掌握机器学习工作流的艺术:Transformer、Estimator和Pipeline的综合指南
优化结果,编写无缝代码
“只要我现在能够理解它并且好处是它起作用了!我设法用我的模型神奇地产生了一个相当不错的结果,真是个好方法结束今天的工作。”
不,我在这里告诉你这还不够好。实际上,在开始机器学习项目时,许多新手和中级分析师都急于生产出缺乏适当工作流程的中等水平模型。虽然有时手头的问题很简单,但是没有遵循适当的工作流程往往会导致难以检测到的潜在问题——例如数据泄漏。
“只要它能起作用,就足够好了。”让我告诉你,这并不是这样的。让我们模拟一个快速场景,您必须向高级分析师解释您的工作。以下是一些问题。如果今天它起作用了,那么它是否保证明天也能起作用并且容易重现?您能在由200多个单元格组成的笔记本中解释模型工作流程的预处理步骤吗?如果您以这种方式进行交叉验证,那么是否会暴露测试数据集并使模型性能膨胀?这些是艰难的问题,不是吗?
让我告诉你,实际上,你并不孤单,你也不是那么遥远。即使参加了多个商业分析和机器学习课程,我的讲师也没有分享我下面分享的工具和技巧。当Scikit-Learn首次介绍时,我会说它们不是每个人都关注的重点课程。然而,它们产生了一致的结果,从而极大地改进了您的代码编写。想象一下,轻松处理您的数据,无缝转换特征并训练复杂的模型,同时保持您的代码的优雅和简单。是的,这是我们在本全面指南结束时的目标,并且希望您会被说服采用以下实践。让我们开始吧。
目录
- 采用流水线的原因
- 评估器
- 转换器
- 流水线
- 自定义评估器
- 特征联合
- 真实数据集示例:使用网格搜索CV的银行营销
采用流水线的原因
1.简化工作流程。利用流水线可以无缝地集成数据预处理和建模旅程中的多个步骤。它使您能够将各种转换器和评估器链接在一起,确保从数据预处理到模型训练和评估的清晰,简洁和自动化的流程。通过在管道中封装您的预处理和建模步骤,您的代码变得更加有组织,模块化和易于理解。它改进了您的代码外观和可维护性,因为每个步骤都被清楚地定义。将管道中的每个步骤视为独立的,您可以更改或添加步骤,而不必担心一个预处理步骤会如何影响另一个预处理步骤!
2.防止数据泄漏。可怕的反面角色,每个分析师的宿敌。当测试数据集的信息无意中影响预处理步骤或模型训练时,可能会发生数据泄漏,导致过于乐观的性能估计。在某种程度上,您正在泄漏有关将要进行测试的信息,并使您的学习模型事先看到将要进行测试的内容。显然,“他试图加速”。通常,经验法则是仅拟合训练数据集,然后转换训练和测试数据集。下面的代码显示了一些人的错误之处。此外,通常您会有多个预处理步骤,这些步骤通常涉及转换器,例如StandardScaler(),MinMaxScaler(),OneHotEncoder()等。想象一下,在整个工作流程中必须多次执行拟合和转换过程,那不是很令人困惑和不便吗?
