什么是向量数据库,为什么它们对LLM很重要?
大型语言模型(LLMs)目前对人工智能领域有着重要的影响了解向量数据库对LLMs的重要性是至关重要的

当您在 Twitter、LinkedIn 或新闻源上浏览时间线时,您可能会看到有关聊天机器人、LLM 和 GPT 的内容。许多人正在谈论 LLM,因为每周都会发布新的 LLM。
由于我们目前生活在人工智能革命中,因此了解许多这些新应用程序依赖于向量嵌入是很重要的。因此,让我们更深入地了解向量数据库以及它们对 LLM 的重要性。
- 如何利用数据科学进行营销?
- 微软研究人员提出BioViL-T:一种新颖的自我监督框架,引入了在生物医学应用中提高预测性能和数据效率的增强型技术
- 认识 TARDIS:一种人工智能框架,可以识别复杂空间中的奇异性,捕捉图像数据中的奇异结构和局部几何复杂性
什么是向量数据库?
让我们首先定义向量嵌入。 向量嵌入 是一种数据表示类型,它携带语义信息,有助于 AI 系统更好地理解数据,并能够保持长期记忆。在您尝试学习任何新知识时,重要的元素是理解该主题并记住它。
嵌入 是由 AI 模型生成的,例如包含大量特征的 LLM,这使得它们的表示很难管理。嵌入表示数据的不同维度,以帮助 AI 模型理解不同的关系、模式和隐藏结构。
使用传统基于标量的数据库进行向量嵌入是一项挑战,因为它无法处理或跟上数据的规模和复杂性。尽管向量嵌入具有的所有复杂性,但您可以想象出它需要的专业数据库。这就是向量数据库发挥作用的地方。
向量数据库 为向量嵌入的独特结构提供了优化的存储和查询功能。它们通过比较值并找到彼此之间的相似之处来提供易于搜索、高性能、可扩展性和数据检索。
听起来很棒,对吧?有解决向量嵌入结构复杂性的方法。是的,但也不完全是。向量数据库非常难以实现。
迄今为止,只有那些有能力不仅开发而且还能够管理向量数据库的技术巨头才在使用向量数据库。向量数据库很昂贵,因此确保它们被正确校准以提供高性能很重要。
向量数据库如何工作?
现在我们对向量嵌入和数据库有了一些了解,让我们进入它的工作原理。
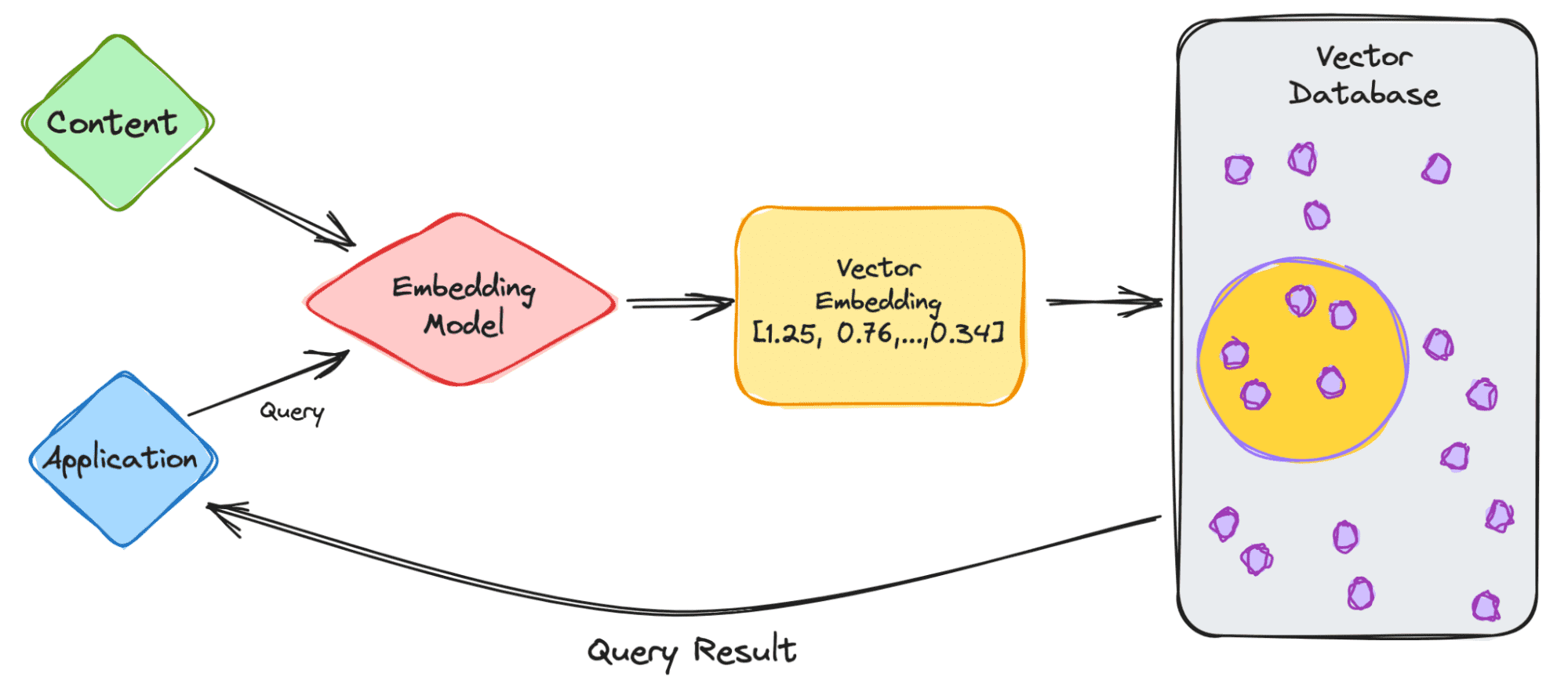
让我们从处理 ChatGPT 等 LLM 的简单示例开始。该模型具有大量的数据和内容,他们为我们提供了 ChatGPT 应用程序。
