无监督学习系列:探索层次聚类
让我们探索一下层次聚类是如何工作的,以及它如何基于成对距离构建聚类。
在我上一篇关于无监督学习系列的文章中,我们探讨了最著名的聚类方法之一,即K均值聚类。在本文中,我们将讨论另一种重要聚类技术背后的方法——层次聚类!
这种方法也基于距离(欧几里得距离、曼哈顿距离等),并使用数据的层次表示来组合数据点。与K均值聚类相反,它不包含任何数据科学家可以配置的关于聚类中心数量(如k)的超参数。
大多数情况下,层次聚类可以分为两组:聚合聚类和分裂聚类。在前者中,数据点被视为单个单位,并根据距离聚合到附近的数据点。在后者中,我们将所有数据点视为单个聚类,并开始根据某些标准对它们进行分割。由于聚合版本是最著名和广泛使用的(sklearn的内置实现遵循此协议),因此我们将在本文中探讨这种层次类型。
在本博客文章中,我们将分两步来介绍聚合层次聚类:
- 首先,我们将使用平均方法(我们可以使用之一的方法来构建数据点的层次结构)使用聚合聚类逐步分析层次结构的构建过程。
- 然后,我们将看一些实际数据集上如何拟合层次聚类的示例,使用sklearn的实现。这也是我们将详细介绍其他方法来构建我们的层次结构(ward、minimum等)的地方。
让我们开始吧!
聚合层次聚类示例——一步一步
在我们的逐步示例中,我们将使用一个虚构的数据集,其中包含5个客户:
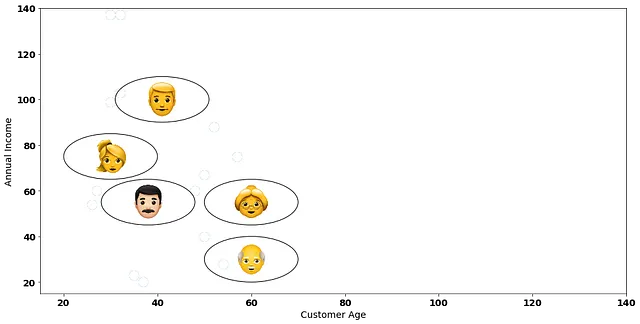
假设我们经营一个有5个客户的商店,并希望根据客户的相似之处将这些客户分组。我们有两个要考虑的变量:客户的年龄和他们的年收入。
我们聚合层次聚类的第一步是创建所有数据点之间的成对距离。让我们通过以[x,y]格式表示每个数据点来做到这一点:
- [60, 30]和[60, 55]之间的距离:25.0
- [60, 30]和[30, 75]之间的距离:54.08
- [60, 30]和[41, 100]之间的距离:72.53
- [60, 30]和[38, 55]之间的距离:33.30
- [60, 55]和[30, 75]之间的距离:36.06
- [60, 55]和[41, 100]之间的距离:48.85
- [60, 55]和[38, 55]之间的距离:22.0
- [30, 75]和[41, 100]之间的距离:27.31
- [30, 75]和[38, 55]之间的距离:21.54
- [41, 100]和[38, 55]之间的距离:45.10
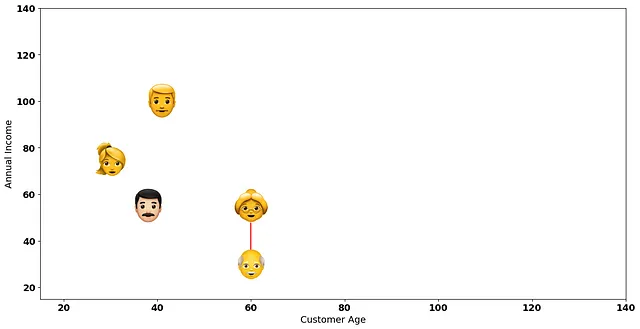
虽然我们可以使用任何类型的距离度量,但由于其简单性,我们将使用欧几里得距离。从我们计算的成对距离中,哪一个距离最小?
