预测星巴克奖励计划的成功
初学者友好——从头到尾逐步解释完整项目
项目概览
该项目旨在确定有效吸引星巴克现有客户和吸引新客户的奖励计划。
星巴克是一家数据驱动型公司,通过利用包含客户信息、特别优惠和交易数据的数据集,投资于获得对其客户的全面了解。
为了开发一个能够确定奖励计划成功的模型,我将该项目分为三个阶段:
- 检查和清洗由Udacity提供的数据。
- 创建一个数据集,结合所有相关信息。
- 构建和评估三个分类模型,以预测特定人员的奖励计划的成功或失败。
问题陈述
在营销活动中进行重大投资是一个复杂的决策,需要获得各方利益相关者的批准、财务资源和时间。因此,拥有一个可以分类是否值得针对特定目标群体启动特定优惠的预测模型,成为任何公司的战略资产。
为了创建这个模型,我们将采用二元分类的监督学习技术。
模型的输出将指示优惠是否预计有效。
数据集探查与整理
Udacity向我们提供了三个JSON格式的数据集:portfolio、profile和transcript。每个数据集都有不同的用途,并为我们的分析提供了有价值的信息。
投资组合数据集
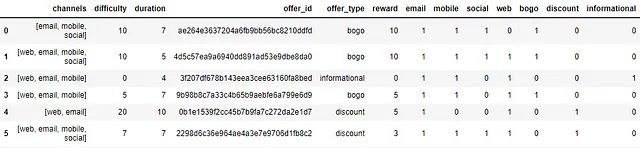
该数据集提供有关星巴克提供的活动优惠的信息。
- id (string) — 优惠id
- offer_type (string) — 优惠类型,如BOGO、折扣、信息
- difficulty (int) — 完成优惠所需的最低消费
- reward (int) — 完成优惠后给予的奖励
- duration (int) — 优惠开放的时间,以天为单位
- channels (list of strings)

portfolio数据集中有十行和六列。这是一个简单的数据集,没有缺失、空值或重复值。
‘channels’、‘id’、‘offer_type’列是分类变量,而‘difficulty’、‘duration’、‘reward’是整数。
请参见下面我对数据集所做的修改:
- 对‘channels’和‘offer_type’进行独热编码
- 将‘id’更改为‘offer_id’
档案数据集
个人资料数据集包含有关星巴克顾客的人口统计信息。
- age (int) — 顾客的年龄
- became_member_on (int) — 顾客创建应用帐户的日期
- gender (str) — 顾客的性别(注意,某些条目包含“O”表示其他,而不是M或F)
- id (str) — 顾客id
- income (float) — 顾客的收入
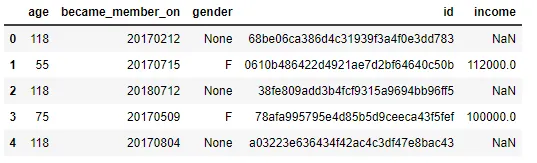
此数据集中有17000行(唯一的人数)和5列,其中有2175个空值项目(在gender和income列中都有)。由于这些行的年龄值也是118,因此我从数据集中删除了所有2175行。
请参见下面我对数据集所做的修改:
- 删除2175个具有缺失值的行(年龄值为118)
- 将‘id’更改为‘customer_id’
- ‘become_member_on’字符串转换为日期
- 创建‘year_joined’和‘membership_days’列
- 对‘gender’进行独热编码
- 创建‘age_group’来将客户分类为青少年、年轻成年人、成年人、老年人
- 创建‘income_range’将客户分类为平均、高于平均、高
- 创建‘member_type’将客户分类为新客户、普通客户、忠实客户

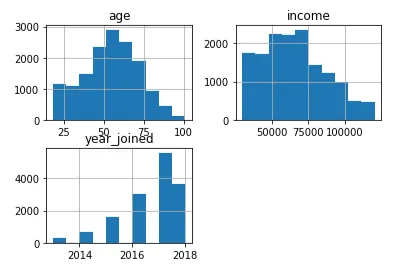
可以看出,加入计划的人数在2013年至2017年之间呈增长趋势,2017年是最好的一年。 %50的会员年龄在42岁到66岁之间。
如下所示,男性人口在较低和平均收入区域中超过女性人口,而女性人口在较高收入区域中超过男性人口。
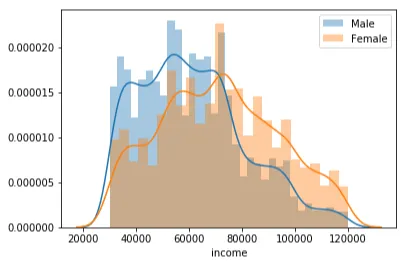
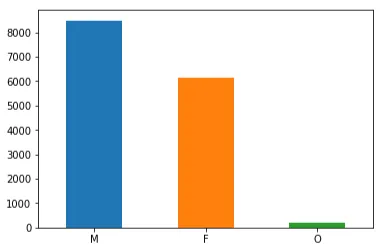