ss = StandardScaler()X_train_scaled = ss.fit_transform(X_train)X_test_scaled = ss.fit_transform(X_test)#Some other variationsX_train_scaled = ss.fit(X_train)X_test_scaled = ss.transform(X_test)3. 超参数调整和交叉验证。 使用技术如GridSearchCV轻松地调整管道中所有步骤的超参数。然而,错误通常在这个特定步骤中被忽略。让我们看一个简单的例子。
from sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import train_test_split, cross_val_scorefrom sklearn.feature_selection import SequentialFeatureSelectorfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import RandomForestClassifierX, y = load_breast_cancer(return_X_y=True, as_frame=True)#Without Pipelineselect = SequentialFeatureSelector(RandomForestClassifier(n_estimators=100), n_features_to_select=8, direction='forward').fit(X,y)X_selected = select.transform(X)logreg = LogisticRegression()np.mean(cross_val_score(estimator=logreg, X=X_selected, y=y))#With Pipelinepipe = Pipeline([("select", SequentialFeatureSelector(RandomForestClassifier(n_estimators=100), n_features_to_select=8, direction='forward')), ("log", LogisticRegression())])np.mean(cross_val_score(estimator=logreg, X=X, y=y))尝试运行这两个示例:尽管交叉验证得分差不多,但没有Pipeline的部分会泄漏信息,因为特征选择步骤是在整个数据集上执行的。当我们到达交叉验证步骤时,数据集被分成训练和验证集,它们本质上来自同一来源(训练集在执行特征选择时从验证集之前学习了信息)。如果您发现难以理解这部分,请尝试重新阅读段落并自己编写代码以内化。
估计量
在我们深入研究Pipeline的功能之前,让我们先转向构成Pipeline的组件——估计量。我们将在下一节中涉及其他组件——变压器、预测器和模型。
很多人经常对Scikit-learn中的估计器这个术语感到困惑。人们往往将估计器与预测能力联系起来,即特别是与predict方法联系起来。虽然这个说法有一些真实性,但这只是最好的半真实性。估计器基本上是Scikit-learn库的构建块。估计器是一种工具,可以从您的训练集中学习,创建一个可以对新数据进行预测或推断的模型。由于所有估计器都有fit方法来从训练集中学习,它们继承自BaseEstimator。
从BaseEstimator本身来看,没有predict方法,只有fit。估计器不一定需要有predict方法,尽管有些估计器确实有。具有预测方法的估计器试图基于学习的模型对新的未见数据进行预测。例如,回归器和分类器,如线性回归、随机森林分类器、梯度提升分类器等,都是具有predict方法的估计器。
更进一步,让我们窥探一下LogisticRegression类的原始文档²。在下面的代码片段中,我们观察到该类从BaseEstimator继承fit方法,从LinearClassifierMixin继承predict方法。

变压器
变压器是一种具有transform方法的估计器类型。请注意,这里的“变压器”一词特指Scikit-learn上下文。它不应与最近几年在神经网络架构中获得更多关注和重要性的变压器混淆或混淆。
简而言之,变压器的作用是以某种方式转换/操作预测器(X),使其准备好被机器学习算法消耗。这可以是使用著名的工具(例如StandardScaler和MinMaxScaler)对连续预测变量进行缩放,或使用OneHotEncoder或OrdinalEncoder对分类预测变量进行编码。
</
更进一步,变换器具有适合-变换机制,在使用 fit 方法从训练数据中学习后,使用 transform 方法将学习到的变换应用于训练和测试数据。这确保了相同的变换一致应用。
更进两步,为了遵循 Scikit-learn API 实现规则,变换器通常从 BaseEstimator 继承其 fit 方法,从 TransformerMixin 继承其 transform 方法。让我们查看原始文档中的 StandardScaler 库³。

ColumnTransformer ⁵
有时,您需要根据需要仅针对某些列应用特定的变换。例如,对于没有特定等级的分类特征应用 OneHotEncoder ,对于具有特定等级和排序的分类特征应用 OrdinalEncoder (即对于 T 恤尺码,我们通常有尺码排序要遵循,例如 XS<S<M<L<XL)。我们可以使用 ColumnTransformer 实现此分离。
from sklearn.compose import ColumnTransformerohe_categorical_features = ['a', 'b', 'c']ohe_categorical_transformer = Pipeline(steps=[ ('ohe', OneHotEncoder(handle_unknown='ignore', sparse_output=False, drop='first'))])orde_categorical_features = ['d', 'e', 'f']orde_categorical_transformer = Pipeline(steps=[ ('orde', OrdinalEncoder(dtype='float'))])col_trans = ColumnTransformer( transformers=[ ('ohe_categorical_features', ohe_categorical_transformer, ohe_categorical_features), ('orde_categorical_features', orde_categorical_transformer, orde_categorical_features), ], remainder='passthrough', n_jobs=-1,)正如您所预期的那样,我们将在代码中稍后将变量 col_trans 作为整体管道的一部分放置。简单而优雅。
