说一次就好了!重复的话不会帮助人工智能
| 人工智能 | 自然语言处理 | 大型语言模型(LLMs)
重复标记如何损害LLMs?这是一个问题吗?
大型语言模型(LLMs)已经展现出其能力并席卷了世界。每个大公司现在都有一个带有花哨名称的模型。但是,在引擎盖下,它们都是变形金刚。 每个人都梦想着拥有万亿参数,但没有限制吗?
在本文中,我们将讨论:
- 更大的模型是否保证具有比小型模型更好的性能?
- 我们是否拥有巨大模型的数据?
- 如果不是收集新数据而是再次使用数据会发生什么?
翱翔天空:什么伤害了机翼?
OpenAI已经定义了缩放定律,其规定模型的性能遵循幂律,根据使用的参数数量和数据点的数量。这与寻求新兴特性一起创造了参数竞赛:模型越大,越好。
这是真的吗?更大的模型是否提供更好的性能?
最近,新兴特性陷入了危机。正如斯坦福大学研究人员所示,新兴特性的概念可能不存在。
AI中的新兴能力:我们在追逐一个神话吗?
改变对大型语言模型新兴特性的看法
towardsdatascience.com
缩放定律可能会给数据集分配比实际想象中更少的价值。DeepMind通过Chinchilla表明,不仅应该考虑缩放参数,还应该考虑数据。事实上,Chinchilla表明,它的容量比Gopher(70 B vs. 280 B参数)更优秀。
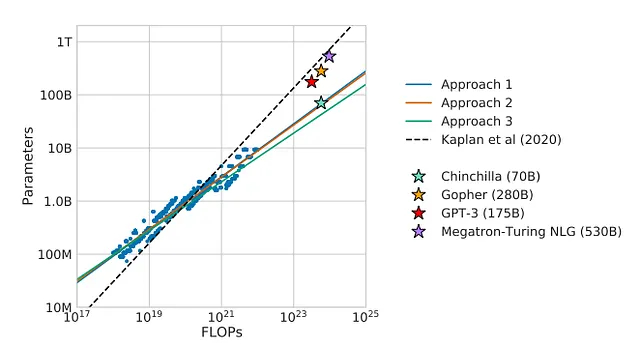
最近,机器学习社区对LLaMA感到兴奋,不仅因为它是开源的,而且因为参数为65 B的版本优于OPT 175 B。
META的LLaMA:小型语言模型击败巨人
META开源模型将帮助我们了解LMS偏见的产生
小猪AI.com
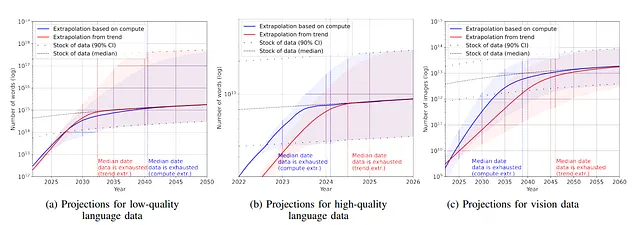
正如DeepMind在Chinchilla文章中所述,可以估计完全训练最先进的LLM所需的标记数量。另一方面,还可以估计存在多少高质量的标记。最近的研究对此进行了探讨。他们得出结论:
- 语言数据集呈指数增长,语言数据集发表量每年增长50%(到2022年底为2e12个单词)。这显示了新语言数据集的研究和发表是一个非常活跃的领域。
- 另一方面,互联网上的单词数量(单词库存)正在增长(作者估计在7e13和7e16个单词之间,因此是1.5-4.5个数量级)。
- 然而,由于他们试图使用高质量的单词库存,实际上作者估计质量库存在n 4.6e12和1.7e13个单词之间。 作者表示,在2023-2027年之间,我们将用尽高质量的单词数量,在2030年至2050年之间将用尽整个单词库存。
- 图像库存情况也不太理想(三到四个数量级)
为什么会发生这种情况?
