GPT 与 BERT:哪个更好?
比较两个大型语言模型:方法和示例

生成式人工智能的普及也导致了大型语言模型数量的增加。在这篇文章中,我将比较其中的两个:GPT和BERT。GPT (Generative Pre-trained Transformer) 是由OpenAI开发的,基于仅解码器的架构。另一方面,BERT (Bidirectional Encoder Representations from Transformers) 是由Google开发的,是一个仅编码器的预训练模型。
两者在技术上有所不同,但它们有一个相似的目标——执行自然语言处理任务。许多文章从技术角度比较这两个模型。然而,在这篇文章中,我将基于它们的目标质量进行比较,即自然语言处理。
比较方法
如何比较两个完全不同的技术架构?GPT是仅解码器的架构,BERT是仅编码器的架构。因此,解码器与编码器之间的技术比较就像比较法拉利和兰博基尼一样——两者都很棒,但底盘下的技术完全不同。
然而,我们可以基于两者都能执行的共同自然语言任务的质量进行比较——即嵌入的生成。嵌入是文本的向量表示。嵌入形成了任何自然语言处理任务的基础,因此,如果我们可以比较嵌入的质量,那么它可以帮助我们判断自然语言处理的质量,因为嵌入是基于transformer架构的自然语言处理的基础。
下面是我将采取的比较方法。
让我们从GPT开始
我掷了一枚硬币,GPT赢了!所以让我们先从GPT开始。我将使用亚马逊精选食品评论数据集中的文本进行测试。评论是测试两个模型的好方法,因为评论用自然语言表达并且非常自发。它们包含顾客的感受,并且可以包含所有类型的语言——好的,坏的,丑陋的!此外,它们可能有许多拼写错误的单词、表情符号以及常用俚语。
这是评论文本的一个示例。

为了使用GPT获取文本的嵌入,我们需要对OpenAI进行API调用。结果是每个文本的大小为1540的嵌入或向量。这里是包括嵌入的示例数据。

下一步是聚类和可视化。可以使用KMeans对嵌入向量进行聚类,使用TSNE将1540维降至2维。下面是聚类和降维后的结果。
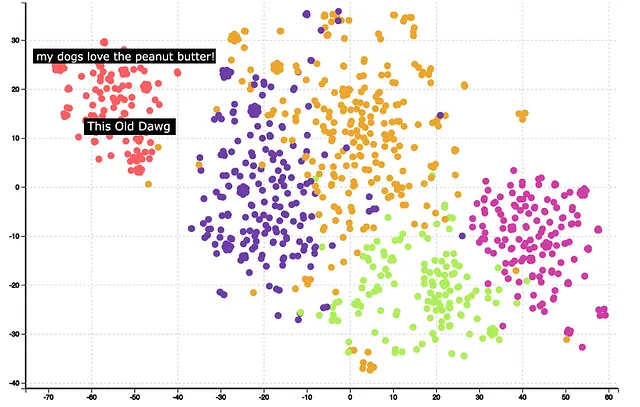
可以观察到聚类非常明显。悬停在某些聚类上可以帮助理解聚类的含义。例如,红色聚类与狗粮有关。进一步分析还表明,GPT嵌入正确地识别了单词’Dog’和’Dawg’的相似性,并将它们放置在同一个聚类中。
总的来说,从聚类的质量可以看出,GPT嵌入提供了良好的结果。
BERT的表现
BERT能表现得更好吗?让我们来看看。BERT模型有多个版本,例如bert-base-case、bert-base-uncased等。它们的嵌入向量大小不同。这里是基于具有768个嵌入大小的Bert base的结果。
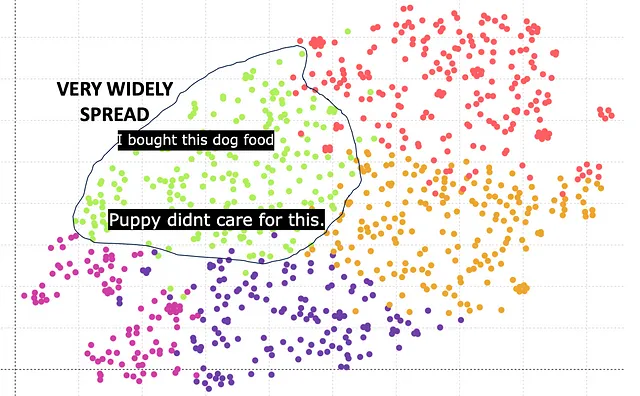
绿色聚类对应于狗粮。然而,可以观察到聚类散布得很广,与GPT相比不够紧凑。主要原因是768的嵌入向量长度较差,与GPT的1540的嵌入向量长度相比不足。
幸运的是,BERT还提供了更高的嵌入大小1024。这里是结果。
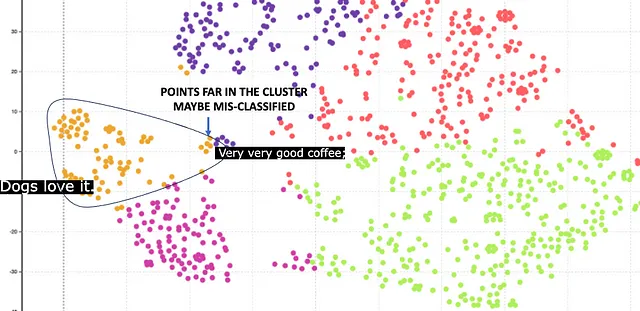
这里橙色聚类对应于狗粮。该聚类相对紧凑,与768的嵌入相比是更好的结果。但是,有一些点距离中心很远。这些点被错误分类。例如,有一篇关于咖啡的评论,但由于其中有一个单词Dog,因此被错误分类为狗粮。
结论
显然,GPT比BERT表现更好,并提供了更高质量的嵌入。但是,我不想把所有功劳归功于GPT,因为比较还有其他方面。这里是一个总结表格