年收入低于90k美元的中年客户之间的距离——坐标为[30, 75]和[38, 55]的客户!
回顾欧几里得距离公式:

让我们通过连接更近的两个客户在2D图上可视化最小距离:
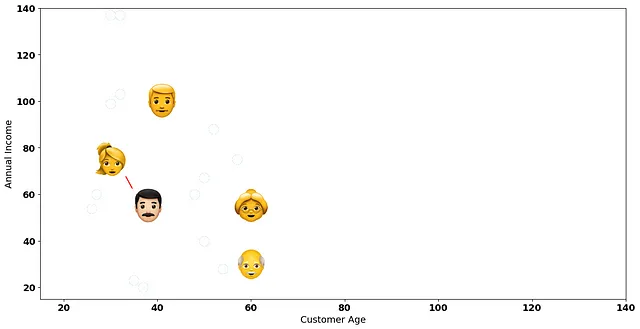
层次聚类的下一步是将这两个客户看作我们的第一个簇!
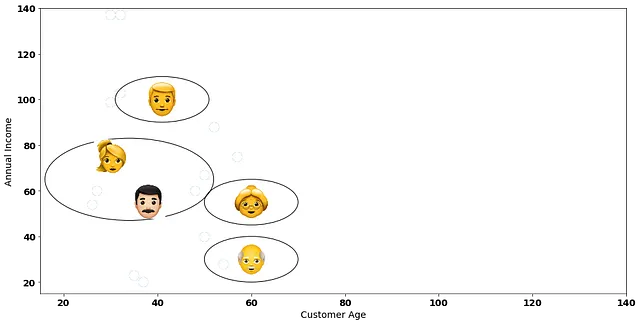
接下来,我们将再次计算数据点之间的距离。但是这一次,我们将把我们已经分组成单个簇的两个客户视为单个数据点。例如,考虑下面的红点,它位于两个数据点的中间:
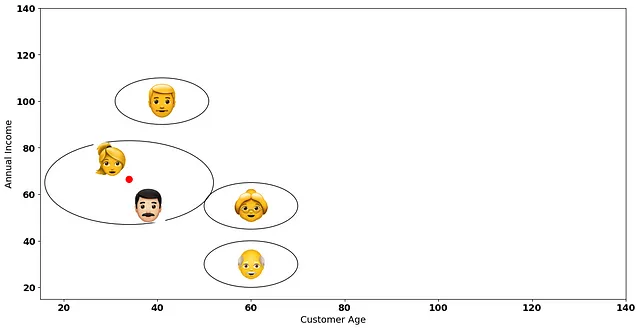
总之,对于我们的层次解决方案的下一次迭代,我们不会考虑原始数据点(表情符号)的坐标,而是考虑红点(那些数据点之间的平均值)。这是计算平均联接方法的标准方式。
我们可以使用以下其他方法基于聚合数据点计算距离:
- 最大(或完全联接):考虑与我们正在尝试聚合的点相关的簇中最远的数据点。
- 最小(或单一联接):考虑与我们正在尝试聚合的点相关的簇中最接近的数据点。
- Ward(或沃德联接):最小化具有下一个聚合的簇的方差。
让我在逐步解释方面稍作休息,深入探讨联接方法,因为它们在这种类型的聚类中至关重要。这是hierarchical clustering中可用的不同联接方法的视觉示例,用于合并3个集群的虚构示例:
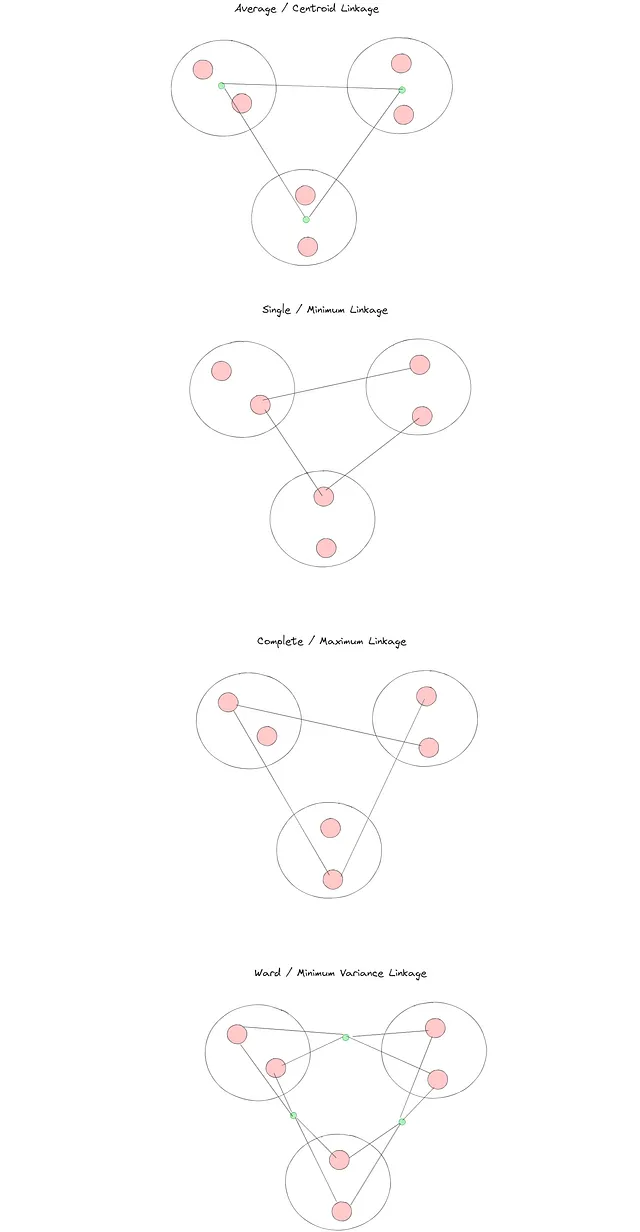
在sklearn实现中,我们将能够尝试其中一些联接方法,并看到聚类结果的显着差异。
