Learn more about Reinforcement Learning

加州大学伯克利分校的研究人员引入了一种名为RLIF的强化学习方法,它能够从与互动模仿学习相似的环境中的干预学习
加州大学伯克利分校的研究人员介绍了一种未经探索的学习控制问题的方法,将 强化学习 (RL) 与用户干预信号相结合。利用 DAgge...

颠覆性的数字艺术:首尔国立大学的研究人员引入了一种利用强化学习创作拼贴的新方法
艺术拼贴创作与人类艺术密切相关,引发了对人工智能(AI)的兴趣。挑战在于需要超越现有的像DALL-E和StableDiffusion这样的AI...

应用大型语言模型的前沿技巧
介绍 大型语言模型(LLMs)是人工智能不断发展的领域中的重要创新支柱。像GPT-3这样的模型展示了令人印象深刻的自然语言处理...

数据科学中的库存优化:使用Python的实践教程
库存优化就像解决一个棘手的谜题作为一个广泛的问题,它涉及多个领域,它的核心是弄清楚你的店铺需要订购多少产品想象一辆自...

通过自我对战训练一个智能体掌握一个简单游戏
不是很惊奇吗?在一个完美信息游戏中,你需要卓越的一切都可以在游戏规则中公开地看到不幸的是,对于像我这样的凡人来说,阅...
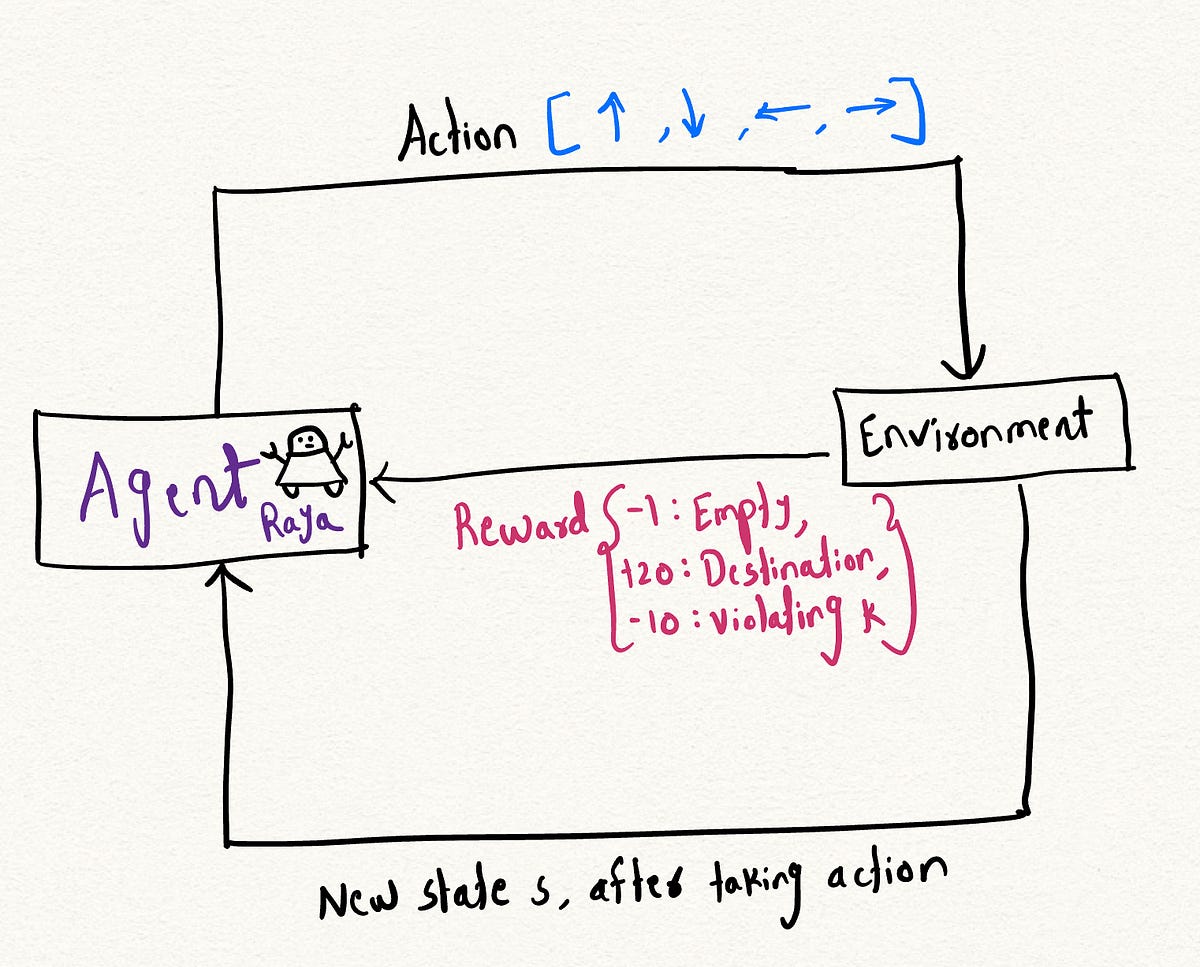
使用强化学习解决Leetcode问题
最近,我在LeetCode上遇到了一个问题:最短路径中消除障碍物的网格最短路径中消除障碍物的问题涉及找到最短路径...