考虑到性别,数据集有点偏见,因为男性人口超过女性人口,其他类别的人数很少。具体数字如下:数据集中有8484个男性、6129个女性和仅212个其他人。
交易数据集
交易数据集记录了客户与优惠活动的互动。
- event (str) — 记录描述(即交易、优惠接收、优惠查看等)
- person (str) — 客户ID
- time (int) — 从测试开始以小时计算的时间。数据从t=0开始
- value — (字符串字典) — 根据记录,可以是优惠ID或交易金额
如果交易数据集中的事件对应于三种可能的优惠状态(已查看、已接收或已完成),则value列包含优惠的ID。除了优惠ID之外,如果事件处于“优惠完成”状态,则还将有奖励值。
但是,如果事件是交易,则value列只会显示交易金额。
请参见下面我对数据集所做的修改:
- 将“value”扩展为“offer_id”,“amount”,“rewards”新列。
- 通过将时间(小时)转换为天数来创建“time_in_days”。
- 将“person”更改为“customer_id”
- 将交易数据集分为两个子数据集,即offer_tr(优惠数据)和transaction_tr(交易数据)
建立模型
一旦数据集已经清理并进行了必要的修改,我们需要将它们合并成一个单一的数据集。然后,我们将创建一个名为offer_successful的新列。该列将指示特定客户的优惠是否成功。这将使我们能够构建可以预测某种类型客户的某个优惠是否成功的模型。
客户必须在允许的时间范围内查看并完成优惠,以便将优惠视为成功。我开发了一个支持函数,通过考虑已完成和已查看的优惠数据以及这些事件之间的时间范围来计算目标值。
为了创建一个可以预测某个优惠是否成功的模型,我们需要在最终数据集上训练模型。
成功和不成功的优惠数量分别为35136和31365。这意味着我们在考虑目标时具有平衡的数据集,因此我们没有任何关于我们可以选择哪些模型的限制(这是不平衡数据集的限制)。
由于这是一个二分类问题,我们将使用三种不同的监督学习算法。
- 逻辑回归
- 随机森林
- 梯度提升
我将使用RandomizedSearchCV进行12次迭代,以优化模型的超参数,因为它比GridSearchCV计算成本更低。 RandomizedSearchCV通过从指定分布中随机抽样超参数值来工作。
度量和结果
我将使用混淆矩阵和下面的指标来评估模型的性能。
我将特别关注精度作为研究的主要目的是尽可能定义正类。
- 准确率:准确率是评估分类模型准确性最常用的指标。它通过将正确预测数除以总预测数来计算。
- 精度:精度是模型在预测正类时的准确度。它通过将真正例数除以真正例数加假正例数来计算。
- 召回率:召回率是模型在预测正类时的完整性度量。它通过将真正例数除以真正例数加假反例数来计算。
- F1得分:F1得分是精度和召回率的加权平均值。它通过将2 *(精度*召回率)除以(精度+召回率)来计算。
结果:
- 逻辑回归 ……. → 准确率:0.69,精度:0.66
- 随机森林 …………. → 准确率:0.70,精度:0.66
- 梯度提升 ……… → 准确率:0.69,精度:0.66
尽管所有模型提供的性能指标相似,但随机森林具有稍好的准确率。
结论和改进
尽管这些模型提供了一个良好的起点,但%66精度的结果还有改进的空间。
这个项目的一个有趣的改进方法是创建多个监督学习模型并将它们组合成自定义的集成模型。通过组合多个监督学习模型来创建集成模型,可以弥补错误的优势。通过利用不同模型的优势并弥补它们的弱点,集成模型实现更好的泛化性能,从而提高准确性和鲁棒性。
为了提高我们的奖励计划预测的准确性,我们可以考虑将不同类型的奖励分开,并为每个计划开发单独的模型。通过采用这种方法,我们可以将建模技术量身定制到每个奖励计划的特定特征和目标上,最终实现更精确的预测和更好的结果。这种方法也可以帮助我们识别每个奖励计划中的任何独特趋势或模式,从而实现更有效的计划设计和实施。
优化我们奖励计划效果的另一种方法是识别和排除无论是否有奖励计划都购买的人。通过这样做,我们可以将资源集中在那些更有可能对计划结果产生积极影响的人身上,最终最大化我们从计划中获得的好处。




