微软研究人员提出BioViL-T:一种新颖的自我监督框架,引入了在生物医学应用中提高预测性能和数据效率的增强型技术


人工智能(AI)已经成为许多行业的重要破坏性力量,从技术企业的运营方式到如何在医疗保健领域的不同子领域中解锁创新。特别是,在引入AI的情况下,生物医学领域已经见证了重大的进展和转型。这样一个值得注意的进展可以归结为在放射学中使用自我监督的视觉语言模型。放射科医师在传达成像观察和提供临床诊断时非常依赖放射学报告。值得注意的是,先前的成像研究经常在这个决策过程中发挥关键作用,因为它们为评估疾病发展过程和建立合适的药物选择提供了关键的上下文。然而,由于无法获得以前的扫描,当前的AI解决方案在标记中无法成功地将图像与报告数据对齐。此外,这些方法通常不考虑生物数据集中通常存在的疾病或成像发现的时间发展。缺乏上下文信息会对下游应用(如自动报告生成)构成风险,其中模型可能在没有访问过去的医学扫描的情况下生成不准确的时间内容。
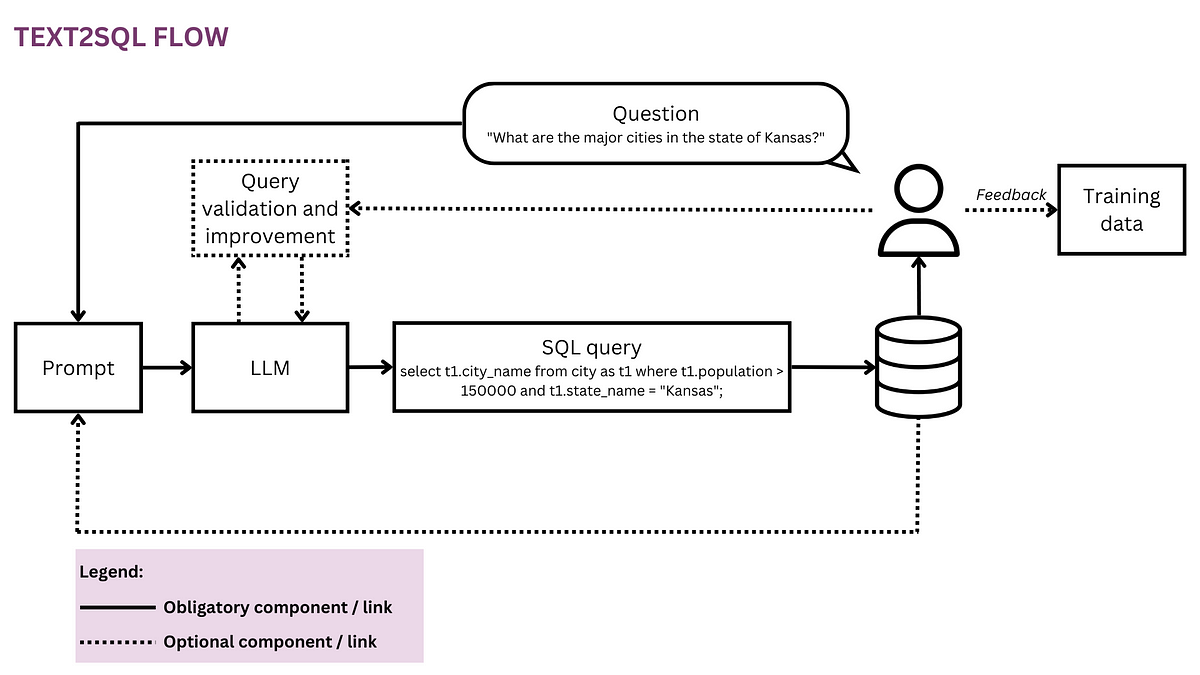
随着视觉语言模型的引入,研究人员旨在通过利用图像 – 文本对生成信息丰富的训练信号,从而消除手动标签的需要。这种方法使模型能够学习如何准确地识别和定位图像中的发现,并与呈现在放射学报告中的信息建立联系。微软研究不断致力于改进报告和放射学AI。他们以前在放射学报告和图像的多模态自我监督学习方面的研究已经在识别医学问题和定位这些发现方面取得了令人鼓舞的成果。作为对这一研究浪潮的贡献,微软发布了BioViL-T,这是一个自我监督训练框架,它在训练和微调过程中考虑了早期的图像和报告(如果有)。通过利用数据集中存在的现有时间结构,BioViL-T在各种下游基准测试(如进展分类和报告创建)方面取得了突破性的结果。该研究将于2023年在著名的计算机视觉和模式识别会议(CVPR)上展示。
BioViL-T的独特之处在于其在整个训练和微调过程中明确考虑以前的图像和报告,而不是将每个图像 – 报告对视为单独的实体。研究人员将以前的图像和报告纳入考虑的原因主要是为了最大化可用数据的利用,从而在更广泛的任务范围内获得更全面的表示和更强大的性能。BioViL-T引入了一种独特的CNN-Transformer多图像编码器,该编码器与文本模型共同训练。这种新颖的多图像编码器作为预训练框架的基本构建块,解决了不存在以前的图像和图像随时间的姿态变化等挑战。
选择CNN和Transformer模型创建混合多图像编码器,从图像序列中提取时空特征。当有可用的以前的图像时,Transformer负责捕获跨时间的补丁嵌入交互。另一方面,CNN负责给出单个图像的视觉令牌属性。这种混合图像编码器提高了数据效率,使其适用于甚至更小的数据集。它有效地捕捉静态和时间图像特征,这对于需要在时间上进行密集级别的视觉推理的应用(如报告解码)至关重要。BioViL-T模型的预训练过程可以分为两个主要组件:用于提取时空特征的多图像编码器和包括可选的与图像特征的交叉关注的文本编码器。这些模型使用交叉模态全局和局部对比目标进行联合训练。模型还利用通过交叉关注获得的多模态融合表示来进行基于图像的掩码语言建模,从而有效地利用视觉和文本信息。这在消除歧义和增强语言理解方面起着核心作用,这对于广泛的下游任务非常重要。
微软研究人员的策略的成功得益于他们进行的各种实验评估。该模型在单一和多图像配置中实现了下游任务的最新性能,如进展分类、短语接地和报告生成。此外,它在疾病分类和句子相似性等任务上改进了先前的模型,并产生了可观的结果。微软研究已经向公众提供了该模型和源代码,以鼓励社区进一步研究他们的工作。研究人员还发布了一个全新的多模态时间基准数据集MS-CXR-T,以刺激进一步研究视觉语言表示如何捕捉时间语义。