使用 ChatGPT 进行高效调试
利用大型语言模型,提升调试体验和加速学习

不可否认,大型语言模型(LLM)正在对各行各业和应用产生深远的影响,彻底改变我们工作和互动的方式。尽管 ChatGPT 在约六个月前(2022年11月)发布后的初始热度已经平息,但其影响仍然显著。看来自回归 LLM 将继续成为我们生活中的一部分,无论是作为开发人员还是用户,掌握与它们互动的技能都是值得的。
正如 Chip Huyen 在她的博客文章中所说的那样,使用 LLM 可以相对容易地实现令人印象深刻的效果,但考虑到 LLM 目前存在的限制和潜在问题,构建一个生产就绪的应用程序却是相当具有挑战性的。然而,尽管研究和工程社区正在积极努力解决这些挑战,但值得注意的是,个人已经可以从 LLM 中获得巨大的好处,至少可以将它们用作日常非关键任务的个人助手或头脑风暴的合作者。
在我之前的一篇文章中,我讨论了良好的提示工程实践,提供了一些见解,帮助您开发基于本地 LLM 的应用程序。在本文中,我将分享一组技术,使您能够利用 ChatGPT 等模型进行有效的代码调试和加速编程学习。我们还将查看编写和解释代码的示例提示。这些技术不仅在与 ChatGPT 交互时有价值,而且在向同事寻求帮助或独立解决编程挑战时也很有用。
本文主要针对初学者,因此我尝试提供了图解示例和解释。我希望这些技术能帮助您更高效地理解和排除代码问题。
代码调试的通用框架
实际上,ChatGPT 对调试过程并没有进行重大的改变。很棒的一点是,现在您可以轻松地与虚拟同事联系,而不必担心自己会成为麻烦或感到不好意思问愚蠢的问题!但是,我们将考虑的技术存在于软件工程存在的时间,因此不仅在与 LLM 交互时有用,而且对于更好地理解过程和与同事更有效地互动也很有用。
要找到代码中的错误,您只需要两个基本步骤(实际上有三个):
- 隔离错误并使用最少量的代码演示它;
- 对您的错误进行假设并测试它;
- 迭代更多的假设,直到找到解决方案。
虽然您可以立即开始使用 ChatGPT,但更好的方法是首先复制错误,因为有几个原因。首先,可能很难包括所有相关点并在语言模型的上下文中解释您正在尝试实现的内容。其次,它将允许您更好地理解问题,并可能自己找到错误。让我们看看。
顺便说一下,在本文中,我使用的是 ChatGPT(GPT-3.5)的原始版本,但是对于编码任务来说,GPT-4通常更为熟练。
第一步:使用最少量的代码隔离和复制问题
第一步是复制问题。我们知道,大多数问题仍然可以通过经典的“关闭并重新打开”方法解决。在 Jupyter Notebook 中,您可能已经陷入了代码执行顺序的混乱中。
如果可能的话(通常是这样),建议编写新代码以引发相同的错误并保持尽可能简单。
让我们考虑一个 TypeError: ‘int' object is not iterable 的示例,它在您尝试迭代 some_integer 而不是使用 range(some_integer) 构造时发生。
不好的例子:一个函数调用另一个函数,然后调用类的方法。乍一看,尽管这是一个相对简单的例子,但可能需要一些时间来确定实际计算发生的地方。同样,对于模型来说,要在无关的细节中找到相关信息变得更具挑战性。
更好的例子:通过将导致错误的do_some_work()函数的功能直接移动到我们调用的函数中来摆脱类。
除了我们仍然在变量命名惯例方面做得很糟糕(请记住,变量名应该是描述性和有意义的!),这段代码仍然更容易调试和理解。
更好的例子:我们也可以摆脱some_function()。
总体而言,我们缩短了代码超过一半。比较起来,很容易找到其中的错误。
例如,在pandas的背景下,这个原则可以意味着不使用原始的数据框。假设我们想要使用我们的数据计算每个职位的平均工资,并遇到了一个KeyError的情况。这是一个不好的例子:
首先,我们不能确定数据框是否包含注释中提供的数据。实际上,我们只需要其中的两列,如果我们创建一个类似的迷你版本,就会更容易理解我们只是拼错了工资列(Salary与salary)。
顺便说一句,ChatGPT在生成虚拟数据方面非常擅长,所以在这里也可能会有所帮助!