Pipeline
Pipeline ⁶ 类以顺序方式执行管道中的评估器,将一个步骤的输出作为下一个步骤的输入传递。这实质上允许发生链接概念。从 Scikit-learn 文档⁴ 中,以下是评估器有资格作为管道的一部分的标准。
为了能够与
pipeline.Pipeline一起在任何除最后一步以外的地方使用,它需要提供fit或fit_transform函数。为能够在任何数据上评估管道而不是训练集,它还需要提供transform函数。对于管道中的最后一步没有特殊要求,除了它具有fit函数。
使用 Pipeline,我们消除了在每个评估器和/或变换器上调用 fit 和 transform 方法的冗余步骤。从管道直接调用方法 fit 一次即可。背后的工作原理是它在第一个评估器上调用 fit,然后对输入进行 transform 并将其传递到下一个评估器。确实,管道的表现与最后一个评估器的表现一样好(它具有管道中最后一个评估器的所有方法)。如果最后一个评估器是回归器,则可以将 Pipeline 用作回归器。如果最后一个评估器是变换器,则管道也是变换器。
下面是如何使用 Pipeline 类的示例。
imputer = KNNImputer(n_neighbors=5)feature_select = SequentialFeatureSelector(RandomForestClassifier(n_estimators=100), n_features_to_select=8, direction='forward')log_reg = LogisticRegression()pipe = Pipeline([("imputer", imputer), ("select", feature_select), ("log", log_reg)])简单来说,Pipeline 的参数是一个按顺序执行的元组列表。元组的第一个元素是您设置的任意名称,用于标识评估器,有点像 ID。同时,第二个元素是评估器对象。是不是很简单?如果您不擅长命名,Scikit-learn 提供了简写的 make_pipeline 方法,可以避免需要起名字的烦恼。
from sklearn.pipeline import make_pipelineimputer = KNNImputer(n_neighbors=5)feature_select = SequentialFeatureSelector(RandomForestClassifier(n_estimators=100), n_features_to_select=8, direction='forward')log_reg = LogisticRegression()make_pipeline(imputer, feature_select, log_reg)自定义评估器
到目前为止,像 StandardScaler 和 MinMaxScaler 这样的方法看起来很好,对许多情况都适用。问题是,如果您有自己定制的方法来操作和预处理数据集呢?您还能将其整洁地整合到 Pipeline 类中吗?答案是肯定的!有两种实现方式——利用 FunctionTransformer 或编写自己的自定义类。
假设您想对数据集的一部分进行 Box-Cox 转换。
from scipy.stats import boxcoxfrom sklearn.preprocessing import FunctionTransformerfrom sklearn.compose import ColumnTransformerboxcox_features = ['x1', 'x2']boxcox_transformer = Pipeline(steps=[ ('boxcox', FunctionTransformer(lambda x: boxcox(x)[0])])col_trans = ColumnTransformer( transformers=[ ('boxcox_features', boxcox_transformer, boxcox_features), ... ], remainder='passthrough', n_jobs=-1,)第二种方法是编写自己的自定义类,该类继承自 BaseEstimator 和 TransformerMixin(如果您正在编写变换器评估器),如果您正在编写具有分类任务的评估器,则继承自 ClassifierMixin。
假设您要编写一个类,以消除异常值并将其整合到您的管道中。
def outlier_thresholds(df: pd.DataFrame, col: str, q1: float = 0.05, q3: float = 0.95): #1.5 as multiplier is a rule of thumb. Generally, the higher the multiplier, #the outlier threshold is set farther from the third quartile, allowing fewer data points to be classified as outliers return (df[col].quantile(q1) - 1.5 * (df[col].quantile(q3) - df[col].quantile(q1)), df[col].quantile(q3) + 1.5 * (df[col].quantile(q3) - df[col].quantile(q1)))def delete_potential_outlier_list(df: pd.DataFrame, cols: list) -> pd.DataFrame: for item in cols: low, high = outlier_thresholds(df, col) df.loc[(df[col]>high) | (df[col]<low),col] = np.nan return dfclass OutlierRemove(BaseEstimator, TransformerMixin): def __init__(self, outlierlist): self.outlierlist = outlierlist def fit(self, X, y=None): return self def transform(self,X,y=None): return delete_potential_outlier_list(X, self.outlierlist)我想特别提醒您注意 OutlierRemove 类。在这里,我们有一个返回 self 的 fit 方法,以允许我们继续链接,以及执行异常值删除的 transform 方法。之后,我们只需像以下代码一样将类整合到我们的 Pipeline 中即可
