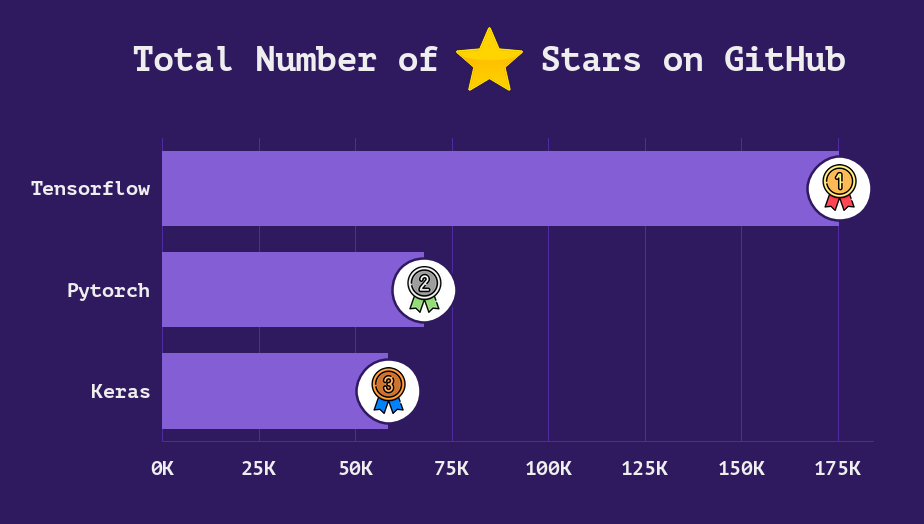
小心模型评估中的不可靠数据:Flan-T5的LLM提示选择案例研究
除非您清洗测试数据,否则可能会通过模型评估选择次优提示来为您的LLM选择次优选择

可靠的模型评估是MLops和LLMops的核心,指导关键决策,例如部署哪个模型或提示(以及是否部署)。在本文中,我们使用各种提示来提示来自Google研究的FLAN-T5 LLM,以将文本分类为礼貌或不礼貌。在提示候选项中,我们发现根据观察到的测试准确性表现最佳的提示实际上经常比其他提示候选项更差。对测试数据的更仔细的审核揭示这是由于不可靠的注释。在现实世界的应用中,除非您清洗测试数据以确保其可靠,否则可能会通过模型评估选择次优提示来为您的LLM选择次优选择。
虽然嘈杂注释的危害在训练数据中已经得到了充分的表征,但本文展示了它们在测试数据中经常被忽略的后果。
我目前是Cleanlab的数据科学家,我很高兴分享高质量测试数据的重要性以及如何确保它以确保最佳LLM提示选择。
概述
您可以在此处下载数据。
本文研究的是斯坦福礼貌数据集的二元分类变体(在CC BY许可证v4.0下使用),其中文本短语被标记为礼貌或不礼貌。我们使用包含700个短语的固定测试数据集来评估模型。

评估“好”分类模型的标准做法是通过测量其对模型训练期间未看到的示例的预测准确性来进行,通常称为“测试”,“评估”或“验证”数据。这提供了一个数字指标,以衡量模型A对模型B的相对表现—如果模型A显示更高的测试准确性,我们估计它是更好的模型,并选择部署它而不是模型B。除了模型选择外,相同的决策框架可以应用于其他选择,例如是否使用:超参数设置A或B,提示A或B,功能集A或B等。
现实世界测试数据的常见问题是一些示例具有不正确的标签,无论是由于人为注释错误,数据处理错误,传感器噪声等。在这种情况下,测试准确性成为模型A和模型B之间相对性能的不太可靠的指标。让我们使用一个非常简单的例子来说明这一点。想象一下,您的测试数据集中有两个不礼貌的文本示例,但是您(不知情地)将它们标记为礼貌。例如,在我们的斯坦福礼貌数据集中,我们看到实际的人类注释员错误地将这段文本标记为“您在这里疯了吗?!发生了什么?”礼貌,当语言显然是激动的。现在您的工作是选择最佳模型来对这些示例进行分类。模型A表示两个示例都不礼貌,而模型B表示两个示例都礼貌。基于这些(不正确的)标签,模型A得分为0%,而模型B得分为100%—您选择模型B进行部署!但是,请等一下,哪个模型实际上更强?
