揭秘DreamBooth:个性化文本到图像生成的新工具
探索将无聊的图像转化为创意杰作的技术

简介
想象一下,轻松地生成一张你心爱的小狗在雅典卫城背景下的新图像会带来的喜悦。但你还不满足,你想看看梵高会如何画你最好的朋友,或者如果他是由狮子孕育而生,他会是什么样子 😱!多亏了DreamBooth,这一切都成为了现实,现在可以让任何动物、物品或我们自己从一小部分图像中旅行到幻想中。
虽然我们许多人已经在社交媒体上看到了可以通过这项技术实现的惊人结果,也没有缺乏教程让我们可以尝试在自己的照片上使用它,但很少有人试图回答这个问题:是的,但它到底是如何工作的?
在本文中,我将尽力分解Ruiz等人的科学论文 DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation,从中开始了一切。但是不用担心,我会简化复杂的部分,并在需要一些先前知识的地方给出解释。现在,公平警告,这是一个高级主题,因此我假设您已经掌握了深度学习和相关内容的基础知识。但是,嘿,如果你想深入了解扩散模型或其他酷炫的主题,我会一路上留下一些参考资料。让我们开始吧!
相关工作

在我们深入探讨DreamBooth的方法之前,让我们更仔细地研究与此技术相关的工作和任务。
图像合成
在日常生活的混乱中,你心爱的背包已经太久没有开始它的环球旅行了。现在是时候将它注入令人兴奋的冒险剂量,而你正在计划下一个假期。输入图像合成,将你的主题无缝地融入新的背景中,让你的背包在几秒钟内从大峡谷到波士顿旅行。
如果简单地复制粘贴主题无法满足你对新视角的渴望,一种可能性是探索3D重建技术的应用。然而,需要注意的是,这些技术主要设计用于刚性物体,通常需要大量的起始视图。
DreamBooth引入了一种令人瞩目的能力,可以在新的情境中生成新的姿势,同时平滑地融合关键要素,如照明、阴影和其他与场景相关的方面。以前的方法已经证明了实现这种一致性的挑战。在这篇论文中,这个任务也被称为重新语境化。
文本到图像编辑和合成
基于文本输入的图像编辑是许多热衷于照片编辑软件的用户的秘密梦想。早期的方法,如使用GAN的方法,展示了令人印象深刻的结果,但仅限于编辑人脸等结构良好的场景。
即使是利用扩散模型的新方法也有局限性,通常只限于全局编辑。仅最近的进展,如Text2LIVE,允许局部编辑。然而,这些技术都不允许在新的情境中生成给定的主题。
虽然像Imagen、DALL·E 2和Stable Diffusion这样的文本图像合成模型取得了重大进展,但在合成图像中实现细粒度控制和保持主题身份仍然面临着巨大的挑战。
可控制的生成模型