回到我们的例子,现在让我们生成所有新数据点之间的距离,记住从现在开始有两个被视为单个数据点的簇:
- [60, 30]和[60, 55]之间的距离:25.0
- [60, 30]和[34, 65]之间的距离:43.60
- [60, 30]和[41, 100]之间的距离:72.53
- [60, 55]和[34, 65]之间的距离:27.85
- [60, 55]和[41, 100]之间的距离:48.85
- [34, 65]和[41, 100]之间的距离:35.69
哪条路径最短?它是坐标[60,30]和[60,55]之间数据点的路径:
自然而然的下一步是将这两个客户合并成一个聚类:
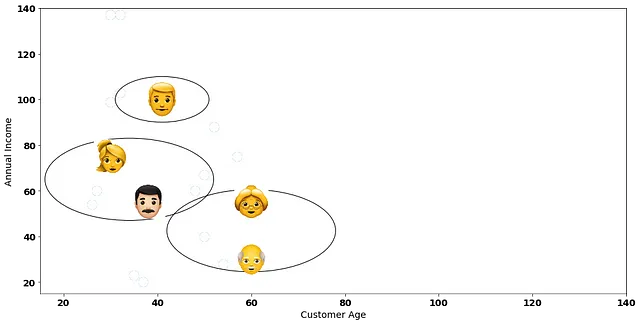
有了这个新的聚类景观,我们再次计算成对距离!请记住,我们总是考虑每个聚类中数据点之间的平均值(由于我们选择的链接方法),作为距离计算的参考点:
- [60,42.5]和[34,65]之间的距离:34.38
- [60,42.5]和[41,100]之间的距离:60.56
- [34,65]和[41,100]之间的距离:35.69
有趣的是,下一个要聚合的数据点是这两个聚类,因为它们位于坐标[60,42.5]和[34,65]上:

最后,我们通过聚合所有数据点来完成算法,形成一个大的聚类:
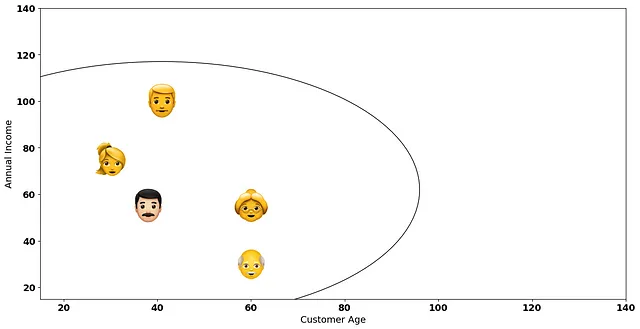
有了这个想法,我们到底在哪里停止?拥有所有数据点的单个大聚类可能不是一个好主意,对吗?