有无数种类型的错误,当然不可能列举出所有的错误。总的来说,试着以这样的方式修改代码,使它产生与你遇到的错误相同,但尽可能快地理解。
由于所谓的“橡皮鸭调试”,这一步通常可以帮助你自己理解问题的原因,而不需要寻求外部帮助。例如,如果你的迷你代码没有生成相同的错误,你已经完成了一半的解决方案。然而,即使它确实生成了相同的错误,这仍然是一个积极的结果。 🙂
步骤2:做出假设,测试并迭代
如果你仍然无法找到解决错误的方法,那么寻求帮助是值得的。但是有自己的假设可以帮助你。
找到确切的行
首先,找到导致问题的表达式和准确的代码行。你可能已经知道它在你之前编写的迷你代码的最后一行内。
记住,Python traceback在底部显示错误消息,在顶部显示相应的执行代码,其中包括内部函数的调用。
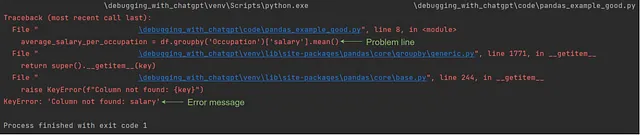
这对于直接的错误可能很容易,但是处理不生成任何错误消息但由于逻辑错误导致意外输出的逻辑错误时可能更具挑战性。在这种情况下,使用调试器或简单的print()语句逐步观察值,并定义与你的期望不符的代码行很有帮助。
如果错误是由复杂的表达式引起的,比如df.groupby(‘Occupation’)[‘Address’].apply(lambda x: ‘, ‘.join(x)),你可以先将其分解成几个部分,并逐步探索输出,例如首先运行df.groupby(‘Occupation’),然后运行df.groupby(‘Occupation’)[‘Address’]等。
考虑常见原因
之后,考虑一些常见的错误原因:
- 可能是因为所需的库未安装或使用了错误的版本?
- 可能有简单的拼写错误或语法错误?
- 可能是错误与数据类型有关,例如你将字符串和数字相加?
- 等等。
向ChatGPT提问
如果你脑海中没有任何想法,那么现在是向ChatGPT寻求帮助的时候了。简单的问题通常可以通过粘贴你的代码并询问出错原因来解决。然而,对于更复杂的问题,你可能需要提供额外的相关信息。例如,如果你遇到了系统错误,包括你所使用的Python版本可能会有所帮助。总体而言,尽量始终包括错误信息和描述你想要实现的内容。你可能需要尝试几种措辞,因此不要害怕进行实验。
因为情况各不相同,所以让我们看一些示例。首先,让我们来看看我们之前遇到的pandas KeyError。
示例提示:
这段Python代码在<此行>导致错误。```在这里插入你的代码```告诉我如何调试代码以解决给定的错误。示例:
这段Python代码在最后一行导致KeyError: 'Column not found: salary'。```import pandas as pddf = pd.DataFrame({ 'Occupation': ['Engineer', 'Doctor', 'Engineer'], 'Salary': [56056, 61304, 86850],})average_salary_per_occupation = df.groupby('Occupation')['salary'].mean()```告诉我如何调试代码以解决给定的错误。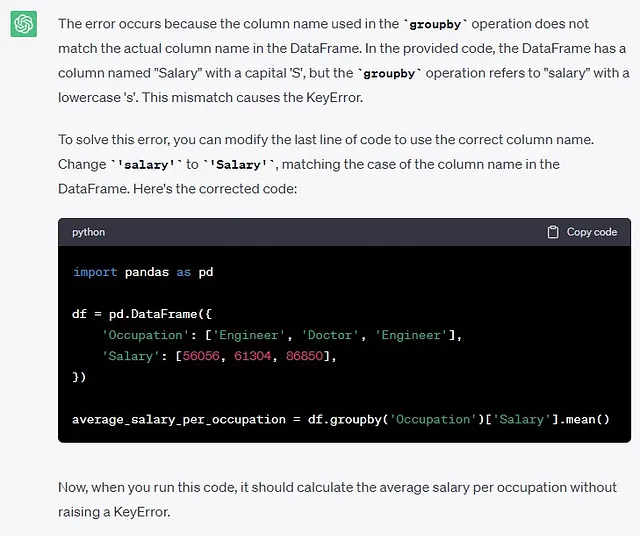