pipe = Pipeline([("remove_outlier", OutlierRemove(["a", "b", "c"])), ("imputer", imputer), ("select", feature_select), ("log", log_reg)])FeatureUnion
这里是令人困惑的地方——FeatureUnion 的作用与 Pipeline 相同,但它们的工作方式有所不同。在 FeatureUnion 中,fit 和 transform 方法不是按顺序一个接一个地执行的。每个转换器评估器都独立地适合于数据,然后并行应用 transform 方法。最终结果然后合并在一起。请看下面的代码。在这里,我们可以使用 FeatureUnion 并行运行数值和类别预测器的预处理,因为它们彼此独立。这样可以实现更快、更高效的操作。
from sklearn.pipeline import FeatureUnion
standard_numerical_features = ['x1', 'x2']
standard_numerical_transformer = Pipeline(steps=[
('remove_outlier', OutlierTrans(standard_numerical_features)),
('scale', StandardScaler())
])
ohe_categorical_features = ['x3', 'x4']
ohe_categorical_transformer = Pipeline(steps=[
('ohe', OneHotEncoder(handle_unknown='ignore', sparse_output=False, drop='first'))
])
feature_union = FeatureUnion(
transformers=[
('standard_numerical_features', standard_numerical_transformer),
('ohe_categorical_features', ohe_categorical_transformer),
],
n_jobs=-1,
)
pipeline = Pipeline([
('feature_union', feature_union),
('model', RandomForestClassifier())
])
pipeline.fit(X_train, y_train)
真实数据集实例:采用网格搜索交叉验证的银行营销
这里,我想通过一个受葡萄牙金融机构启发的真实数据集来说明上面的内容。该数据集可在UCI机器学习存储库¹上公开使用,并进行引用。
让我跳过所有的探索性数据分析和可视化,直接进入管道的建模。
1. 导入数据集
import pandas as pd
df = (pd
.read_csv('../../dataset/bank_marketing/bank-11k.csv', sep=',')
.rename(columns={'y': 'deposit'})
.pipe(lambda df_: df_.assign(deposit=np.where(df_.deposit == "no", 0, 1)))
)简而言之,上面的代码所做的是:
- 使用逗号分隔符导入数据集
- 将列“y”重命名为“deposit”
- 将存款列从否和是编码为0和1
2. 训练测试拆分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop(columns=['deposit']), df[['deposit']].values.ravel(), test_size=0.2, random_state=42)3. 编写额外的3个自定义类
from sklearn.base import BaseEstimator, TransformerMixin
#Custom class #1: switch between classifiers
class ClfSwitcher(BaseEstimator):
#默认情况下,运行XGBClassifier
def __init__(self, estimator = XGBClassifier()):
self.estimator = estimator
def fit(self, X, y=None, **kwargs):
self.estimator.fit(X, y)
return self
def predict(self, X, y=None):
return self.estimator.predict(X)
def predict_proba(self, X):
return self.estimator.predict_proba(X)
def score(self, X, y):
return self.estimator.score(X, y)
#Custom class 2: remove outliers
def outlier_thresholds(df: pd.DataFrame,
col: str,
q1: float = 0.05,
q3: float = 0.95):
return (df[col].quantile(q1) - 1.5 * (df[col].quantile(q3) - df[col].quantile(q1)),
df[col].quantile(q3) + 1.5 * (df[col].quantile(q3) - df[col].quantile(q1)))
def delete_potential_outlier_list(df: pd.DataFrame,
cols: list) -> pd.DataFrame:
for item in cols:
low, high = outlier_thresholds(df, col)
df.loc[(df[col]>high) | (df[col]<low),col] = np.nan
return df
class OutlierTrans(BaseEstimator, TransformerMixin):
def __init__(self, outlierlist):
self.outlierlist = outlierlist
def fit(self, X, y=None):
return self
def transform(self,X,y=None):
return delete_potential_outlier_list(X, self.outlierlist)
#Custom class #3: add new columns, drop column, and modify data types
class TweakBankMarketing(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
return (X