为了避免主题修改,许多方法依赖于用户提供的遮罩来限制要修改的区域。反演技术(例如 DALL·E 2 所使用的技术)提供了一种有效的解决方案,可以在修改上下文的同时保留主题。
Prompt-to-Prompt 可以在不需要输入遮罩的情况下进行本地和全局编辑。
然而,这些方法在生成主题的新样本时没有充分保留其身份。
虽然一些基于 GAN 的方法专注于生成实例变化,但它们通常存在一些限制。例如,它们主要设计用于面部领域,需要许多输入主题的实例,难以处理独特的主题,并且无法保留重要的主题细节。
最后,最近 Gal et. al. 提出了 Textual Inversion,这是一种具有与 DreamBooth 相似特征的方法,但正如我们将看到的那样,它受到其基于的冻结扩散模型的表现力的限制。
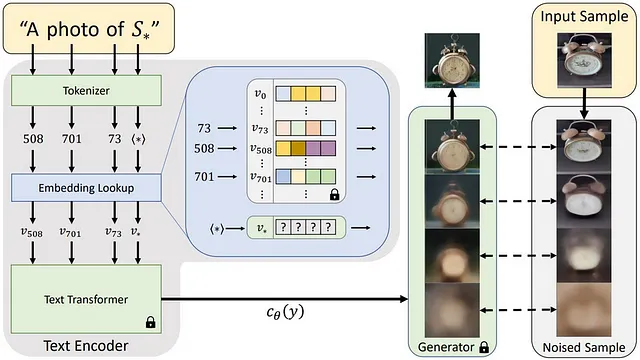
由于这是作者用来比较 DreamBooth 的工作,因此值得简要介绍一下。
Textual Inversion 从预训练扩散模型(例如 Latent Diffusion)开始,并定义一个新的占位符字符串 S*,以表示要学习的新概念。此时,保持扩散模型冻结,从仅 3-5 张图像进行微调,类似于 DreamBooth。如果这个简要描述不够清楚,请等待您阅读与这项工作有许多共同点的 DreamBooth 的更详细描述。
方法
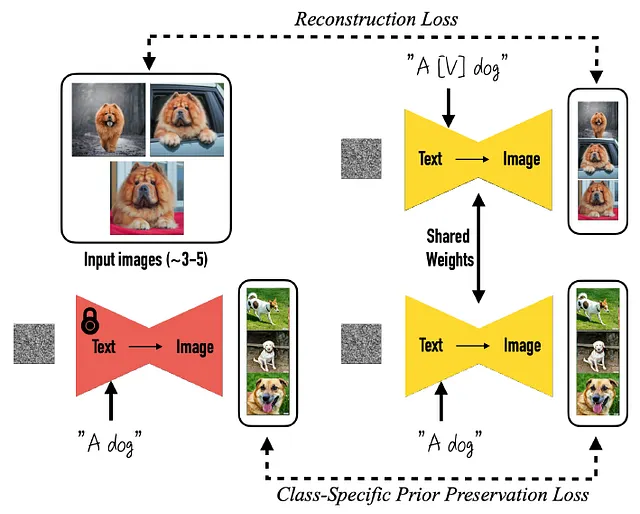
在详细描述 DreamBooth 的组件之前,让我们先看一下这项技术的示意图:
- 选择您的喜欢的主题的 3-5 张图像,可以是动物、物体,甚至是艺术风格等抽象概念。
- 将这个概念与一个稀有单词相关联,该单词对应于一个唯一的标记,从现在开始将代表它,在科学论文中,作者将这个词称为 [V]。
- 使用类似“一个 [V] [类名]”这样的简单提示,对感兴趣的主题的图像进行微调,例如,“一只 [V] 狗”,如果输入图像是您的狗的照片。
- 由于我们正在微调模型的所有参数,因此存在这样的风险,即此时所有狗(或无论我们的主题是什么)都将变成与我们的输入图像相同。为避免模型的降级,我们使用“一只狗”(或“一个 [类名]”)这样的提示从我们的冻结模型生成图像,并添加一个损失,当我们为此提示微调的模型生成的图像偏离由冻结模型生成的图像时进行惩罚。
好的,现在我们对该过程有了高层次的了解,让我们更详细地了解各个组件。
文本到图像扩散模型
您真的想了解扩散模型以及特别是稳定扩散这样的潜在扩散模型如何工作吗?请阅读下面我的先前文章,当您完成后我会在这里等您!