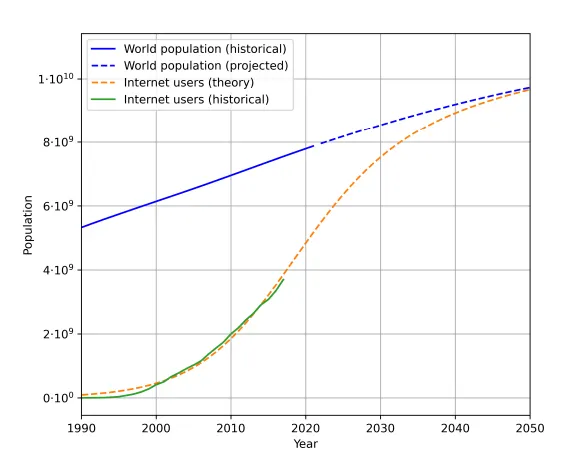
因为我们人类是有限的,无法像 ChatGPT 一样产生大量的文本。实际上,互联网用户数量(实际和预测)的预测趋势已经说明了很多问题:
实际上,并不是每个人都喜欢将文本、代码和其他资源用于训练人工智能模型。事实上,维基百科、Reddit 和其他历史上用于训练模型的资源希望公司付费使用他们的数据。相比之下,公司正在引用公平使用原则,而目前的监管情况仍不清楚。
将这些数据结合起来,可以清楚地看到一个趋势。为了最佳地训练 LLM,所需的 token 数量增长得比库存中的 token 快。
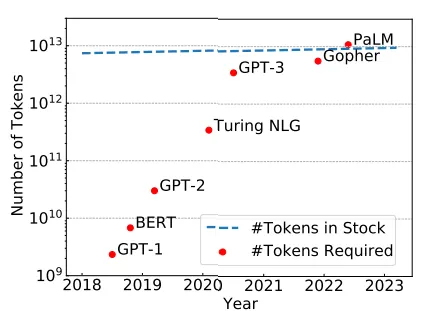
根据 Chinchilla 定义的缩放定律(最佳 LLM 训练所需的 token 数量),我们已经超过了极限。从图表中可以看出,根据这些估计,使用 PaLM-540 B,我们已经达到了极限(所需的 token 数量为 10800 万,而库存中只有 900 万)。
一些作者称这个问题为“token 危机”。此外,到目前为止,我们只考虑了英语 token,而还有七千种其他语言。整个网络的 56% 是英语,其余 44% 属于只有 100 种其他语言。这反映在其他语言模型的性能上。
我们能获取更多数据吗?
正如我们所看到的,参数越多并不意味着性能更好。为了获得更好的性能,我们需要优质的 token(文本),但这些 token 短缺。我们如何获得它们?我们能用人工智能帮助自己吗?
为什么我们不使用 Chat-GPT 生成文本呢?
如果我们人类无法产生足够的文本,为什么不自动化这个过程呢?最近的一项研究表明,这个过程并不是最优的。斯坦福 Alpaca 使用从 GPT-3 派生的 52,000 个例子进行了训练,但似乎只达到了类似的性能。但实际上,该模型只学习了目标模型的风格,而没有学习其知识。
为什么不加长训练时间呢?
对于 PaLM、Gopher 和 LLaMA(以及其他 LLM),都明确写明这些模型只进行了几个 epoch 的训练(一个或少数)。这不是 Transformer 的限制,因为例如 Vision Transformers(ViT)已经在 ImageNet(100 万张图像)上进行了 300 个 epoch 的训练,如表格所示:
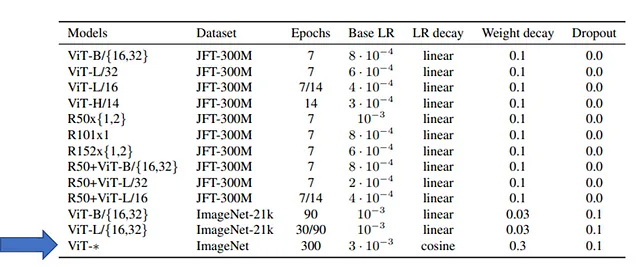
因为这是超级昂贵的。在 LLaMA 文章中,作者仅进行了一个 epoch 的训练(并且对部分数据集仅进行了两个 epoch 的训练)。尽管如此,作者报告:
当训练一个 65B 参数的模型时,我们的代码在 2048 个 A100 GPU 上每秒处理约 380 个 token/sec/GPU,每个 GPU 配备 80GB 的 RAM。这意味着在我们包含 1.4T token 的数据集上训练需要约 21 天。(来源)
即使只是训练一个LLM几个epochs,也是非常昂贵的。据Dmytro Nikolaiev(Dimid)计算,如果在Google Cloud Platform上训练类似于META的LLaMA模型,这意味着需要花费400万美元。
因此,训练其他epochs会导致成本呈指数增长。 另外,我们不知道这种额外的训练是否真的有用:我们还没有测试过。
最近,新加坡大学的一组研究人员研究了如果我们为LLM多个epochs进行训练会发生什么:
重复还是不重复:在令牌危机下扩展LLM的见解
最近的研究强调了数据集大小在扩展语言模型方面的重要性。然而,大型语言…
arxiv.org
Repetita iuvant aut continuata secant
到目前为止,我们知道模型的性能不仅取决于参数的数量,还取决于用于训练的高质量令牌的数量。另一方面,这些高质量令牌并不是无限的,我们正在接近极限。 如果我们找不到足够的高质量令牌,并且使用人工智能生成是一种选择,我们该怎么办?