要知道我们何时停止,有一些启发式规则可以使用。但首先,我们需要熟悉另一种可视化刚刚完成的过程的方式——树状图:
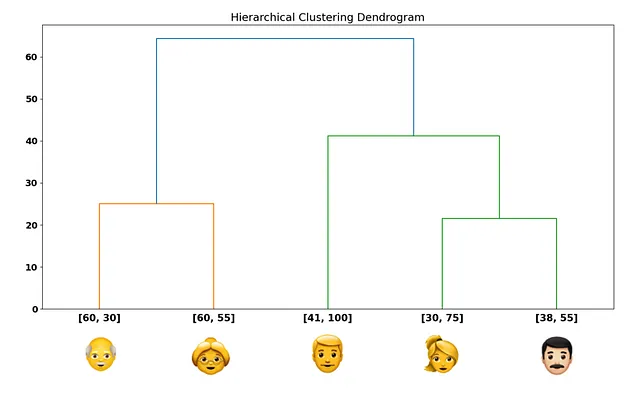
在y轴上,我们有刚刚计算的距离。在x轴上,我们有每个数据点。从每个数据点上升,我们到达一个水平线——这条线的y轴值表示将连接边缘上的数据点的总距离。
还记得我们连接到单个聚类的第一个客户吗?我们在2D图中看到的与树状图匹配,因为正是使用水平线连接的第一个客户(从下面爬升树状图):

水平线代表我们刚刚完成的合并过程!自然而然,树状图以连接所有数据点的大水平线结束。
现在我们已经熟悉了树状图,我们准备好检查sklearn实现并使用真实数据集,了解如何基于这种酷炫的聚类方法选择适当的聚类数量!
