“视频分割可以更具成本效益吗?认识DEVA:一种解耦的视频分割方法,可以节省注释并在不同任务之间泛化”
Can video segmentation be more cost-effective? Introducing DEVA a decoupled video segmentation method that saves annotations and generalizes between different tasks.


你是否曾经想过监控系统是如何工作的,以及我们如何仅通过视频来识别个人或车辆?或者如何通过水下纪录片来识别虎鲸?或者是实时体育分析?所有这些都是通过视频分割完成的。视频分割是根据某些特征(如物体边界、运动、颜色、纹理或其他视觉特征)将视频分成多个区域的过程。其基本思想是识别和分离视频中的不同对象以及背景和时间事件,从而提供更详细和结构化的视觉内容表示。
扩展视频分割算法的使用可能代价高昂,因为它需要标记大量数据。为了更容易地在视频中跟踪对象,而无需为每个特定任务训练算法,研究人员提出了一种解耦视频分割 DEVA。DEVA包含了两个主要部分:一个专门用于在各个帧中查找对象的部分,以及另一个部分,帮助连接时间上的点,无论对象是什么。这样,DEVA可以更灵活、更适应各种视频分割任务,而无需大量训练数据。
通过这种设计,我们可以使用一个更简单的图像级模型来处理我们感兴趣的特定任务(训练成本较低),以及一个只需训练一次且可用于各种任务的通用时间传播模型。为了使这两个模块有效地协同工作,研究人员使用了双向传播方法。这有助于以一种使最终分割结果看起来一致的方式合并不同帧的分割猜测,即使是在线或实时完成。
- 安全对话:在使用ChatGPT时保护隐私和数据 🛡️
- 使用人工智能改变3D模型定制:麻省理工学院研究人员开发了一种用户友好的界面,用于美学调整而不影响功能性
- 谷歌研究人员提出了一种新的人工智能方法,用于对场景动态建模的图像空间先验
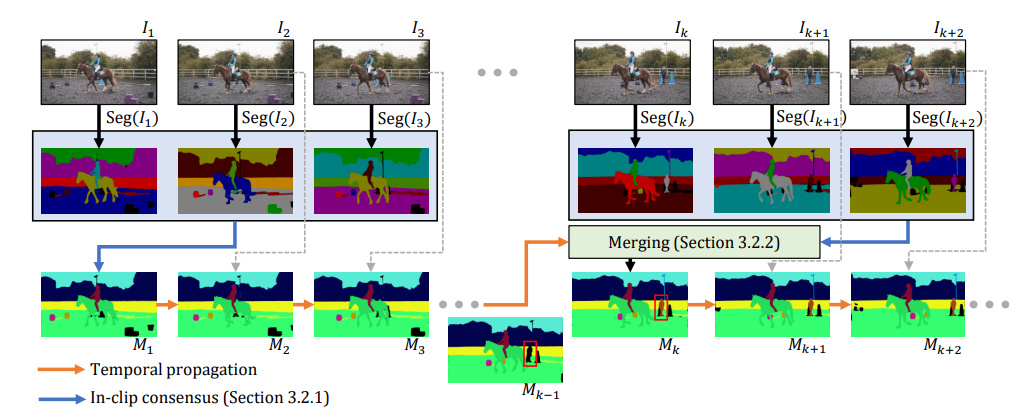
上面的图像为我们提供了框架的概述。研究团队首先使用片内一致性和时间传播对图像级分割进行筛选。为了在以后的时间步骤中合并新的图像分割(用于以前未见过的对象,例如红框),他们将传播的结果与片内一致性合并。
这项研究采用的方法大量使用了外部与任务无关的数据,旨在减少对特定目标任务的依赖。与端到端方法相比,它具有更好的泛化能力,特别是对于可用数据有限的任务而言。它甚至不需要进行精调。与通用图像分割模型配对使用时,这种解耦范式展示了尖端性能。它无疑代表了朝着在开放环境中实现最先进的大词汇视频分割的目标迈出的初步步伐!