选择正确的模型:流失模型 vs. 提升模型
我们真的需要流失模型吗?也许提升建模可以给我们更全面的答案?
假设我们在电子商务领域工作,产品经理找到我们,要求我们构建流失模型。
但实际上他要求我们什么呢?
流失模型能给我们什么?
好吧,这完全是关于了解特定客户离开我们的可能性。我们的下一步是由启发式推动的:
如果我们向可能流失的客户提供折扣,那么他们将会留下。
然而,我们的目标有点不同。假设我们只能做两件事:给待遇或不给待遇,在我们的情况下这将是折扣。有4种可能的结果。

- 利润损失。我们提供了折扣,用户使用了它并购买了物品,但用户即使没有折扣也会进行购买。这是一个负面的结果,因为利润已经被消耗。
- 待遇成本。我们提供了折扣,但用户没有使用它,也没有进行任何购买。这也被认为是一个负面的结果,因为我们会为待遇(例如发送短信)的成本付出代价,特别是在处理大量用户时。
- 成功。我们提供了折扣,用户使用了它,并仅仅因为此优惠而购买了物品。这是我们所追求的期望结果。
- 失去的客户。我们提供了折扣,但用户最终离开了我们。例如,在订阅服务的情况下,用户收到了一个折扣通知,只是意识到他们已经支付了过去6个月的订阅费用,并决定取消。这是我们可能遭遇的最负面的结果。
我们真正的目标不是估计流失的概率,而是要为每个用户应用最合适的待遇。
我们如何开始实现这个目标呢?
首先,进行简单的AB测试至关重要。这涉及为一个组提供折扣,同时保持另一个对照组没有任何折扣。
实验后,我们有三种主要方法。
双模型方法
第一种方法是构建两个单独的模型:一个用于对照组(没有任何折扣),另一个用于治疗组(有折扣)。为了构建这些单独的模型,我们可以选择任何类型的ML模型。
通过运行每个客户通过两个模型,我们可以计算提升作为预测结果之间的差异。
优点:
- 易于实现。
缺点:
- 它不直接预测提升。我们估计用户行动(购买)的概率。
- 双模型设置引入了双重错误建模,因为两个模型都有自己的错误,导致总体错误更大。
目标转换
第二种方法是围绕转换目标变量本身展开的。通过创建一个代表提升的新目标,我们可以直接计算所需的结果。
我们使用以下公式引入一个新的目标变量:
这里,Y代表原始目标变量,而W表示是否应用目标待遇。换句话说,Y代表是否给予折扣,W表示是否进行了购买。
转化变量Z在两种情况下取值为1:
- 用户属于目标组(W = 1)且Y = 1(向用户提供了折扣并且用户已经购买)。
- 用户属于对照组(W = 0)且Y = 0(未向用户提供折扣且用户未购买)。
然后我们只需要使用一个新的目标来训练模型(例如逻辑回归)。
要计算提升,我们可以使用以下公式:
优点:
- 仍然很容易实现。
- 由于只有一个模型,因此比第一种方法更健壮和稳定。
缺点:
- 仍然不能直接预测提升。我们预测的是转化变量。
基于树的模型
第三种方法利用基于树的模型。
目标是在数据集中识别对治疗最敏感的亚群体,从而实现有针对性的干预以达到最大的影响。
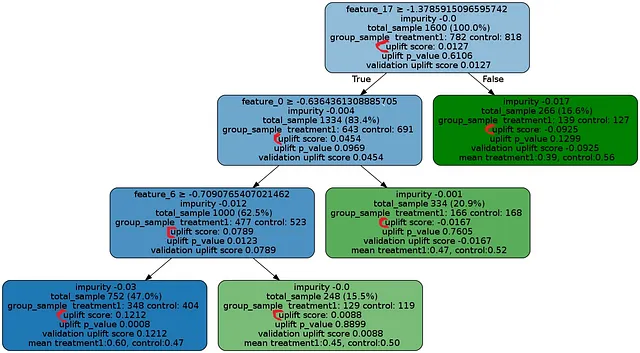
上面的高亮图像中显示了用于提升目的的示例决策树。红色表示提升值。观察图片,我们可以得出总提升差为0.0127(基于随机指标)。然而,当我们深入到树中时,我们可以观察到某些亚群体表现出更高的提升差异。
这些亚群体成为我们的目标,因为它们具有最大的潜在收益。
如何构建这棵树?
有许多教程可用于构建决策树,但在这里,我将概述基本方法。
- 选择特征并确定目标变量,即我们的情况下的提升。
- 选择一个分割标准来确定如何分割节点。
- 通过递归重复分割过程来构建树,直到满足停止标准为止。
值得注意的是,有三种常用的分割准则用于构建提升树,按受欢迎程度排序如下:
- KL散度
- 卡方
- 欧几里得距离
优点:
- 最准确的方法之一
- 我们有一棵决策树,因此我们可以构建树的森林和不同的集合,从而提高准确性并减少方差。
缺点:
- 它是一种决策树方法,因此算法倾向于高估具有许多级别的分类变量。为了解决这个问题,我们可以使用均值插补。
结论
现在我们知道,解决客户流失问题需要超出估计流失概率的策略。最终目标是为每个用户应用最适当的治疗方法,并提供业务影响而不是流失概率。
提升建模可以应用于超出客户流失之外的各种业务挑战,并提供具有即时业务影响的强大解决方案。
关于提升建模还有许多有趣的问题,例如如何处理多个治疗方法、估计不同的提升模型以及利用多臂老虎机进行生产,但我会在下一篇文章中回答。