虽然这些影响是微不足道的,许多人都知道现实世界的数据充满了标记错误,但人们往往只关注其训练数据中的嘈杂标签,而忘记仔细策划测试数据,尽管它指导关键决策。使用真实数据,本文说明了高质量测试数据对于指导LLM提示选择的重要性,并演示了一种通过算法技术轻松改善数据质量的方法。
观察测试准确性 vs 干净测试准确性
在这里,我们考虑两个可能的测试集,它们由相同的文本示例集构成,仅在某些标签(约30%)上不同。代表您用于评估准确性的典型数据,其中一个版本的标签来自每个示例的单个注释(人工评分者),我们将计算在该版本上的模型预测的准确性称为观察到的测试准确性。该相同测试集的第二个更干净的版本具有通过多个人类评分者之间达成共识(来自多个人工评分者)建立的高质量标签。我们将在更干净的版本上测量的准确性称为干净测试准确性。因此,干净测试准确性更接近您所关心的内容(实际模型部署性能),但在大多数应用程序中,观察到的测试准确性是您能够观察到的所有内容-除非首先清理测试数据!
以下是两个测试示例,其中单个人类注释者错误地标记了示例,但是许多人类注释者组对正确标签达成了一致。
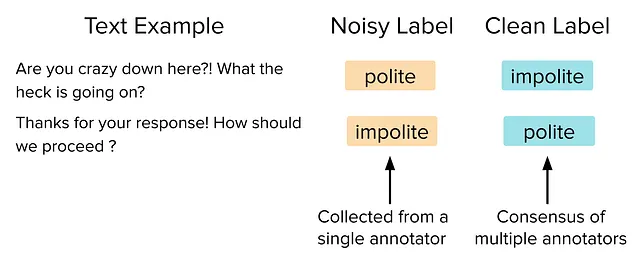
在实际项目中,您通常无法访问这样的“干净”标签,因此您只能测量观察到的测试准确性。如果您根据此度量制定重要决策(例如使用哪个LLM或提示),请务必首先验证标签的高质量性。否则,我们发现您可能会做出错误的决策,如在选择礼貌分类提示时所观察到的。
嘈杂评估数据的影响
作为分类文本礼貌的预测模型,自然而然地使用预训练的大型语言模型(LLM)。在这里,我们特别使用数据科学家最喜欢的LLM-开源FLAN-T5模型。为了使该LLM准确预测文本的礼貌程度,我们必须向其提供恰当的提示。提示工程可能非常敏感,稍作更改即可大大影响准确性!
下面显示的提示A和B(突出显示的文本)是两个不同的思维链提示示例,可以附加在任何文本样本前面,以便LLM对其礼貌进行分类。这些提示结合了提供示例,正确响应和鼓励LLM解释其推理的证明的少量样本和指令提示(稍后详细介绍)。这两个提示之间唯一的区别是突出显示的文本实际上是从LLM中引出响应的文本。少量样本和推理保持不变。
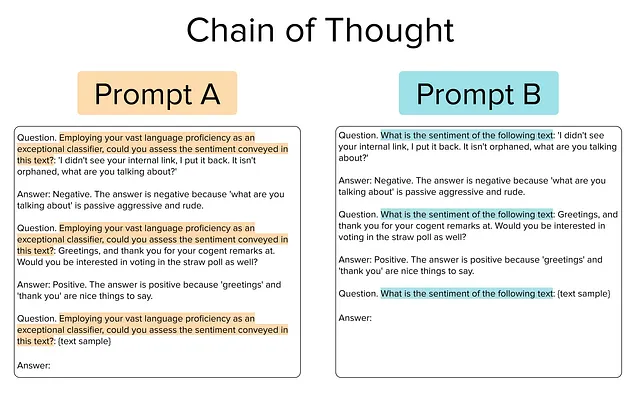
根据观察到的测试准确性来决定哪个提示更好是最自然的。当用于提示FLAN-T5 LLM时,我们发现Prompt A在原始测试集上产生的分类比Prompt B具有更高的观察到的测试准确性。那么我们显然应该使用Prompt A部署我们的LLM,对吗?不要那么快!
