使用自动反馈的偏好学习进行缓存逐出
由谷歌软件工程师Ramki Gummadi和YouTube软件工程师Kevin Chen发布
缓存是计算机科学中的一个普遍概念,通过根据请求模式将一部分热门项存储在离客户端更近的位置,显著提高存储和检索系统的性能。缓存管理中的一个重要算法部分是用于动态更新正在存储的项集的决策策略,经过数十年的广泛优化,已经产生了几种高效且健壮的启发式算法。虽然近年来将机器学习应用于缓存策略已经取得了有希望的结果(例如,LRB,LHD,存储应用程序),但要在超越基准测试的生产环境中可靠地推广并保持竞争计算和内存开销方面的优势,仍然是一个挑战。
在《HALP:Heuristic Aided Learned Preference Eviction Policy for YouTube Content Delivery Network》中,我们在2023年的NSDI上介绍了一种基于学习奖励的可扩展先进缓存驱逐框架,该框架使用自动反馈的偏好学习。启发式辅助学习偏好(HALP)框架是一个元算法,它使用随机化将轻量级启发式基线驱逐规则与学习奖励模型合并。奖励模型是一个轻量级神经网络,通过模拟离线Oracle的偏好比较进行持续训练。我们讨论了HALP如何提高YouTube内容传输网络的基础设施效率和用户视频播放延迟。
用于缓存驱逐决策的学习偏好
HALP框架根据两个组件计算缓存驱逐决策:(1)一个通过偏好学习训练的神经奖励模型,(2)一个将学习奖励模型与快速启发式算法相结合的元算法。当缓存观察到传入请求时,HALP通过将其作为成对偏好反馈的偏好学习方法来持续训练一个小型神经网络,为每个项预测一个标量奖励。HALP的这个方面类似于人类反馈的强化学习(RLHF)系统,但有两个重要的区别:
- 反馈是自动化的,并利用了关于离线最佳缓存驱逐策略结构的众所周知的结果。
- 模型使用从自动化反馈过程中构建的训练样本的瞬态缓冲区进行连续学习。
驱逐决策依赖于具有两个步骤的过滤机制。首先,使用一个高效但性能不佳的启发式算法选择一小部分候选项。然后,通过仅使用神经网络评分函数的稀缺使用,通过重新排序步骤优化基线候选项的质量。
作为一个可投入生产的缓存策略实现,HALP不仅能够做出驱逐决策,还能够包括用于有效构建相关反馈并更新模型以支持驱逐决策的成对偏好查询的全流程。
神经奖励模型
HALP使用轻量级的两层多层感知器(MLP)作为其奖励模型,以有选择地对缓存中的单个项目进行评分。特征被构建和管理为一个仅包含元数据的“幽灵缓存”(类似于ARC等经典策略)。在任何给定的查找请求之后,除了常规的缓存操作之外,HALP还进行了簿记(例如,在受容量限制的键值存储中跟踪和更新特征元数据)以更新动态内部表示。这包括:(1)由用户提供的输入的外部标记特征,以及缓存查找请求,以及(2)从观察到的每个项上的查找时间构建的内部构造的动态特征(例如,自上次访问以来的时间,平均访问时间)。
HALP从随机的权重初始化开始完全在线学习其奖励模型。这可能看起来像一个坏主意,特别是如果决策仅用于优化奖励模型。然而,驱逐决策依赖于学习的奖励模型和一个次优但简单且健壮的启发式算法(例如LRU)。这样可以在奖励模型完全泛化时实现最佳性能,同时对于尚未泛化或正在适应变化环境的暂时无信息的奖励模型保持健壮。
在线训练的另一个优点是专业化。每个缓存服务器在可能不同的环境中运行(例如,地理位置),这会影响本地网络条件和本地热门内容等。在线训练自动捕获此信息,同时减轻了泛化的负担,与单个离线训练解决方案相比。
从随机优先队列中评分样本
仅通过学习目标来优化驱逐决策的质量可能是不切实际的,原因有两个。
- 计算效率约束:使用学习网络进行推理的成本可能比在实际缓存策略中进行的计算要高得多。这不仅限制了网络和特征的表达能力,还限制了每个驱逐决策中调用这些特征的频率。
- 对于泛化到分布外的鲁棒性:HALP部署在涉及持续学习的环境中,其中快速变化的工作负载可能会产生暂时与先前看到的数据不符的请求模式。