论文解析 – 使用潜在扩散模型进行高分辨率图像合成
虽然 OpenAI 已经在自然语言处理领域中以他们的生成文本模型占据了主导地位,但他们的图像…
towardsdatascience.com
好的,也许你不想要整个解释,那么我将在这里给出扩散模型背后的直觉,非常简单。

- 取一个图像x0并添加一定量的噪音(例如高斯噪音),与某个时间步长t成比例。如果t为零,则添加的噪音为零,如果t>0,则添加的噪音将随着t的增加而增加,直到得到一个只是噪音的图像。
- 训练一个模型,例如U-Net,通过将时间步长t和损坏的图像作为输入,来预测无噪声的图像(或已添加的噪声)。
- 此时,我们已经训练了一个可以从图像中去除噪声的模型,我们可以从只由噪声组成的图像中进行采样,并逐渐去除它(一次性去除效果很差),通过预测没有噪声的图像或预测噪声并将其从图像中减去。
- 前三个点描述了无条件的扩散模型。为了基于文本提示产生有条件的输出,文本使用像CLIP这样的模型进行编码,或者使用BERT,T5和其他语言模型进行编码。这个编码步骤允许集成额外的信息,然后将其与损坏的图像和时间步长t一起作为输入输入到模型中。
论文中的作者使用了两个扩散模型:Google的Imagen(DreamBooth也是来自Google Research)和Stability AI的Stable Diffusion,这是主要的开源文本到图像模型。
Imagen采用多分辨率策略来提高生成图像的质量。最初,使用低分辨率64×64图像训练扩散模型。低分辨率模型的输出随后由两个在更高分辨率(256×256和1024×1024)上操作的扩散模型进行升采样。第一个模型专门捕获宏观细节,而后续模型通过利用低分辨率模型生成的图像的调节效果来优化输出。这种迭代的细化有助于生成具有更好质量和保真度的高分辨率图像。
Stable Diffusion则作为潜在扩散模型,引入了三步方法来提高训练和生成高分辨率图像的效率。最初,训练变分自编码器(VAE)来压缩高分辨率图像。从这一点开始,该过程与标准扩散模型非常相似,但有一个关键区别:不使用原始图像作为输入,而是利用VAE编码器生成的潜在表示。随后,逆扩散过程的输出将使用VAE解码器恢复到原始分辨率。为了更全面地了解整个过程,我在上述文章中进行了更详细的阐述。
文本到图像模型的个性化
DreamBooth旨在将主体实例(例如您的狗)放置在模型的输出域中,使模型能够在查询时生成主体的新图像。与GAN不同,扩散模型的优点在于它们能够有效地将新信息纳入其领域,同时保留对先前数据的知识并避免过度拟合有限的训练图像集。
为少样本个性化设计提示
如上所述,该模型使用结构简单的提示进行训练,结构为“一个[标识符][类名]”。其中,[标识符]表示与主题相关联的不同标识符,[类名]用作主题类别的一般描述(例如cat,dog,watch等)。作者将类名纳入提示中,以建立一种关于一般类和我们个体主题之间的联系,观察到使用错误或缺失的类名会导致更长的训练时间和语言漂移,最终影响性能。本质上,主要目的是利用模型对类别所具有的现有知识,利用特定类别与我们的主题之间的关系,使我们能够在各种情境下生成主题的新姿势和变化。
罕见令牌标识符
该论文强调,常见的英语单词在这种情况下并不理想,因为模型需要将它们从原来的含义中分离出来,并重新整合它们以指代我们的主题。
为了解决这个问题,作者提出使用一个在语言和扩散模型中都具有较弱先验的标识符。虽然选择像“xxy5syt00”这样的随机字符可能一开始看起来很吸引人,但它会带来潜在的风险。需要考虑到,分词器可能会将每个字母单独分词。那么,解决方案是什么?最有效的方法是在词汇表中识别不常见的令牌,然后在文本空间中反转这些令牌。这可以最大程度地减小标识符具有强先验的可能性。
有趣的是,大多数教程都使用“sks”进行此目的,但正如其中一位作者所指出的,这个看似无害的词可能会产生副作用…
类特定先验保留损失

与文本反转不同,DreamBooth微调模型的所有层以最大化性能。不幸的是,这样做会遇到众所周知的问题:语言漂移,即当模型最初在广泛的文本语料库上进行预训练,然后针对特定任务进行微调时,它逐渐减少对语言语法和语义的理解。
另一个问题是可能导致输出多样性降低。这可以在第6图的第二行中观察到,该模型除非进一步适应,否则有倾向于仅复制输入图像中的姿势。当模型训练时间更长时,这种效应变得更加明显。
