线性回归与梯度下降
了解最基础的机器学习算法
线性回归是机器学习中存在的最基本的算法之一。了解其内部工作流程有助于掌握数据科学中其他算法的主要概念。线性回归具有广泛的应用,用于预测连续变量。
在深入研究线性回归的内部工作原理之前,让我们先了解回归问题。
介绍
回归是一个机器学习问题,旨在根据通常表示为 x = <x₁, x₂, x₃, …, xₙ> 的特征向量来预测连续变量的值,其中 xᵢ 表示数据中第 i 个特征的值。为了使模型能够进行预测,它必须在包含从特征向量 x 到相应的目标变量 y 的映射的数据集上进行训练。学习过程取决于用于特定任务的算法类型。

在线性回归的情况下,模型学习了这样的权重向量 w = <x₁, x₂, x₃, …, xₙ> 和偏置参数 b,试图以最佳方式近似目标值 y,如 <w,x> + b = x₁ * w₁ + x₂ * w₂ + x₃ * w₃ + … + xₙ * wₙ + b 对于每个数据集观测(x,y)。
公式
构建线性回归模型时,最终目标是找到一个权重向量 w 和一个偏差项 b,以更接近地将预测值 ŷ 带到所有输入的真实目标值 y:
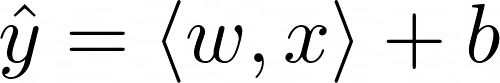
为了使事情变得更简单,在我们即将查看的示例中,将使用具有单个特征 x 的数据集。因此,x 和 w 是一维向量。为简单起见,让我们摆脱内积符号,并以以下方式重写上面的方程:
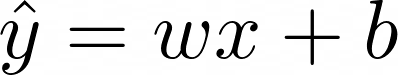
损失函数
为了训练算法,必须选择一个损失函数。损失函数衡量算法在单个训练迭代中对一组对象进行预测的好坏程度。根据其值,算法调整模型的参数,希望在未来模型会产生更少的错误。
最流行的损失函数之一是均方误差(或简称 MSE ),它衡量预测值和真实值之间的平均平方偏差。
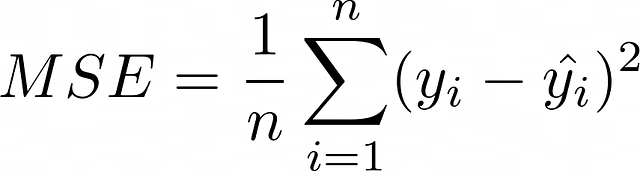
梯度下降
梯度下降是一种迭代算法,通过搜索局部最小值来更新权重向量以最小化给定损失函数。梯度下降在每次迭代中使用以下公式:
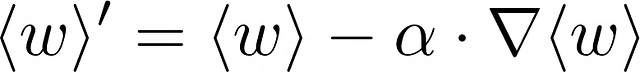
- <w>是当前迭代中模型权重的向量。计算出的权重被分配给<w>。在算法的第一次迭代中,权重通常是随机初始化的,但也存在其他策略。
- alpha通常是一个小的正值,也称为学习率,即控制寻找局部最小值速度的超参数。
- 倒三角形表示梯度——损失函数的偏导数向量。在当前示例中,权重向量由2个组成成分。因此,要计算<w>的梯度,需要计算2个偏导数(f代表损失函数):
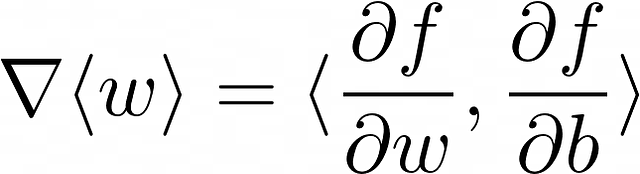
更新公式可以用以下方式重写:

现在的目标是找到f的偏导数。假设MSE被选择作为损失函数,让我们为单个观察值(n = 1)计算它,所以f = (y – ŷ)² = (y – wx – b)²。
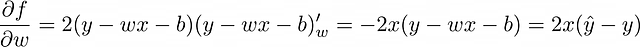
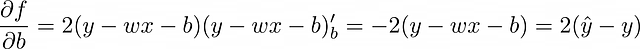
基于单个对象进行模型权重的调整过程被称为随机梯度下降。
批量梯度下降