.assign(pdays_cat=lambda df_: np.where(df_.pdays < 0, "no contact", "contacted"),
previous_cat=lambda df_: np.where(df_.previous == 0, "no contact", "contacted"),
job=lambda df_: np.where(df_.job == "unknown", np.nan, df_.job),
education=lambda df_: np.where(df_.education == "unknown", np.nan, df_.education),
contact=lambda df_:np.where(df_.contact == "unknown", np.nan, df_.contact),
poutcome=lambda df_: np.where(df_.poutcome == "other", np.nan, df_.contact),
) #添加新的预测变量
.drop(columns=['duration']) #由于数据泄漏而删除预测变量
.astype({'age': 'int8',
'balance': 'int32',
'day': 'category',
'campaign': 'int8',
'pdays': 'int16',
'previous': 'int16',})
.pipe(lambda df_: df_.astype({column: 'category' for column in (df_.select_dtypes("object").columns.tolist())})) #将数据类型从对象转换为类别
)简而言之,上述代码的操作如下:
- 类
ClfSwitcher继承自BaseEstimator。该类的目的是轻松地在分类器之间进行切换。我们将默认分类器设置为XGBoost分类器。 - 方法
outlier_thresholds和delete_potential_outlier_list识别每个列中的异常值并将其设置为NaN。类OutlierTrans是一个转换器,它继承自BaseEstimator和TransformerMixin。方法transform返回上述2个方法。 - 类
TweakBankMarketing是一个自定义类,用于执行自定义转换,例如创建新列、删除不需要的列和相应地更改数据类型。
4. 准备管道
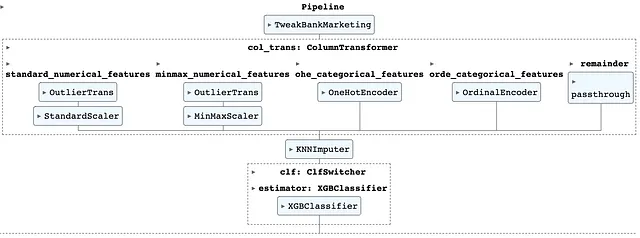
from sklearn.preprocessing import StandardScaler, MinMaxScaler, OrdinalEncoder, OneHotEncoder,from sklearn.impute import KNNImputerfrom sklearn.compose import ColumnTransformerfrom sklearn.pipeline import Pipelinestandard_numerical_features = ['age', 'campaign', 'pdays', 'previous'] # drop pdaysstandard_numerical_transformer = Pipeline(steps=[ ('remove_outlier', OutlierTrans(standard_numerical_features)), ('scale', StandardScaler())])minmax_numerical_features = ['balance']minmax_numerical_transformer = Pipeline(steps=[ ('remove_outlier', OutlierTrans(minmax_numerical_features)), ('scale', MinMaxScaler())])ohe_categorical_features = ['job', 'marital', 'default', 'housing', 'loan', 'contact', 'poutcome', 'pdays_cat', 'previous_cat']ohe_categorical_transformer = Pipeline(steps=[ ('ohe', OneHotEncoder(handle_unknown='ignore', sparse_output=False, drop='first'))])orde_categorical_features = ['education', 'day', 'month']orde_categorical_transformer = Pipeline(steps=[ ('orde', OrdinalEncoder(dtype='float'))])col_trans = ColumnTransformer( transformers=[ ('standard_numerical_features', standard_numerical_transformer, standard_numerical_features), ('minmax_numerical_features', minmax_numerical_transformer, minmax_numerical_features), ('ohe_categorical_features', ohe_categorical_transformer, ohe_categorical_features), ('orde_categorical_features', orde_categorical_transformer, orde_categorical_features), ], remainder='passthrough', verbose=0, verbose_feature_names_out=False, n_jobs=-1,)pipeline = Pipeline(steps = [ ('tweak_bank_marketing', TweakBankMarketing()), ('col_trans', col_trans), ('imputer', KNNImputer(n_neighbors=5)), ('clf', ClfSwitcher()),])pipeline简而言之,上述代码的操作如下:
- 使用
StandardScaler和MinMaxScaler对数值列进行缩放。 - 使用
OneHotEncoder和OrdinalEncoder对分类列进行编码。 - 使用
ColumnTransformer单独对数据集的不同列进行转换。 - 最后,
Pipeline无缝地封装了所有内容。
在这个阶段,这是我们构建的管道。

5. 为网格搜索CV定义超参数