为了缓解这些问题,作者引入了一个类特定的先验保留损失,让我们看一下它的总体损失公式,然后解释其组成部分:
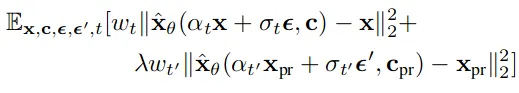
第一部分是标准的L2去噪误差,对于任何扩散模型都是典型的。α_t将初始图像x缩放,然后加上高斯噪声ε∼N(0,I),乘以σ_t。随机变量z_t:=α_t * x +σ_t * ε然后具有分布N(α_t * x,σ_t²)。此时模型x ˆ _θ将尝试从z_t和条件向量c = Γ(P)(在DreamBooth的情况下,Γ是T5,而提示P的形式是“a [标识符] [类名]”)中预测原始图像。
第二部分是先验保留损失,其中我们有x _pr而不是x,它是由模型使用冻结权重(在微调之前)从随机初始噪声z _1∼N(0,I)和条件向量c _pr = Γ(“a [类名]”)生成的图像。这部分会将模型推向从其损坏的版本重新获得x _pr,从而推动模型生成类似于微调过程之前为主题类的实例生成的图像。
最后,w_t和w_t’是与噪声时间表有关的项,λ定义了要给予两个损失的相对权重。
实验

数据集
实验所用的数据集是由作者生成的,包括30个主题,包括背包或太阳镜等独特物品和狗、猫等动物。在30个主题中,有21个是物品,9个是真实的主题/宠物。
然后作者定义了25个提示:20个物品重新文本化和5个属性修改提示;10个重新文本化,10个配件化和5个属性修改提示,用于真实的主题/宠物。
评估指标
为了评估,每个主题和每个提示生成四个图像,共计3000个图像。
为了衡量主题保真度,使用了CLIP-I和DINO。
CLIP-I在先前的工作中已经使用过,它计算生成和真实图像的CLIP嵌入之间的平均对比余弦相似度。CLIP被训练为使文本描述与它所指的图像具有相同的嵌入,因此如果两个图像表示相同的文本,则它们的嵌入将相似。
DINO是作者引入的一种新指标,类似于CLIP-I,但不使用CLIP生成嵌入,而是使用ViT-S/16 DINO生成嵌入,这是一个自我监督训练的模型。
在论文中,观察到CLIP-I由于CLIP的训练方式,不能区分可能具有非常相似文本描述的不同主题。另一方面,DINO(模型,而不是指标)以自我监督的方式进行训练,这有助于区分主题或图像内的独特特征。因此,他们将DINO视为他们的主要指标。
最后,引入了第三个指标CLIP-T,用于衡量另一个重要方面:提示保真度,即生成的图像是否接近输入提示。
CLIP-T与先前的指标类似,测量两个用CLIP获得的嵌入之间的平均余弦相似度:一个来自提示,另一个来自图像。重要的是要注意,CLIP专门训练用于生成与相应图像的文本嵌入相似的文本嵌入。
比较
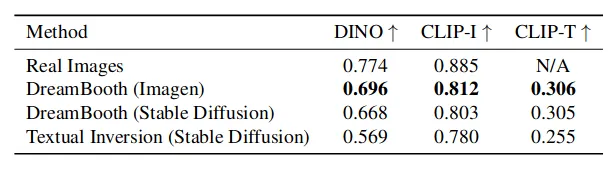
如表1所示,使用DINO和CLIP-T指标测量时,DreamBooth明显优于Textual Inversion,而使用CLIP-I测量时距离较近,但是如前所述,CLIP-I不是衡量特定主题保真度的好指标。

很难找到与人们判断更好或更差的结果完全相关的指标。因此,作者还测量了72个用户的偏好。结果表明,偏好DreamBooth的用户百分比,无论是主题保真度还是提示保真度,都比单纯查看前面的指标所得出的结论要大。我们可以通过查看论文中的图4中显示的图像自行判断,其中两种方法之间的巨大差异是明显的,至少对于这个特定的例子是这样的。
结论
图像生成和生成式人工智能领域近年来受到了相当大的关注。图像合成的进步,特别是通过扩散模型的使用,推动了这个领域的发展。
在本文中,我们深入研究了DreamBooth的科学论文——这是一种令人印象深刻的解决方案,它能够在保持对所需主题的忠实度的同时,实现生成具有不同姿势和背景的新图像。这种创新性的方法展示了在图像合成领域取得的显著进展,并具有未来发展的巨大潜力。
感谢您抽出时间阅读本文,并请随时留下评论或联系我分享您的想法或提出任何问题。要了解我的最新文章,请关注我在小猪AI、LinkedIn或Twitter上的动态。
使用我的推荐链接加入小猪AI – Mario Namtao Shianti Larcher
阅读Mario Namtao Shianti Larcher(和小猪AI上成千上万的其他作者的)每个故事。您的会员费用…
小猪AI.com






