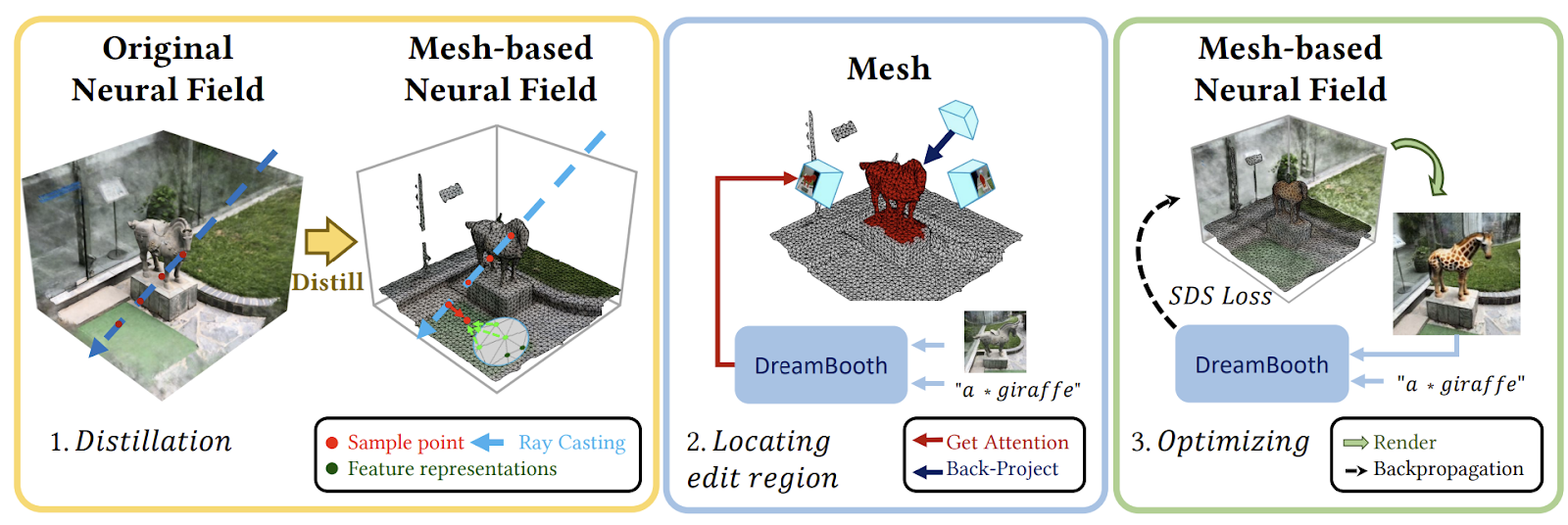
DreamEditor通过三个关键阶段,促进直观精确的基于文本引导的3D场景编辑。在初始阶段,将原始神经辐射场转换为基于网格的神经场。这种网格表示使得空间选择性编辑成为可能。转换后,它使用在特定场景上训练的定制的文本到图像(T2I)模型,捕捉文本提示中关键词与场景视觉内容之间的语义关系。最后,使用T2I扩散模式将编辑修改应用于神经场内的目标对象。
DreamEditor 可以在保持高度保真度和逼真度的同时,准确且逐步地编辑3D场景。这种逐步的方法,从基于网格的表示到精确定位和通过扩散模型进行控制的编辑,使得DreamEditor 能够在最小化无关区域的不必要修改的同时,实现高度逼真的编辑结果。