当我们评估每个提示的干净测试准确性时,我们发现Prompt B实际上比Prompt A好得多(4.5个百分点)。由于干净测试准确性更接近我们实际关心的真实性能,如果我们仅依赖于原始测试数据而不检查其标签质量,则会做出错误的决策!

这只是统计波动吗?
McNemar’s测试是评估ML准确性报告差异的一种推荐方法。当我们将此测试应用于评估700个文本示例中Prompt A与B之间的Clean Test Accuracy差异为4.5%时,差异具有高度统计意义(p值= 0.007,X² = 7.086)。因此,所有证据表明Prompt B是更好的选择 – 我们不应该因为精心审核原始测试数据而未能选择它!
这只是这两个提示的偶然结果吗?
让我们看看其他类型的提示,以查看结果是否仅是我们一对思考链提示的巧合。
指令提示
此类提示仅向LLM提供有关提供的文本示例应该执行的操作的指令。考虑我们可能需要在两者之间选择的下面一对提示。

Few-Shot提示
此类提示使用两个指令,一个前缀和一个后缀,并且还包括两个(预选)文本语料库示例,以向LLM提供所需输入输出映射的清晰演示。考虑我们可能需要在两者之间选择的下面一对提示。
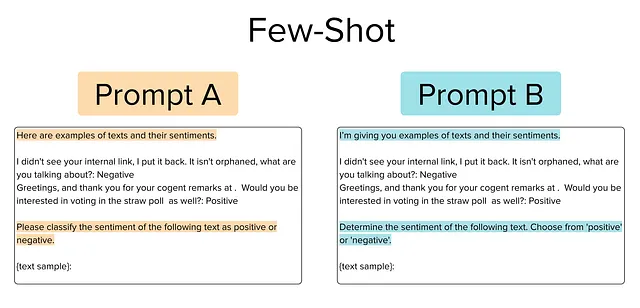
模板提示
此类提示使用两个指令,一个可选前缀和一个后缀,以及多项选择格式,以便模型将分类作为多项选择答案而不是直接响应预测类。考虑我们可能需要在两者之间选择的下面一对提示。

各种提示的结果
除了思考链外,我们还评估了使用这三种其他类型的提示相同FLAN-T5 LLM的分类性能。通过绘制下面所有这些提示所实现的观察测试准确性与Clean Test Accuracy之间的关系,我们可以看到许多对提示遇到了同样的问题,依靠观察测试准确性会导致选择实际上更差的提示。

仅基于观察测试准确性,您会倾向于在每种提示的“A”提示中选择“B”提示。但是,每种提示的更好提示实际上是Prompt B(其具有更高的Clean Test Accuracy)。每个提示对显示了验证测试数据质量的需求,否则,由于诸如嘈杂的注释之类的数据问题,您可能会做出次优决策。
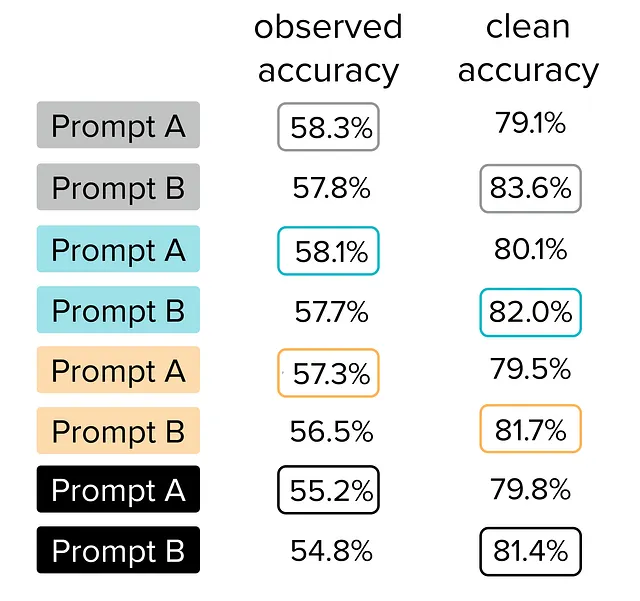