Sklearn实现
对于sklearn实现,我将使用此处提供的Wine Quality数据集。
wine_data = pd.read_csv('winequality-red.csv', sep=';')wine_data.head(10)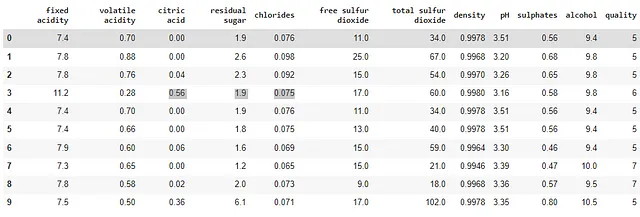
该数据集包含有关葡萄酒(尤其是红葡萄酒)的不同特征,如柠檬酸、氯化物或密度。数据集的最后一列给出了葡萄酒的质量,由陪审团进行分类。
由于层次聚类涉及距离,并且我们将使用欧几里德距离,因此我们需要标准化我们的数据。我们将从在我们的数据上使用StandardScaler开始:
from sklearn.preprocessing import StandardScalersc = StandardScaler()wine_data_scaled = sc.fit_transform(wine_data)有了我们的标准化数据集,我们就可以拟合我们的第一个层次聚类解决方案!我们可以通过创建一个AgglomerativeClustering对象来访问层次聚类:
average_method = AgglomerativeClustering(n_clusters = None, distance_threshold = 0, linkage = 'average')average_method.fit(wine_data_scaled)让我详细说明一下我们在AgglomerativeClustering中使用的参数:
n_clusters=None用作获取完整聚类解决方案的一种方式(在这里我们可以生成完整的树状图)。distance_threshold = 0必须在sklearn实现中设置,以生成完整的树状图。linkage = 'average'是一个非常重要的超参数。请记住,在理论实现中,我们已经描述了一种方法来考虑新形成的聚类之间的距离。average是一种方法,它在计算新距离时考虑每个新形成的聚类之间的平均点。在sklearn实现中,我们还有另外三种方法,我们也已经描述过:single、complete和ward。
拟合模型后,就可以绘制我们的树状图了。为此,我将使用sklearn文档中提供的辅助函数:
from scipy.cluster.hierarchy import dendrogramdef plot_dendrogram(model, **kwargs): # 创建链接矩阵,然后绘制树状图 # 创建每个节点下的样本计数 counts = np.zeros(model.children_.shape[0]) n_samples = len(model.labels_) for i, merge in enumerate(model.children_): current_count = 0 for child_idx in merge: if child_idx < n_samples: current_count += 1 # 叶节点 else: current_count += counts[child_idx - n_samples] counts[i] = current_count linkage_matrix = np.column_stack( [model.children_, model.distances_, counts] ).astype(float) # 绘制相应的树状图 dendrogram(linkage_matrix, **kwargs)如果我们绘制我们的层次聚类解决方案:
plot_dendrogram(average_method, truncate_mode="level", p=20)plt.title('Hierarchical Clustering的树状图 - 平均方法')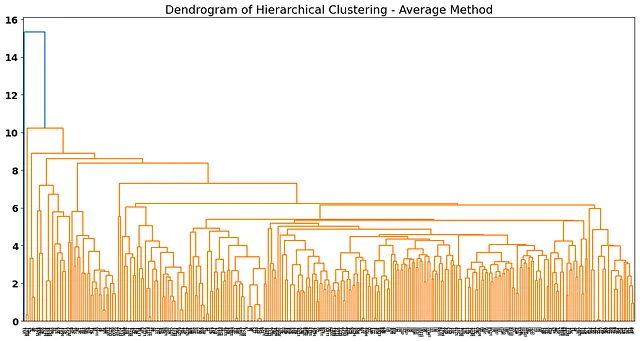
树状图不是很好,因为我们的观察结果似乎有点拥挤。有时候,当数据中存在强异常值时,average、single和complete链接可能会导致奇怪的树状图。 ward方法可能适用于这种类型的数据,因此让我们测试该方法:
ward_method = AgglomerativeClustering(n_clusters = None, distance_threshold = 0, linkage = 'ward')ward_method.fit(wine_data_scaled)plot_dendrogram(ward_method, truncate_mode="level", p=20)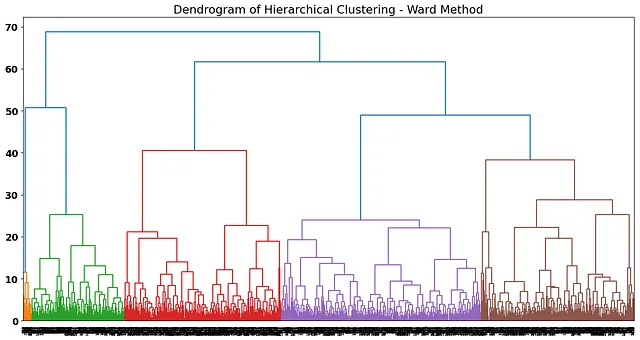
好多了!请注意,根据树状图,聚类似乎被更好地定义了。Ward方法试图通过最小化新形成聚类之间的内部方差(https://online.stat.psu.edu/stat505/lesson/14/14.7),就像我们在帖子的第一部分中所描述的那样,来划分聚类。目标是,对于每次迭代,被聚合的聚类最小化方差(数据点和新形成的聚类之间的距离)。
同样,通过更改AgglomerativeClustering函数中的linkage参数,可以实现更改方法!