DeepMind研究人员介绍了Reinforced Self-Training(ReST):一种简单的算法,通过Growing Batch Reinforcement Learning(RL)受到人类偏好的启发,用于将LLMs与人类偏好对齐
大型语言模型(LLMs)非常善于产生写作流畅的内容并解决各种语言问题。这些模型通过使用大量的文本和计算进行训练,以增加下...

“在随机行走任务上,Temporal-Difference(0)和Constant-α Monte Carlo方法的比较”
蒙特卡洛(MC)和时差(TD)方法都是强化学习领域中的基础技术,它们基于经验解决预测问题,来源于...

DeepMind研究人员推出AlphaStar Unplugged:通过掌握实时策略游戏StarCraft II,实现了大规模离线强化学习的重大突破
游戏长期以来一直是评估人工智能(AI)系统能力的重要测试场所。随着AI技术的发展,研究人员寻求更复杂的游戏来评估与现实世...

斯坦福研究人员在无直接监督的元强化学习代理中探索简单语言技能的出现:解析在定制多任务环境中的突破
斯坦福大学的一个研究团队在自然语言处理(NLP)领域取得了突破性的进展,通过研究增强学习(RL)代理是否可以在没有明确语言...

加州大学伯克利分校的研究人员引入了视频预测奖励(VIPER):一种利用预训练的视频预测模型作为无动作奖励信号的强化学习算法
通过手动设计奖励函数耗时且可能导致意想不到的后果。这是开发基于强化学习(RL)的通用决策制定代理的主要障碍。 先前的基于...

遇见MACTA:一种开源的多智能体强化学习方法,用于缓存定时攻击和检测
我们被各种形式的数据淹没。无论是来自金融部门、医疗保健部门、教育部门还是组织机构的数据,数据的隐私和安全都是每个组织...

大型语言模型(LLM)(如ChatGPT)为何在微调时使用强化学习而不是监督学习的5个原因
随着生成式人工智能在过去几个月取得的巨大成功,大型语言模型不断进步和改进。这些模型正在为一些值得注意的经济和社会转型...

加州大学伯克利分校的研究人员提出了FastRLAP:一种通过深度强化学习和自主练习来学习高速驾驶的系统
加利福尼亚大学伯克利分校的研究人员开发了一种名为FastrLap的系统,利用机器学习教导自动驾驶车辆以高速驾驶。该系统旨在帮...

OpenAI介绍超级对齐:为安全和对齐的人工智能铺平道路
OpenAI引入了超对齐开发,为人类带来了巨大的希望。由于其广泛的能力,它有能力解决我们地球面临的一些最紧迫的问题。超智能...

使用自动反馈的偏好学习进行缓存逐出
由谷歌软件工程师Ramki Gummadi和YouTube软件工程师Kevin Chen发布 缓存是计算机科学中的一个普遍概念,通过根据请求模式将一...
深度强化学习改进的排序算法
上周,谷歌DeepMind在《自然》杂志上发表了一篇论文,声称他们利用深度强化学习(DLR)找到了一种更有效的排序算法DeepMind以...
使用DeepMind的AlphaDev发现更快的排序算法
算法是现代技术的支柱,驱动着从数据分析到优化的一切。它们向计算机和软件提供了逐步指令,使得在各个领域中能够高效且一致...

Atari 100K基准测试中的超人表现:BBF的力量-来自Google DeepMind,Mila和蒙特利尔大学的新价值RL智能体
深度强化学习(RL)已成为解决复杂决策任务的强大机器学习算法。为了克服在深度RL训练中实现人类级别样本效率的挑战,Google ...

DeepMind 推出 AlphaDev:一种深度强化学习代理,可从头开始发现更快的排序算法
從人工智慧和數據分析到密碼學和優化,算法在每個領域都扮演重要角色。算法基本上是一組程序,有助於以逐步方式完成特定任務...

- You may be interested
- “在随机行走任务上,Temporal-Difference(...
- 大学为量子未来培养工程师
- “神经元、萤火虫和跳诺特布什舞有什么共同...
- 开发一款适用于公司的ChatGPT,三分之一是...
- 我是如何学会喜欢自主生成AI与自动完成的
- 微软因’极度不负责任’的安全...
- 中国的研究人员公布了ImageReward:一种突...
- TinyML:应用、限制及其在物联网和边缘设...
- (Our new ways of helping to reduce tran...
- Harrison.ai首席执行官Aengus Tran博士关...
- 谷歌失去控制——从点击率操纵到大规模AI内容
- 使用还是不使用机器学习
- 使用多个LoRA适配器组合Llama 2
- 世界首个AI动力臂:您需要知道的一切
- “视频分割可以更具成本效益吗?认识DEVA:...