我们可以使用相同的训练集进行更长时间的训练吗?
有一句拉丁格言说重复的东西有益(repetita iuvant),但随着时间的推移,有人添加了“但持续的重复会变得枯燥无味”(continuata secant)。
对于神经网络也是如此:增加epochs的数量可以改善网络性能(降低损失);然而,在某个时刻,尽管训练集中的损失继续下降,验证集中的损失开始上升。神经网络进入了过度拟合状态,开始考虑只存在于训练集中的模式,并且失去了泛化的能力。
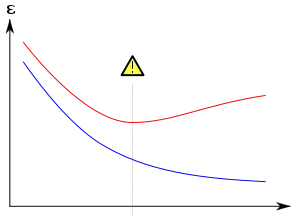
好的,这在小型神经网络上已经被广泛研究了,但是对于大型Transformer呢?
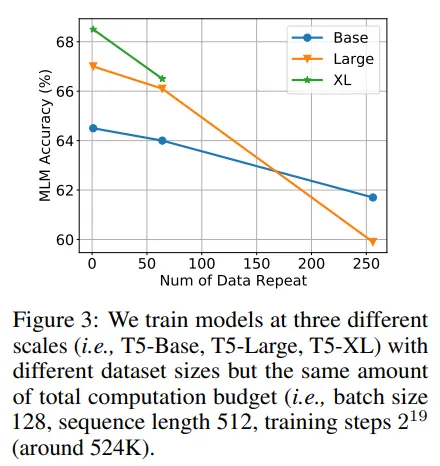
本研究的作者使用了T5模型(编码器-解码器模型)在C4数据集上进行了训练。作者训练了几个版本的模型,增加了参数数量,直到更大的模型表现优于较小的模型(表明更大的模型接收了足够数量的令牌,如Chinchilla定律所示)。作者指出,所需令牌数量与模型大小之间存在线性关系(证实了DeepMind在Chinchilla方面的观察)。
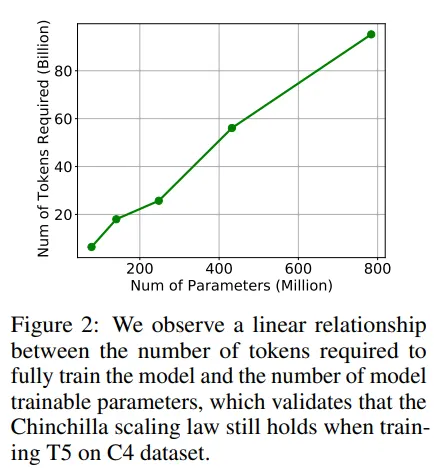
C4数据集是有限的(不具有无限令牌),因此为了增加参数数量,作者们发现自己处于令牌稀缺状态。因此,他们决定模拟LLM看到重复数据时会发生什么。他们采样了一定数量的令牌,因此模型发现自己在令牌训练中再次看到它们。这表明:
- 重复的令牌会导致性能下降。
- 较大的模型在令牌危机条件下更容易过拟合(因此即使理论上消耗更多的计算资源,这也会导致性能下降)。
此外,这些模型也用于下游任务。通常情况下,LLM在大规模文本上进行无监督训练,然后在小规模数据集上进行微调以用于下游任务。或者它可能会经历一种称为对齐的过程(如ChatGPT的情况)。
即使LLM在另一个数据集上进行了微调,如果它是在重复的数据上进行训练,其性能也会下降。因此,下游任务也会受到影响。
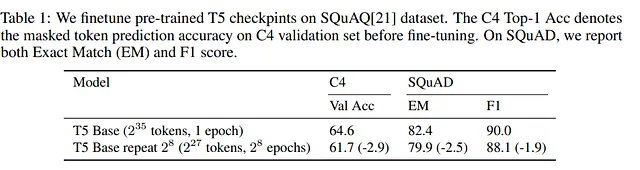
重复标记为什么不是一个好主意
我们刚刚看到,重复标记会损害训练。但为什么会这样?