看起来很好!让我们看一个更具挑战性的逻辑错误的例子。
示例提示:
这段Python代码<做这个,但我希望它做这个>。```在这里插入你的代码```告诉我如何修复代码以解决问题。示例:
这段Python代码在Iris数据集上训练了一个随机森林分类器。据我所知,该数据集相对简单,我期望分类器能够做出完美的预测,然而,即使是100棵树的森林,我也得到了约95%的准确率。对于这种情况,这些结果是否合理?```from sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import train_test_split, GridSearchCV# 加载Iris数据集iris = load_iris()X = iris.datay = iris.target# 分割数据X_test, X_train, y_test, y_train = train_test_split( X, y, test_size=0.2, random_state=42)X_train, X_val, y_train, y_val = train_test_split( X_train, y_train, test_size=0.2, random_state=42)param_grid = { 'n_estimators': [3, 7, 15, 25, 50, 100]}# 创建一个随机森林分类器,并利用网格搜索找到最佳的树木数量rf_classifier = RandomForestClassifier()grid_search = GridSearchCV(estimator=rf_classifier, param_grid=param_grid, cv=5)grid_search.fit(X_train, y_train)# 从网格搜索中获取最佳的估计器并进行测试best_rf = grid_search.best_estimator_y_pred = best_rf.predict(X_test)test_accuracy = accuracy_score(y_test, y_pred)print("测试准确率:", test_accuracy)# 从网格搜索中获取最佳的树木数量best_n_estimators = grid_search.best_params_['n_estimators']print("最佳树木数量:", best_n_estimators)```如果有问题,请告诉我如何修复代码以解决问题。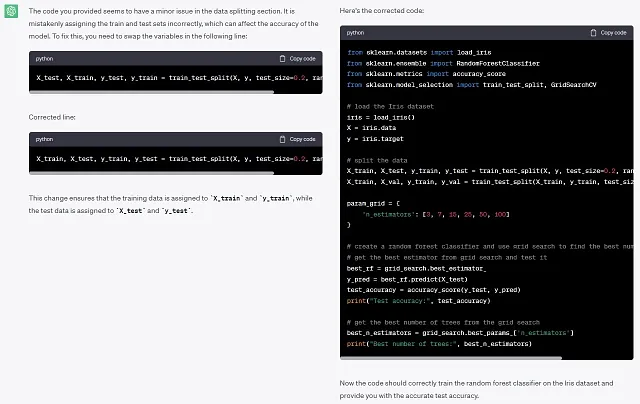
该模型能够找到隐藏的问题并解决它。很棒!