# 我们为4个分类器定义所有超参数,以便我们可以轻松地从一个分类器切换到另一个分类器params_grid = [ {'clf__estimator': [SGDClassifier()], 'clf__estimator__penalty': ('l2', 'elasticnet', 'l1'), 'clf__estimator__max_iter': [500], 'clf__estimator__tol': [1e-4], 'clf__estimator__loss': ['hinge', 'log_loss', 'modified_huber'], }, {'clf__estimator': [LogisticRegression()], 'clf__estimator__C': [0.01, 0.1, 1, 10, 100], 'clf__estimator__max_iter': [1000] }, {'clf__estimator': [RandomForestClassifier(n_estimators=100)], 'clf__estimator__max_features': [3,4,5,6,7], 'clf__estimator__max_depth': [3,4,5] }, {'clf__estimator': [XGBClassifier()], 'clf__estimator__max_depth': [4,5,6], 'clf__estimator__learning_rate': [0.01, 0.1], 'clf__estimator__n_estimators': [80, 100], 'clf__estimator__booster': ['gbtree'], 'clf__estimator__gamma': [7, 25, 100], 'clf__estimator__subsample': [0.3, 0.6], 'clf__estimator__colsample_bytree': [0.5, 0.7], 'clf__estimator__colsample_bylevel': [0.5, 0.7], 'clf__estimator__eval_metric': ['auc'] },]简而言之,上面的代码所做的是:
- 为4个不同的分类器定义参数网格,分别是
SGDClassifier,LogisticRegression,RandomForestClassifier,XGBClassifier。
6. 执行网格搜索CV
from sklearn.model_selection import GridSearchCV%%timegrid = GridSearchCV(pipeline, params_grid, cv=5, n_jobs=-1, return_train_score=False, verbose=0)grid.fit(X_train, y_train)简而言之,上面的代码所做的是:
- 将我们的管道对象作为
GridSearchCV参数的第一个参数
7. 打印最佳估计器
print(f'Best params: {grid.best_params_}')print(f'Best CV score: {grid.best_score_}')print(f'Validation-set score: {grid.score(X_test, y_test)}')print(f'Accuracy score: {accuracy_score(y_test, grid.predict(X_test))}')print(f'Precision score: {precision_score(y_test, grid.predict(X_test))}')print(f'Recall score: {recall_score(y_test, grid.predict(X_test))}')print(f'ROC-AUC score: {roc_auc_score(y_test, grid.predict(X_test))}')在这里,我们获得了0.74的验证分数,以及0.74的AUC分数。
8. 绘制ROC-AUC曲线
fpr, tpr, thresholds = skmet.roc_curve(y_test, grid.predict(X_test))roc_auc = skmet.auc(fpr, tpr)display = skmet.RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=roc_auc, estimator_name='XGBoost Classifier')display.plot();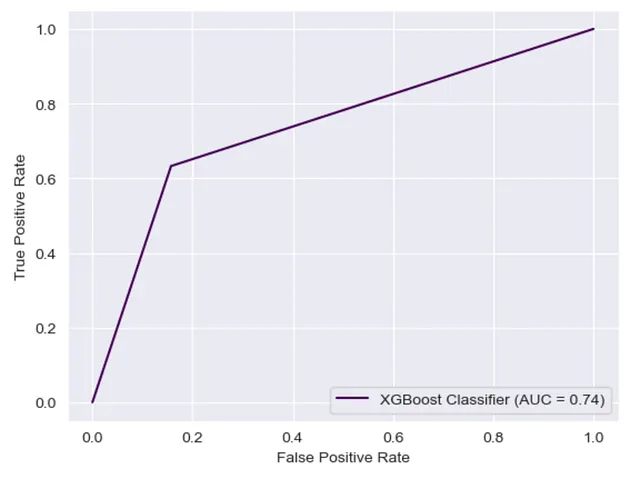
后记
就是这样! 管道与估计器和转换器。 下次您接触ML项目时,请考虑使用此技术。 虽然一开始可能难以采用,但请继续练习,很快您将创建强大而高效的机器学习管道。
如果您从本文中获得了有用的信息,请考虑在小猪AI上关注我。轻松、每周一篇文章,让您保持更新,跟上潮流!
与我联系!
- LinkedIn 👔
- Twitter 🖊
参考文献
- 银行营销数据集[Moro等人,2014]S. Moro、P. Cortez和P. Rita。使用数据驱动的方法预测银行电话营销的成功。决策支持系统,Elsevier,62:22-31,2014年6月:https://archive.ics.uci.edu/ml/datasets/Bank+Marketing(CCBY 4.0)
- Scikit-learn线性模型逻辑回归:https://github.com/scikit-learn/scikit-learn/blob/364c77e047ca08a95862becf40a04fe9d4cd2c98/sklearn/linear_model/_logistic.py
- Scikit-learn预处理:https://github.com/scikit-learn/scikit-learn/blob/364c77e04/sklearn/preprocessing/_data.py#L644
- 开发Scikit-learn估计器:https://scikit-learn.org/stable/developers/develop.html
- Scikit-learn ColumnTransformer:https://scikit-learn.org/stable/modules/generated/sklearn.compose.ColumnTransformer.html
- Scikit-learn Pipeline:https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html
- Scikit-learn FeatureUnion:https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.FeatureUnion.html