深度强化学习改进的排序算法
如何谷歌 DeepMind 创造了一个更高效的排序算法
上周,谷歌 DeepMind 在《自然》杂志上发表了一篇论文,声称利用深度强化学习(DRL)找到了一种更高效的排序算法。DeepMind 以推动强化学习(RL)的边界而闻名。几年前,他们使用类似的程序击败了围棋比赛中的最佳选手,在此之后又用类似的程序压制了现有的国际象棋引擎。2022 年,DeepMind 推出了 AlphaTensor,这是一个使用 DLR 找到了更高效的矩阵乘法算法的程序。所使用的技术类似于 DeepMind 最新的成就:改进标准排序算法。在本文中,我将讨论他们如何通过引入强化学习、蒙特卡罗树搜索以及 DeepMind 的方法和代理 AlphaDev 来实现这一点。
排序
编写排序算法很简单:逐一比较所有值,找到最低(或最高)值,将此值保存在返回列表的第一个元素中,然后继续下一个值,直到没有更多的值为止。虽然这个算法可以工作,但远非高效。因为在计算机程序中排序非常常见,所以高效的排序算法受到大量研究。DeepMind 关注了两种排序变体:固定排序和变量排序。固定排序涉及使用具有固定预定义长度的值序列进行排序。在变量排序中,值列表的大小事先未定义。仅提供列表的最大大小。这两种排序变体都广泛用于最先进的排序算法中。通常,通过反复排序列表的小部分来排序大列表。
当前最先进的算法在固定排序和变量排序中都使用所谓的排序网络。在本文中,我不会讨论排序网络的细节。您可以在此处找到更多信息。
强化学习
在本节中,我将介绍强化学习的主要概念。强化学习是机器学习的一个分支,其中代理被赋予在给定当前状态的情况下在环境中找到最佳动作的任务。环境的状态包含可以或应该影响所采取行动的环境的所有相关方面。最佳动作被定义为最大化(折扣)累积奖励的动作。动作是按顺序执行的,每个动作之后,记录获得的奖励和新状态。通常,在环境有一些终止标准之后,下一集开始。早期的 RL 使用表格来跟踪某些状态和动作的价值,以始终采取具有最高价值的动作。深度神经网络经常取代这些表格,因为它们可以更好地概括,并且枚举所有状态通常是不可能的。当深度神经网络用于强化学习时,使用术语深度强化学习。
- 3D计算机建模生成图坦卡蒙的面部近似模型
- 技术旨在预防老年人摔倒
- 阿里巴巴集团和蚂蚁集团的研究人员推出了VideoComposer:一种AI模型,它可以将多种模式(如文本、草图、风格甚至运动)组合起来驱动视频生成
蒙特卡罗树搜索
AlphaDev 是使用深度强化学习和蒙特卡罗树搜索训练的,后者是一种搜索算法,用于在给定某个初始状态的情况下找到最佳动作。它通常与 DRL 结合使用,例如在 AlphaZero 和 AlphaGo 中。它值得拥有自己的文章,但这里提供了一个摘要。
蒙特卡罗树搜索(MCTS)构建了一个可能的结果状态的树,其中当前状态是根节点。对于给定数量的模拟,将探索该树以查找采取某些动作的后果。在每个模拟中,使用一个回滚(有时称为播放)来将一个节点扩展为子节点,如果在该点上未终止游戏。选择要采取的操作基于选择标准。在我们的情况下,选择动作的概率由策略网络给出,这将在下面讨论。节点的值是衡量该节点状态有多好的一种方法。它由价值网络确定,这也将在未来的部分中讨论。如果达到终止状态,则将值替换为环境的真实奖励值。
数值沿着搜索树传播。通过这种方式,当前状态的值取决于可以从当前状态到达的状态的值。
DeepMind 的方法
DeepMind训练的DRL智能体名为AlphaDev,其任务是在汇编语言中编写更高效的排序算法。汇编语言是高级语言(如C++,Java和Python)与机器码之间的桥梁。如果您在C++中使用sort,则编译器会将您的程序编译成汇编代码。然后汇编器将此代码转换为机器代码。AlphaDev的任务是选择一系列汇编指令,创建既正确又快速的排序算法。这是一项困难的任务,因为添加一个指令可能会使程序完全错误,即使它以前是正确的。
AlphaDev通过创建和解决AssemblyGame来找到高效的排序算法。在每个回合中,它必须选择一个与CPU指令相对应的操作。通过将此问题制定为游戏,它可以轻松适应标准的强化学习框架。
强化学习模型
标准的RL模型包含状态,动作,奖励和终止条件。
状态
AssemblyGame的状态由两部分组成。首先是当前程序的表示。AlphaDev使用Transformer的输出来表示当前算法,这是一种神经网络架构。最近,Transformers在大型语言模型方面取得了很大的成功,并且是编码当前算法的合适选择,因为它是基于文本的。状态的第二部分是运行当前算法后内存和寄存器状态的表示。这是通过传统的深度神经网络完成的。