您还可以从这张图中看到,所有A提示的观察准确率都被圈起来,这意味着它们比它们的B对应项具有更高的准确性。同样,所有B提示的净准确率都被圈起来,这意味着它们比它们的B对应项具有更高的准确性。就像本文开头的简单示例一样,您倾向于选择所有A提示,但实际上B提示做得更好。
提高可用测试数据以获得更可靠的评估
希望您清楚地了解高质量评估数据的重要性。让我们看看您可以修复可用测试数据的几种方法。
手动更正
确保测试数据质量的最简单方法是手动审核!确保查看每个示例以验证其是否正确标记。根据您的测试集大小,这可能可行,也可能不可行。如果您的测试集相对较小(约100个示例),您可以查看它们并进行必要的更正。如果您的测试集很大(1000个以上的示例),这将是太耗时和精力的,不能手动完成。我们的测试集非常大,因此我们不会使用这种方法!
算法更正
评估您可用的(可能有噪声的)测试集的另一种方法是使用数据中心的AI算法,以诊断可以修复的问题,以获得同一数据集的更可靠版本(而无需收集许多额外的人类注释)。在这里,我们使用自信学习算法(通过开源cleanlab软件包)检查我们的测试数据,该算法自动估计哪些示例可能被错误标记。然后,我们只检查这些自动检测到的标签问题,并根据需要修复其标签,以生成我们测试数据集的更高质量版本。我们称基于此版本的测试数据集进行的模型准确性测量为CL测试准确性。
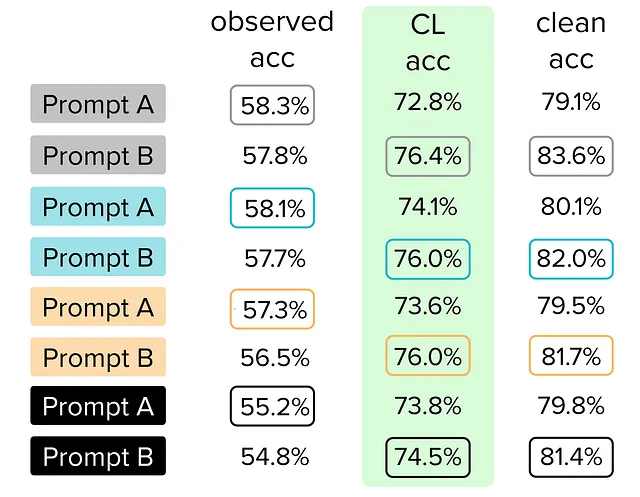
使用这个新的CL更正测试集进行模型评估,我们看到之前的所有B提示现在都正确地显示出比它们的A对应项更高的准确性。这意味着我们可以信任基于CL更正测试集做出的决策比基于嘈杂的原始测试数据做出的决策更可靠。
当然,自信学习算法不能神奇地识别任何数据集中的所有错误。此算法检测标签错误的效果将取决于从基线ML模型获得合理预测,即使如此,某些类型的系统性错误仍将无法检测到(例如,如果我们完全交换两个类的定义)。有关自信学习可以被证明有效的数学假设的详细列表,请参阅Northcutt等人的原始论文。对于许多现实世界的文本/图像/音频/表格数据集,该算法似乎至少提供了一种有效的方式,可以将有限的数据审查资源集中在大型数据集中潜伏的最可疑的示例上。
您不总是需要花费时间/资源来策划“完美”的评估集-使用像自信学习这样的算法来诊断和纠正可用测试集中的可能问题,可以提供高质量的数据,以确保选择最佳提示和模型。
除非另有说明,否则所有图片均为作者所拍摄。