那么,让我们一步步来。
- 作为用户,您将把您的查询输入到应用程序中。
- 然后,您的查询将被插入到嵌入模型中,该模型基于我们要进行索引的内容创建向量嵌入。
- 然后向量嵌入将移动到向量数据库,涉及嵌入所生成的内容。
- 向量数据库生成输出并将其作为查询结果发送回用户。
当用户继续进行查询时,将通过相同的嵌入模型来创建用于查询那个数据库的嵌入。向量嵌入之间的相似之处基于创建嵌入的原始内容。
想了解更多关于它如何在向量数据库中工作的信息吗?让我们更深入地了解。
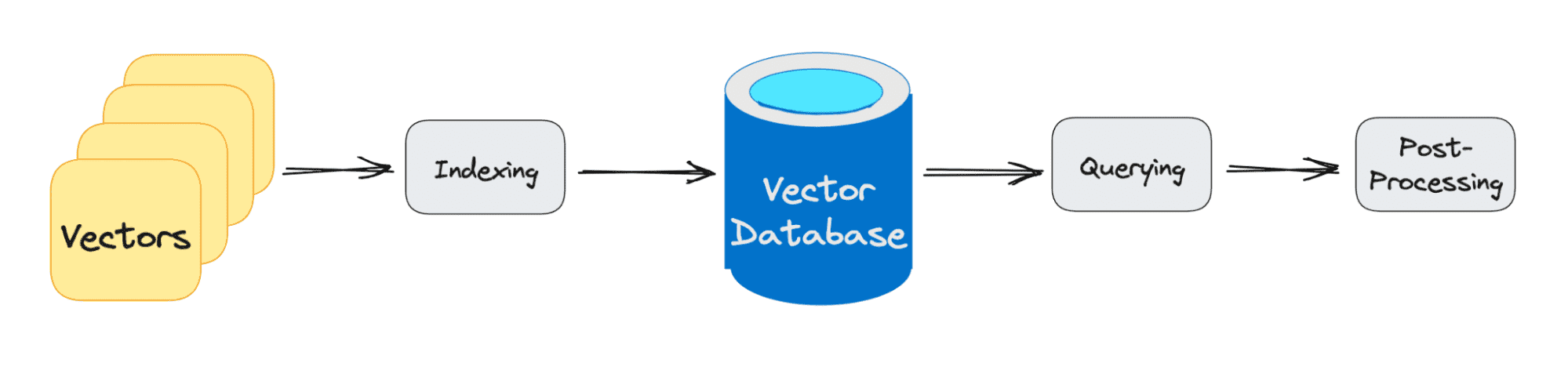
传统数据库处理存储字符串、数字等在行和列中。当从传统数据库查询时,我们查询与我们的查询匹配的行。然而,向量数据库使用向量而不是字符串等。向量数据库还应用相似度度量,用于帮助找到与查询最相似的向量。
向量数据库由不同的算法组成,这些算法都有助于近似最近邻 (ANN) 搜索。这是通过哈希、基于图的搜索或量化来完成的,这些都组装成一个管道来检索查询向量的邻居。
结果基于其与查询的接近程度或近似程度,因此考虑的主要元素是准确性和速度。如果查询输出较慢,则结果越准确。
向量数据库查询经过的三个主要阶段是:
1. 索引
如上例所述,一旦向量嵌入移动到向量数据库中,它便使用多种算法将向量嵌入映射到数据结构以进行更快的搜索。
2. 查询
一旦完成搜索,向量数据库将查询的向量与索引向量进行比较,应用相似度度量来查找最近邻。
3. 后处理
根据您使用的向量数据库,向量数据库将后处理最终的最近邻以生成查询的最终输出。可能还会重新排列最近邻以供将来参考。
总结
随着我们不断看到人工智能的增长和每周发布新系统,向量数据库的增长正在发挥重要作用。向量数据库使公司能够更有效地进行准确的相似性搜索,为用户提供更好、更快的输出。
所以,下次当你在ChatGPT或Google Bard中输入一个查询时,请考虑它输出结果的过程。
Nisha Arya是一名数据科学家、自由职业技术作家和小猪AI社区经理。她特别感兴趣为数据科学提供职业建议或教程和基于理论的数据科学知识。她还希望探索人工智能在延长人类寿命方面所带来的不同方式。她是一位热心的学习者,希望扩展自己的技术知识和写作技能,同时帮助指导他人。