动作
AssemblyGame的动作是将合法的汇编指令附加到程序中。只要合法,AlphaDev可以选择附加任何指令。DeepMind为合法操作制定了以下六个规则:
- 内存位置总是按增量顺序读取
- 按增量顺序分配寄存器
- 每个内存位置只读写一次
- 不连续比较指令
- 没有内存比较或条件移动
- 不能使用未初始化的寄存器
最后两个操作在编程角度上是非法的,其他操作是强制执行的,因为它们不会改变程序。通过删除这些操作,可以限制搜索空间而不影响算法。
奖励
AssemblyGame的奖励由两部分组成。奖励的第一个元素是正确性得分。基于一系列测试序列,评估所提供的算法。算法越接近正确排序测试序列,正确性得分越高。奖励的第二个元素是程序的速度或延迟。如果没有条件分支,则通过程序的行数来衡量。在实践中,这意味着对于固定的排序,程序的长度用于计算,因为该程序不需要条件。对于可变的排序,算法必须根据实际序列长度进行条件判断。由于在排序时没有使用算法的所有部分,因此测量程序的实际延迟而不是行数。
终止和目标
根据DeepMind发布的论文,他们在“有限的步骤”后中止AssemblyGame。这是什么意思不清楚,但我认为他们基于当前的人类基准限制步数。游戏的目标是找到一个正确且快速的算法。如果AlphaDev提供了不正确或慢的算法,则游戏失败。
策略和价值网络
要使用蒙特卡罗树搜索,需要策略和价值网络。策略网络设置每个动作的概率,价值网络被训练用于评估状态。策略网络根据某个状态的访问次数进行更新。这创建了一个迭代过程,其中政策用于执行MCTS,并且策略网络基于MCTS中状态的访问次数进行更新。
价值网络输出两个值,一个用于算法的正确性,一个用于算法的延迟。根据DeepMind的说法,这比通过网络将这些值组合为一个分数产生更好的结果。价值网络基于获得的奖励进行更新。
结果
在训练AlphaDev后,它发现了长度为3和5的固定排序的更短算法。对于长度为4的固定排序,它找到了当前的实现,因此没有进行改进。通过应用两个新的想法(称为swap和copy move),AlphaDev为固定排序实现了这些结果,从而减少了值之间的比较,从而实现了更快的算法。对于长度为3的固定排序,DeepMind通过强制措施证明不存在更短的程序。对于更长的程序,这种方法是不可行的,因为搜索空间呈指数增长。
对于变量排序,AlphaDev提出了一种新的算法设计。例如,对于长度最多为4的序列进行变量排序,AlphaDev建议首先对3个值进行排序,然后对剩余的最后一个元素执行简化版本的排序。下图显示了由AlphaDev提供的Varsort(4)算法设计。
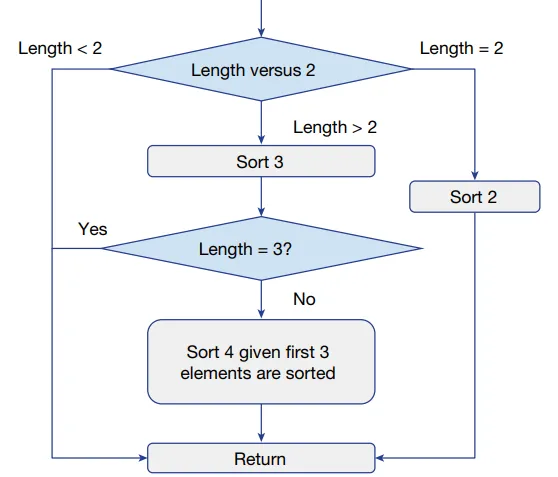
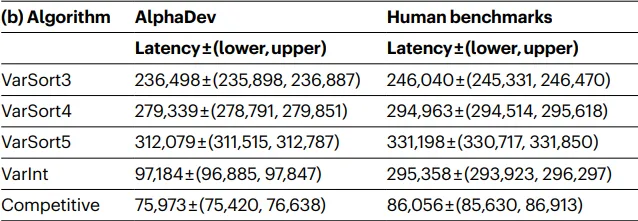
总的来说,已经为固定排序和变量排序找到了更快的算法,证明了DRL可以用来实现高效的算法。C++中的排序实现已更新为使用这些新算法。AlphaDev实现的性能提升细节可以在下表中找到。
为了测试这种方法是否适用于其他编程实现,DeepMind还在谷歌使用的竞争性编码挑战和协议缓冲区上测试了AlphaDev。在两种情况下,AlphaDev都能够提出更有效的实现,证明了DLR与蒙特卡罗树搜索是一种寻找通用算法高效实现的有效方法。
结论
深度强化学习已经在许多不同的环境中取得成功,从围棋和国际象棋等游戏到算法实现,如本文所示。尽管该领域具有挑战性,通常取决于低级别实现细节和超参数选择,但这些成功显示了这个强大概念可以实现的结果。
我希望本文让您了解了RL领域的最新成果。如果您想要更详细的蒙特卡罗树搜索或其他算法的解释,请告诉我!
来源
[1] K. Batcher,排序网络及其应用(1968),4月30日至5月2日的会议记录,1968年春季联合计算机会议(第307-314页)
[2] D. Mankowitz等人,使用深度强化学习发现更快的排序算法(2023),自然618.7964:257-263
[3] D. Silver等人,通过自我对弈使用通用强化学习算法掌握国际象棋和将棋(2017年),arXiv预印本arXiv:1712.01815
[4] D. Silver等人,使用深度神经网络和树搜索掌握围棋(2016年),自然529.7587:484-489
[5] A. Fawzi等人,使用强化学习发现更快的矩阵乘法算法(2022年),自然610.7930:47-53
[6] C. Browne等人,蒙特卡罗树搜索方法概述(2012),IEEE计算智能和游戏人工智能交易4.1:1-43。