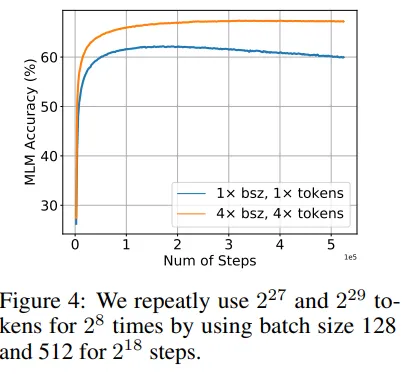
作者决定通过保持重复标记数不变并增加数据集中的总标记数来进行调查。结果表明,更大的数据集可以缓解多次纪元降级问题。
去年发表了Galactica(一个旨在帮助科学家但只持续了三天的模型)。除了惊人的失败,该文章还建议部分结果来自数据的质量。根据作者的说法,数据质量降低了过度拟合的风险:
我们能够在其中进行多次纪元的训练,而不会过度拟合,上下游性能随着重复标记的使用而改善。(来源)
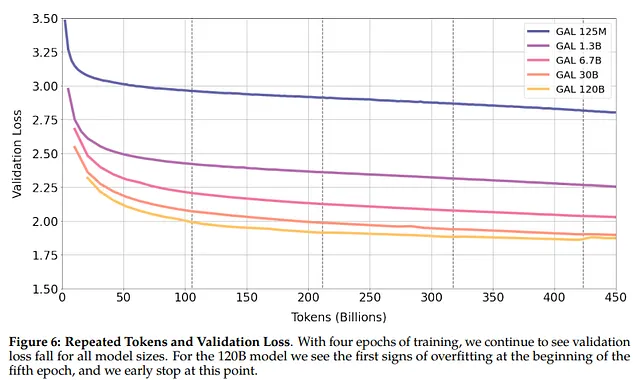
对于作者来说,重复标记实际上不仅不会损害模型训练,而且还可以改善下游性能。
在这项新研究中,作者使用维基百科数据集,该数据集被认为比C4更高质量,并添加了重复标记。结果显示有相似的降级水平,这与Galactica的文章所述相反。

作者还尝试调查这是否也是由于模型扩展引起的。在模型扩展期间,参数数量和计算成本都会增加。作者决定分别研究这两个因素:
- Mixture-of-Experts (MoE),因为尽管它增加了参数数量,但保持了类似的计算成本。
- ParamShare,另一方面,减少了参数数量,但保持了相同的计算成本。
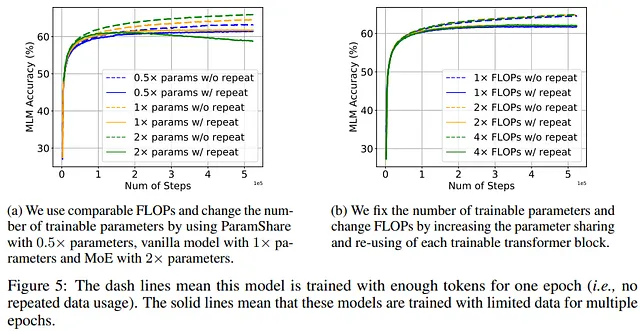
结果表明,参数较少的模型不受重复标记的影响较小。相反,MoE模型(参数数量更多)更容易出现过拟合。这个结果很有趣,因为MoE已经在许多人工智能模型中成功使用,因此作者建议,尽管在有足够数据的情况下MoE是一种有用的技术,但在标记不足时会损害性能。
作者还探讨了客观训练是否影响性能降级。一般来说,有两个训练目标:
- 下一个标记预测(给定一系列标记,预测序列中的下一个标记)。
- 掩码语言建模,其中一个或多个标记被屏蔽需要预测。
最近,谷歌引入了 UL2,这是 PaLM2-2 和 UL 的混合训练目标。 UL2 已被证明可以加速模型训练,但有趣的是,UL2 更容易过拟合,并具有更大的多轮降解。
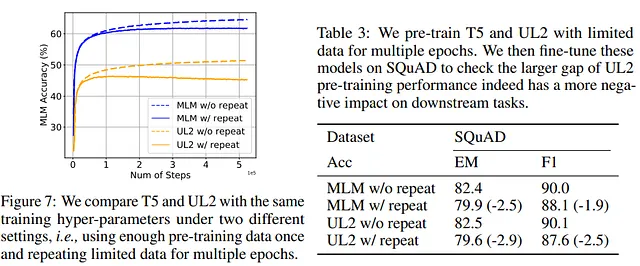
接下来,作者探索了如何尝试减轻多轮降解。由于正则化技术正是用于防止过拟合的,作者测试了这些技术是否在这里也有益。
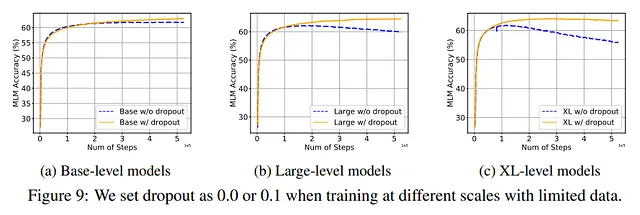
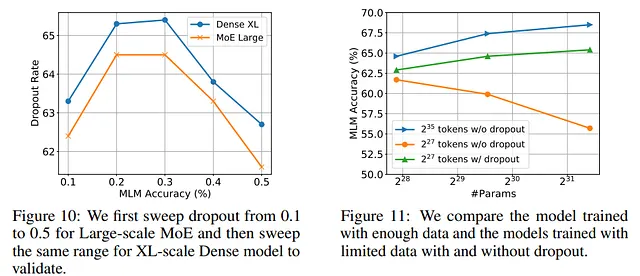