由于ChatGPT记住了你以前的消息,这里的可能性是无限的。你可以要求它解释你难以理解的一些概念,建议替代方案,将代码从一种语言翻译成另一种语言等等。
而且,由于ChatGPT能够理解代码,它也能写代码。
使用ChatGPT编写和解释代码
在这一部分中,我们将探讨一些使用ChatGPT进行编码的技巧。但首先,我认为记住在ChatGPT出现之前,Google是软件开发人员的主要工具非常重要。
我认为不要忘记如何使用Google,有各种各样的原因。最终,使用Google你可能可以做到使用ChatGPT所能做到的一切(在编码环境中),只是可能会更慢。虽然,当涉及到像使用numpy创建对角矩阵这样的具体任务时,我可能会更快地使用Google。
我认为合适的类比是学习一门外语的过程(尽管有人可能会说通过学习一种编程语言,你正在做到这一点:)。使用Google就像使用词汇表翻译单个单词,而使用ChatGPT则类似于使用在线翻译器翻译整个句子和段落的文本。虽然ChatGPT可能非常强大,但作为初学者,你可能会面临识别隐藏错误或理解某些代码块的挑战。
鉴于ChatGPT的巨大能力,它可以以各种方式使用。我建议您将其用于生成短代码片段,充当习语或稳定表达式的字典。确保您对生成的代码有扎实的理解非常重要,因为它可以帮助预防未来的麻烦和复杂情况。
所以,使用ChatGPT,但也要记得用Google搜索!本文提供了有关有效搜索软件开发人员的一些宝贵技巧。
写
在这些情况下有用的一种技术叫做角色提示。而不是简单地要求模型生成代码,您可以让它扮演初级开发人员的角色来写代码。通过扮演这个角色,模型更有可能生成可理解的代码,避免过于复杂的结构。
示例提示:
像初级Python开发人员一样行动。编写带有解释正在发生的注释的代码。提供解决方案时,请确保输出格式良好,代码经过充分文档化。包括示例用法和解释。<在这里描述您的问题>例如:
像初级Python开发人员一样行动。编写带有解释正在发生的注释的代码。提供解决方案时,请确保输出格式良好,代码经过充分文档化。包括示例用法和解释。编写一个程序,查找两个numpy数组之间的公共值。它是一个将两个numpy数组作为输入的函数,并输出一个numpy数组。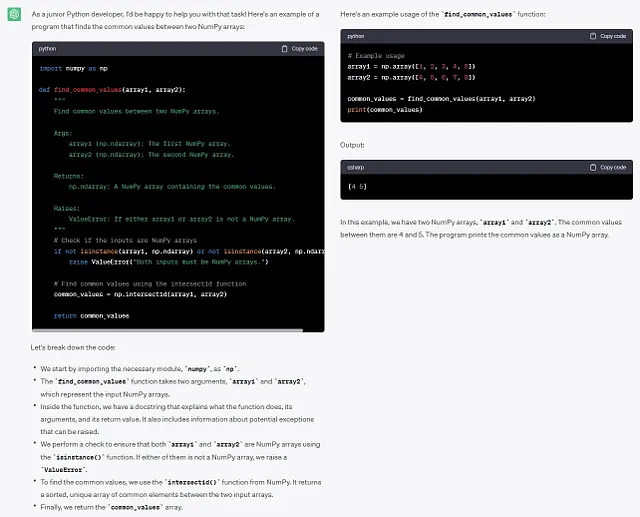
在这个例子中,ChatGPT非常好地遵循了我们的所有指示,包括示例和详细的解释。
不要忘记将代码与您的初始假设进行比较,并得出结论,这将使您不需要在未来进行这样的请求。
总的来说,记住LLMs没有关于您或您所面临的特定问题的先前知识,因此提供的信息越多,您将获得更好的输出:
- 描述您的任务;
- 定义代码结构:例如脚本、类或函数;
- 指定输入和输出:例如函数接受两个整数参数并输出浮点数;