在上面的部分中,通过计算单个对象(n = 1)的MSE来更新模型参数。实际上,可以在单次迭代中为多个对象执行梯度下降。这种更新权重的方式称为批量梯度下降。
在这种情况下,更新权重的公式可以通过与上一部分中的随机梯度下降进行类似的方式获得。唯一的区别是这里必须考虑对象n的数量。最终,计算批次中所有对象的术语的总和,然后除以n——批量大小。
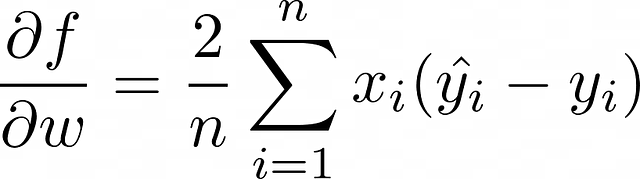
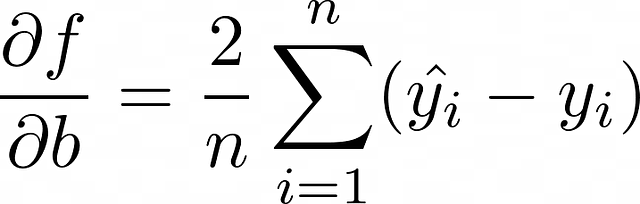
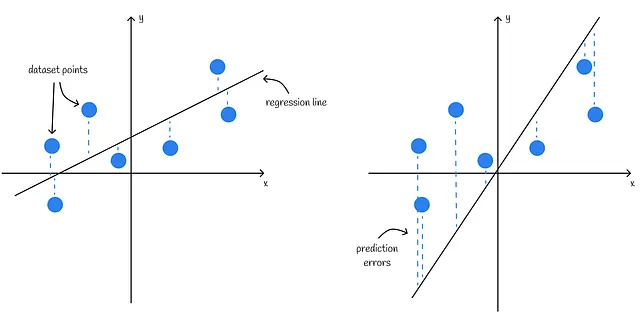
可视化
当处理仅包含单个特征的数据集时,回归结果可以在2D图中轻松可视化。水平轴表示特征值,而垂直轴包含目标值。
线性回归模型的质量可以通过它与数据集点的拟合程度来进行视觉评估:每个数据集点到线的平均距离越近,算法越好。
如果一个数据集包含更多的特征,那么可以使用降维技术如PCA或t-SNE应用于特征,将它们表示成低维度。之后,新特征就可以像往常一样绘制在2D或3D图中。
分析
线性回归有一些优点:
- 训练速度。由于算法的简单性,线性回归可以快速训练,与更复杂的机器学习算法相比。此外,它可以通过相对较快且易于理解的最小二乘法来实现。
- 可解释性。为几个特征构建的线性回归方程可以轻松地解释其特征的重要性。特征系数的值越高,它对最终预测的影响就越大。
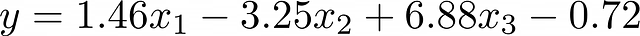
另一方面,它也有一些缺点:
- 数据假设。在拟合线性回归模型之前,重要的是要检查输出和输入特征之间的依赖关系类型。如果是线性的,那么拟合它就不应该有任何问题。否则,模型通常无法很好地拟合数据,因为方程中只有线性项。实际上,可以将更高的度数添加到方程中,将算法转化为多项式回归,例如。然而,在现实中,没有很多领域知识,通常很难正确预见依赖关系类型。这就是线性回归可能不适应给定数据的原因之一。
- 多重共线性问题。多重共线性是指两个或多个预测变量高度相关。想象一下,当一个变量的变化影响另一个变量时的情况。然而,训练好的模型没有关于此的信息。当这些变化很大时,在未见过的数据推理阶段,模型很难保持稳定。因此,这导致了过拟合的问题。此外,由于这个原因,最终的回归系数也可能不稳定,难以解释。
- 数据归一化。为了将线性回归用作特征重要性工具,必须对数据进行归一化或标准化。这将确保所有最终的回归系数处于相同的比例尺上,并可以正确解释。
结论
我们已经看过线性回归——一种在机器学习中简单但非常流行的算法。其核心原理被用于更复杂的算法。
尽管线性回归在现代生产系统中很少使用,但其简单性使其经常用作回归问题的标准基线,然后与更复杂的解决方案进行比较。
本文中使用的源代码可以在此处找到:
ML-小猪AI/linear_regression.ipynb at master · slavafive/ML-小猪AI
您无法执行此操作。您在另一个选项卡或窗口中登录了。您在另一个选项卡或窗口中签出了。
github.com
资源
- 最小二乘法|维基百科
- 多项式回归|维基百科
除非另有说明,否则所有图片均为作者所拍。