为了解决这些问题,HALP首先应用一种廉价的启发式评分规则,该规则对应于一种驱逐优先级,以识别出一个小的候选样本。此过程基于高效的随机抽样,以近似精确优先级队列。生成候选样本的优先级函数旨在使用现有的手动调整算法进行快速计算,例如LRU。然而,通过编辑简单的成本函数,可以配置为近似其他缓存替换启发式算法。与之前的工作不同,其中随机化被用来权衡近似和效率,HALP还依赖于随时间步长随机选择的样本候选人的固有随机化,以提供样本候选人在训练和推理中所需的探索性多样性。
最终驱逐的项是从提供的候选样本中选择的,相当于基于神经奖励模型最大化预测偏好分数的n个重新排序样本中的最佳样本。用于驱逐决策的候选样本池也用于构建成对的偏好查询以进行自动反馈,这有助于最小化样本之间的训练和推理偏差。
 |
| 每个驱逐决策中调用的两阶段过程概述。 |
在线偏好学习与自动反馈
通过在线反馈学习奖励模型,该模型基于自动分配的偏好标签,这些标签指示从给定时间快照开始,未来重新访问所需时间的排序偏好顺序,这类似于理想的最优策略,该策略在任何给定时间从缓存中驱逐与所有其他项相比具有未来访问最远的项。
 |
| 生成用于学习奖励模型的自动反馈。 |
为了使此反馈过程具有信息性,HALP构建了最有可能与驱逐决策相关的成对偏好查询。与通常的缓存操作同步,HALP在每次驱逐决策时发出少量成对偏好查询,并将它们附加到一组未决比较中。这些未决比较的标签只能在随机未来时间解决。为了在线操作,HALP还在每次查找请求后执行一些额外的记录,以处理当前请求后可以逐步标记的任何未决比较。HALP使用每个参与比较的元素索引未决比较缓冲区,并回收由于过时比较消耗的内存(其中任何一个可能永远不会重新访问),以确保随时间推移与反馈生成相关的内存开销保持有界。
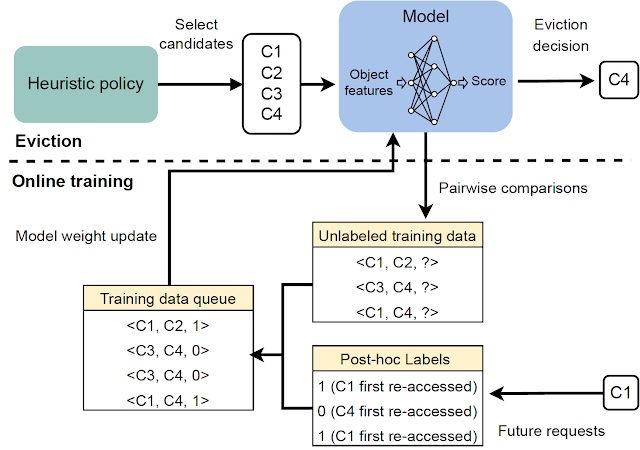 |
| HALP中所有主要组件的概述。 |
结果:对YouTube CDN的影响
通过经验分析,我们展示了HALP在公共基准跟踪中相对于最先进的缓存策略在缓存未命中率方面的有利对比。然而,尽管公共基准是一个有用的工具,但很少能够捕捉到世界各地历时的所有使用模式,更不用说我们已经部署的各种硬件配置了。
直到最近,YouTube服务器使用了一个优化的LRU变体进行内存缓存驱逐。由于缓存未命中,HALP将YouTube的内存出口/入口(CDN提供的总带宽出口与检索(入口)消耗的比例)提高了约12%,内存击中率提高了6%。这减少了用户的延迟,因为内存读取比磁盘读取更快,同时还通过屏蔽磁盘的流量提高了磁盘受限机器的出口容量。
下图展示了在YouTube CDN上最终推出HALP后的几天内字节未命中率的显著降低,该CDN现在从缓存中提供了更多的内容,以较低的延迟传递给最终用户,而无需采用增加运营成本的更昂贵的检索。
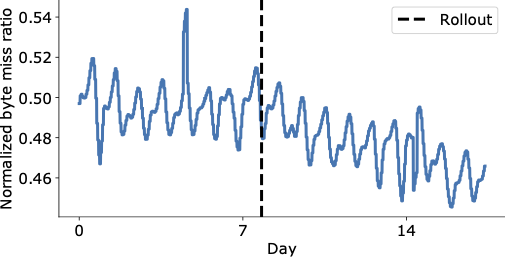 |
| 全球范围内YouTube推出之前和之后的字节未命中率(垂直虚线)。 |
聚合性能改进仍然可能掩盖重要的退步。除了测量总体影响外,我们还在论文中进行了分析,以了解其对不同机架的影响,并发现其影响非常积极。
结论
我们介绍了一种基于学习奖励的可扩展最先进的缓存驱逐框架,该框架使用自动反馈的偏好学习。由于其设计选择,HALP可以以类似于任何其他缓存策略的方式部署,而无需额外的操作开销,例如单独管理标记的示例、训练过程和模型版本,这是大多数机器学习系统常见的离线流程。因此,与其他经典算法相比,它只产生了很小的额外开销,但具有利用其他功能做出驱逐决策并持续适应不断变化的访问模式的附加优势。
这是第一个将学习缓存策略大规模部署到广泛使用且流量密集的CDN的案例,并显著提高了CDN基础设施的效率,同时为用户提供更好的体验质量。
致谢
Ramki Gummadi现已加入Google DeepMind。我们要感谢John Guilyard对插图的帮助和Richard Schooler对本文的反馈。