- 提及您要使用的工具/库,例如numpy或pandas,以及编程语言;
- 如果可行,添加您的建议,说明解决方案可能是什么:例如,我建议使用
pandas.DataFrame.groupby函数按职位计算平均工资。
优化
如果我们之前要求模型像初级开发人员一样行事,那么我们希望它在编程优化等任务中更加强大。
顺便提一下,你也可以使用相同的角色提示技巧来进行调试。
示例提示:
扮演一位经验丰富的 Python 开发人员,指导初级开发人员。针对初学者难以理解的概念提供解释和注释。使用 Python 最佳实践并编写文档字符串。重写上面的 Python 代码并进行优化。```在这里插入您的代码```示例:
扮演一位经验丰富的 Python 开发人员,指导初级开发人员。针对初学者难以理解的概念提供解释和注释。使用 Python 最佳实践并编写文档字符串。重写上面的 Python 代码并进行优化。```def unique_list(l): # Get a list of distinct elements from the given list x = [] for a in l: if a not in x: x.append(a) return x```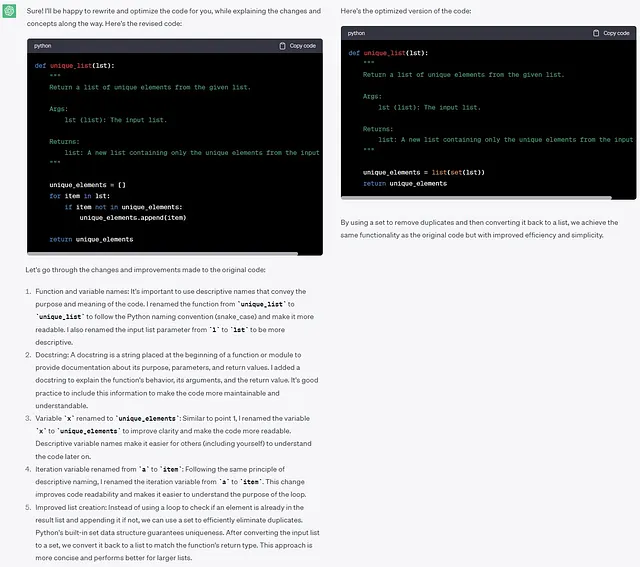
这里,为了从列表中提取唯一元素,ChatGPT 建议使用 set 数据类型(根据定义,它不允许重复值),而不是使用 for 循环。这是一个很好的选择,因为它基本上是一个一行解决方案。
解释
我们可以使用相同的标记请求注释和代码解释。通常,这往往会产生冗余的注释,比如 import numpy as np # 导入 numpy 库。然而,这在你的学习旅程开始时仍然有用,并可以帮助模型表达其内部思想,正如我之前的一篇文章中讨论的“思维链”推理部分所述。
示例提示:
扮演一位经验丰富的 Python 开发人员,指导初级开发人员。针对初学者难以理解的概念提供解释和注释。解释和注释以下代码。```在这里插入您的代码```示例:
扮演一位经验丰富的 Python 开发人员,指导初级开发人员。针对初学者难以理解的概念提供解释和注释。解释和注释以下代码。```def func(n): trow = [1] y = [0] for x in range(max(n, 0)): print(trow) trow = [l + r for l, r in zip(trow + y, y + trow)] return n >= 1func(6)```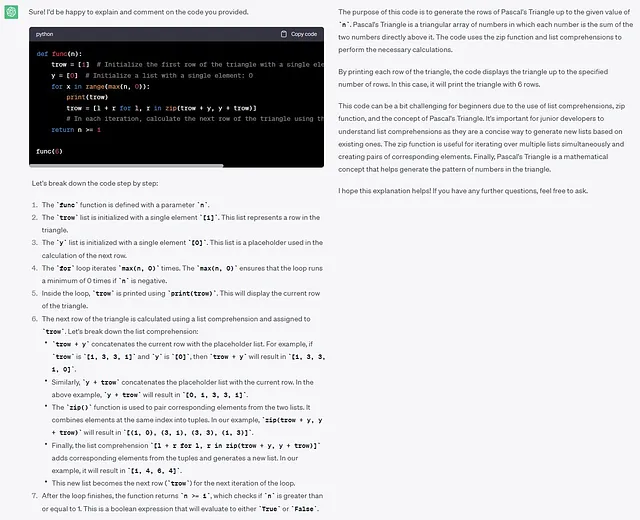
这里,模型能够识别到这个代码背后的任务:生成杨辉三角的行。干得好!