丢失法被证明是最有效的缓解问题的技术之一。这并不奇怪,因为这是最有效的正则化技术之一,易于并行化,并被大多数模型使用。

此外,对于作者来说,最好是先不使用丢失法,只有在训练的后期才添加丢失法。

另一方面,作者指出,在某些模型中使用 Dropout,特别是较大的模型,可能会导致性能略微降低。因此,尽管它可能对抗过拟合有益,但它可能会在其他情况下导致意外的行为。如 GPT-3、PaLM、LLaMA、Chinchilla 和 Gopher 模型都没有在它们的架构中使用它。
如下表所述,作者在他们的实验中使用了现在被认为是几乎小的模型。因此,在设计 LLM 时测试不同的超参数是昂贵的:
例如,在我们特定的情况下,训练 T5-XL 五次需要约 37,000 美元来租用 Google Cloud TPUs。考虑到更大的模型如 PaLM 和 GPT-4,以及训练在更大的数据集上,这个成本变得难以管理(来源)
由于在他们的实验中,稀疏 MoE 模型近似于密集模型的行为(这更加计算昂贵),因此可以使用它来搜索最佳超参数。
例如,作者展示了可以测试 MoE 模型的不同学习率,并且它表现出与等效密集模型相同的性能。因此,对于作者来说,可以使用 MoE 模型测试不同的超参数,然后使用选择的参数训练密集模型,从而节省成本:
扫描 MoE 大模型产生了约 10.6K 美元的开支,而训练 Dense XL 模型仅需要一次 7.4K 美元。因此,整个开发过程,包括扫描,总成本为 18K 美元,仅相当于直接调整 Dense XL 模型的费用的 0.48 倍(来源)
结束语
近年来,人们一直在争夺最大的模型。一方面,这场竞赛的动机是因为在一定规模下,会出现不可能用更小的模型预测的性质。另一方面,OpenAI 的缩放定律表明,性能是模型参数数量的函数。
在过去的一年中,这种模式已经陷入危机。
最近,LlaMA已经显示了数据质量的重要性。此外,Chinchilla展示了一个新的规则,用于计算训练模型所需的标记数量。实际上,某个参数数量的模型需要一定数量的数据才能表现最佳。
随后的研究表明,高质量标记的数量并不是无限的。另一方面,模型参数的数量增长速度远远超过我们人类能够生成的标记数量。
这就引发了如何解决标记危机的问题。最近的研究表明,使用LLM来生成标记并不是一种可行的方法。这项新工作展示了如何使用相同的标记进行多个时期的训练实际上会降低性能。
这样的工作很重要,因为虽然我们越来越多地训练和使用LLM,但仍有许多基本方面我们不了解。这项工作通过实验数据回答了一个看似基本的问题:当训练LLM多个时期时会发生什么?