由于我们对ward方法树状图的外观感到满意,因此我们将使用该解决方案进行聚类分析:
你能猜到我们应该选择多少个聚类吗?
根据距离,一个好的选择是在这个点上剪切树状图,这里每个聚类似乎相对离得比较远:
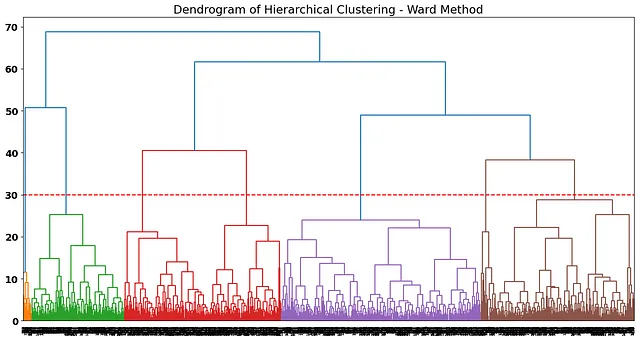
我们的线穿过的垂直线的数量是我们解决方案的最终聚类数。选择聚类数不是非常“科学”,可能会得到不同数量的聚类解决方案,这取决于业务解释。例如,在我们的情况下,稍微向上剪切我们的树状图并减少最终解决方案的聚类数也可能是一个假设。
我们将坚持7个聚类解决方案,因此让我们根据这些n_clusters拟合我们的ward方法:
ward_method_solution = AgglomerativeClustering(n_clusters = 7, linkage = 'ward')wine_data['cluster'] = ward_method_solution.fit_predict(wine_data_scaled)由于我们希望根据原始变量解释我们的聚类,因此我们将在缩放的数据上使用预测方法(距离基于缩放的数据集),但将聚类添加到原始数据集中。
让我们使用cluster变量条件下的每个变量的平均值来比较我们的聚类:
wine_data.groupby([‘cluster’]).mean()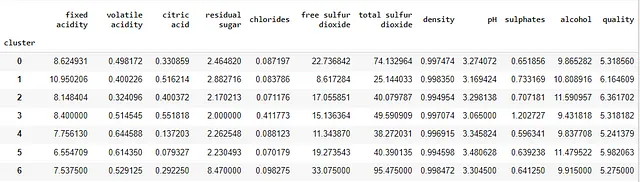
有趣的是,我们可以开始对数据有一些见解——例如:
- 低质量的葡萄酒似乎具有较大的
总二氧化硫值——请注意最高平均质量聚类和较低质量聚类之间的差异:
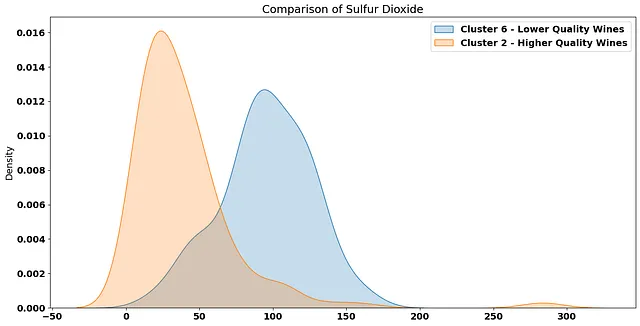
如果我们比较这些簇中葡萄酒的 质量 :
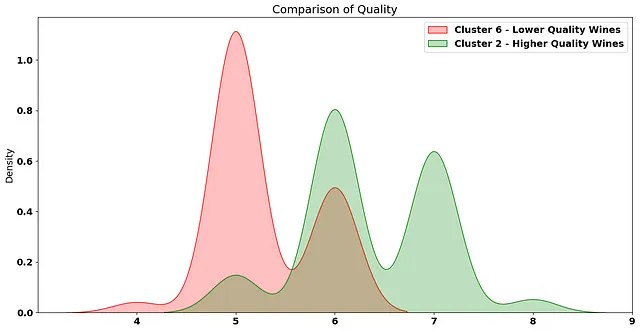
很明显,平均而言,簇2中包含更高质量的葡萄酒。
我们可以进行的另一个很酷的分析是在聚类数据均值之间执行相关矩阵:
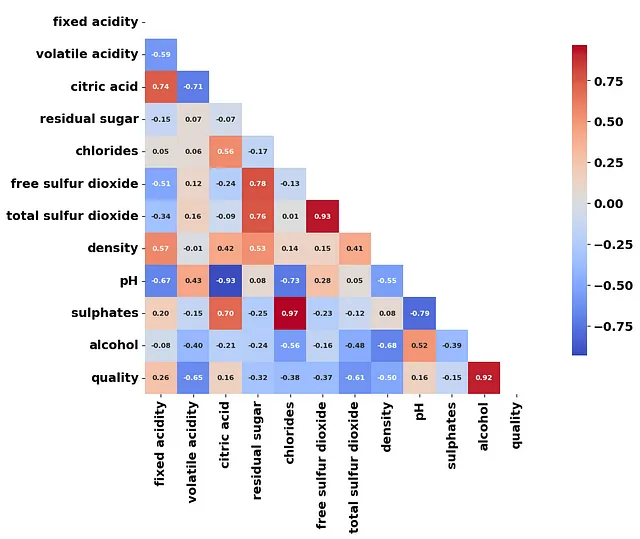
这为我们提供了一些潜在的探索线索(甚至可以用于监督学习)。例如,在多维水平上,具有更高 硫酸盐 和 氯化物 的葡萄酒可能会被捆绑在一起。另一个结论是,酒精含量更高的葡萄酒往往与更高质量的葡萄酒相关。
结论
就是这样!谢谢你花时间阅读这篇关于无监督学习的博客文章。我将继续添加更多的无监督学习算法到这个系列中,以展示我们可以使用的不同类型的方法来了解我们数据的结构。
当然,层次聚类有一些优点和缺点,我们可以讨论:
- 该算法的一个主要缺点是可能需要太多的启发式来达到最终解决方案。可以结合树状图分析、基于距离的分析或轮廓系数方法来达到合理的聚类数量。此外,必须不要忽略将这些技术方法与一些关于数据的业务知识相结合,以避免落入某种聚类陷阱。
- 在积极方面,层次聚类方法非常易于解释,有助于揭示数据中隐藏的结构。
- 此外,层次聚类不会受到质心初始化问题的影响 – 对于某些数据集,这可能是一个优点。
层次聚类是一种非常著名的聚类方法,已被应用于多种应用程序,如:
- 客户细分;
- 异常值分析;
- 分析多维基因表达数据;
- 文档聚类;
这是一种非常酷的方法,数据科学家应该掌握。随意在您的下一个项目中尝试它,并继续关注这个无监督学习系列的更多帖子!
如果您想参加我的Python课程,可以免费加入我的免费课程( Python For Busy People — Python Introduction in 2 Hours ),或者加入更长的16小时版本( The Complete Python Bootcamp for Beginners )。我的Python课程适合初学者/中级开发人员,我很乐意让您参加我的课程!
此帖子使用的数据集根据Creative Commons Attribution 4.0 International (CC BY 4.0)许可证进行许可。