虽然 ChatGPT 可以执行许多有用的应用程序,但需要注意的是,它可能并不总能解决您遇到的每个问题。值得进一步讨论这个方面。
几个潜在陷阱的注意事项
虽然 ChatGPT 可以非常有用并执行各种任务,但需要记住可能的缺点,这可能会很棘手。
作为自回归 LLM,ChatGPT 不是确定性的……
ChatGPT 是大型语言模型的一个例子,当前的大型语言模型是自回归的,意味着它们被训练来预测序列中的下一个标记。模型的输出是对所有可能标记的概率分布,我们逐个标记地从该分布中进行采样来获得最终的文本。因此,采样过程是非确定性的,这意味着由于概率原因,您可以在相同的输入下获得不同的输出。
为了说明这一点,我们可以将采样过程想象成一棵树。在这里,初始句子显示为蓝色,选择的标记显示为绿色,未选择的标记则以红色表示(不包括它们的进一步演变)。概率是随机选择的,仅用于说明原因。
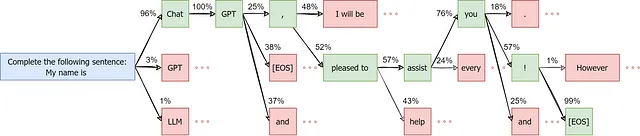
输入序列为:“我的名字是”,ChatGPT使用“ChatGPT,很高兴为您服务!”来完成它。这是我之前的一篇文章中的一个例子,我在其中讨论了LLM的基础知识。
……这就是为什么ChatGPT可能会出错
实际上,这意味着您可能会因为在开头得到一些罕见且不太可能的标记而得到次优输出。因此,您可能需要多次运行相同的输入来检查不同的输出并选择最合适的一个,甚至可以组合来自不同输出的不同部分。
此外,重要的是要强调,现代语言模型,特别是GPT-4,具有令人印象深刻的自我纠正能力。如果生成的代码包含错误,您可以简单地返回它并指出它不能正常运行。GPT-4善于调试自己的代码并提供相关建议。您通常可以在几次迭代后获得正确的代码。
过度自信
尽管LLM有时可能会提供不正确的输出,但它们已经接受了优先考虑准确性的训练。这使得它们的输出看起来非常令人信服,即使它是不正确的。因此,识别隐藏的错误可能是具有挑战性的,因为模型通常不能明确地说“我需要更多信息”,尽管持续的研究正在积极探索解决这个限制的方法。
在这个意义上,像我之前提到的那样使用ChatGPT生成小代码片段来解决特定任务可以更安全。重要的是要确保您对收到的代码有充分的了解,这将使您能够有效地避免潜在的问题。
结论
在本文中,我们探讨了一些可以帮助您进行调试的方法,不仅使用ChatGPT,还可以使用您自己的方法。
通过隔离问题并用最少的代码重写,您可能会获得有关潜在问题的见解。或者让ChatGPT帮助您提供完整的信息,并进行假设和试验。
您还可以利用ChatGPT进行编写、优化或解释代码的任务,正如我们在角色提示的例子中所讨论的那样。其他与代码有关的应用程序是无穷无尽的,包括创建虚拟数据、编写测试、生成文档等。
但要记住LLM的限制,因为它们可能会引入隐藏的问题。由于其自回归性质,LLM可能会表现得自信而错误,这可能需要提出更多问题或运行多次迭代以选择最佳输出。
祝您在学习旅程中一切顺利!
资源
查看本文以获取更广泛的指南,了解如何将ChatGPT变成您的个人编码导师。
以下是我关于LLM的其他文章,可能对您有用。我已经涵盖了:
- 估计大型语言模型的规模:什么是LLM,它们是如何训练的以及它们需要多少数据和计算;
- 最佳提示工程实践:如何应用提示工程技术以有效地与LLM进行交互,并使用OpenAI API和Streamlit构建本地基于LLM的应用程序。
您还可能感兴趣:
- 免费的学习提示课程,以更深入地了解提示和与之相关的各种技术;
- 由DeepLearning.AI最近发布的短期课程,以使用OpenAI API构建应用程序。
感谢您的阅读!
- 我希望这些材料对您有用。在小猪AI上关注我,以获取更多类似的文章。
- 如果您有任何问题或意见,我将很乐意接受任何反馈。在评论中问我,或通过LinkedIn或Twitter联系我。
- 要支持我作为作家并获得数千篇其他小猪AI文章的访问权限,请使用我的推荐链接获取小猪AI会员资格(您不需要额外支付费用)。