此外,本文是越来越多的文献的一部分,它显示了增加参数数量是不必要的。另一方面,越来越大的模型越来越昂贵,也消耗越来越多的电力。考虑到我们需要优化资源,本文建议,在没有足够数据的情况下训练庞大的模型只是一种浪费。
本文还显示了我们需要新的体系结构来取代变压器。因此,现在是集中研究新思路而不是继续扩大模型的时间了。
如果您觉得这很有趣:
您可以查看我的其他文章,您还可以订阅以在我发布文章时收到通知,您还可以成为一个小猪AI会员,以访问所有其故事(平台的会员链接,我可以在没有成本的情况下获得小额收入)或者您也可以通过LinkedIn 联系或联系我。
这里是我的GitHub存储库链接,我计划收集与机器学习、人工智能等相关的代码和许多资源。
GitHub – SalvatoreRa/tutorial: 机器学习、人工智能、数据科学的教程…
机器学习、人工智能、数据科学的教程,带有数学解释和可重复使用的代码(使用Python…
github.com
或者您可能会对我最近的一些文章感兴趣:
扩展并不是一切:更大的模型失败得更厉害
大语言模型真的理解编程语言吗?
salvatore-raieli.medium.com
META’S LIMA:Maria Kondo训练LLMs的方式
少而整洁的数据创建一个能够与ChatGPT匹敌的模型
levelup.gitconnected.com
Google Med-PaLM 2:AI是否准备好进入医学住院医师培训?
谷歌的新模型在医学领域取得了令人印象深刻的成果
levelup.gitconnected.com
AI还是不AI:如何生存?
随着生成AI威胁到企业和兼职工作,您如何找到空间?
levelup.gitconnected.com
参考资料
本文所参考的主要资料列表如下:
- Fuzhao Xue等,2023,是否重复:在标记危机下扩展LLM的见解,链接
- Hugo Touvron等,2023,LLaMA:开放和高效的基础语言模型。链接
- Arnav Gudibande等,2023,模仿专有LLM的虚假承诺。链接
- PaLM 2,谷歌博客,链接
- Pathways语言模型(PaLM):为突破性能而扩展到5400亿个参数。谷歌博客,链接
- Buck Shlegeris等,2022,语言模型在下一个标记预测方面比人类更好,链接
- Pablo Villalobos等。所有,2022,我们会用完数据吗?机器学习中规模数据集的极限分析。链接
- Susan Zhang等。所有,2022,OPT:开放的预训练变压器语言模型。链接
- Jordan Hoffmann等,2022,计算最优大语言模型训练的实证分析。链接
- Ross Taylor等,2022,Galactica:面向科学的大语言模型,链接
- Zixiang Chen等,2022,走向理解深度学习中的专家混合模型,链接
- Jared Kaplan等,2020,神经语言模型的扩展定律,链接
- 人工智能如何助长全球变暖,TDS,链接
- 掩蔽语言建模,HuggingFace博客,链接
- 带有专家选择路由的专家混合模型,谷歌博客,链接
- 为什么Meta的最新大语言模型仅在网上存活了三天,MIT评论,链接
- 使用T5探索转移学习:文本到文本转换变压器,谷歌博客,链接
- 奖励模型过度优化的扩展定律,OpenAI博客,链接
- 计算最优大语言模型训练的实证分析,DeepMind博客,链接
- Xiaonan Nie等,2022,EvoMoE:通过密集到稀疏的门进行进化的专家混合培训框架。链接
- Tianyu Chen等,2022,面向任务的专家修剪稀疏的专家混合模型,链接
- Bo Li等,2022,稀疏的专家混合模型是具有通用域学习能力的学习器,链接