从提供更高嵌入大小的嵌入质量来看,GPT胜过BERT。然而,GPT需要付费API,而BERT是免费的。此外,BERT模型是开源的,不是黑盒,因此您可以进行进一步的分析以更好地了解它。来自OpenAI的GPT模型是黑盒。
总之,我建议对于像网页或书籍这样的小猪AI复杂文本,使用BERT。对于完全使用自然语言且未经筛选的客户评论之类的非常复杂的文本,可以使用GPT。
技术实现
这里是一个Python代码片段,实现了故事中描述的过程。为了说明,我给出了GPT的示例。BERT的实现方式类似。
##导入包import openaiimport pandas as pdimport reimport contextlibimport ioimport tiktokenfrom openai.embeddings_utils import get_embeddingfrom sklearn.cluster import KMeansfrom sklearn.manifold import TSNE##读取数据file_name = 'path_to_file'df = pd.read_csv(file_name)##设置参数embedding_model = "text-embedding-ada-002"embedding_encoding = "cl100k_base" # 这是text-embedding-ada-002的编码max_tokens = 8000 # text-embedding-ada-002的最大值为8191top_n = 1000encoding = tiktoken.get_encoding(embedding_encoding)col_embedding = 'embedding'n_tsne=2n_iter = 1000##从OpenAI获取嵌入def get_embedding(text, model): openai.api_key = "YOUR_OPENAPI_KEY" text = text.replace("\n", " ") return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']col_txt = 'Review'df["n_tokens"] = df[col_txt].apply(lambda x: len(encoding.encode(x)))df = df[df.n_tokens <= max_tokens].tail(top_n)df = df[df.n_tokens > 0].reset_index(drop=True) ##如果没有标记,请删除,例如空白行df[col_embedding] = df[col_txt].apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))matrix = np.array(df[col_embedding].to_list())##进行聚类kmeans_model = KMeans(n_clusters=n_clusters,random_state=0)kmeans = kmeans_model.fit(matrix)kmeans_clusters = kmeans.predict(matrix)#TSNEtsne_model = TSNE(n_components=n_tsne, verbose=0, random_state=42, n_iter=n_iter,init='random')tsne_out = tsne_model.fit_transform(matrix)数据集引用
该数据集在此处提供,采用CC0公共领域许可证。商业和非商业用途均可。
亚马逊美食评论
分析来自亚马逊的约50万条美食评论
www.kaggle.com
请订阅以随时了解我发布的新故事。
每当Pranay Dave发布时收到电子邮件。
每当Pranay Dave发布时收到电子邮件。通过注册,如果您还没有,您将创建一个小猪AI账户…
pranay-dave9.medium.com
您也可以使用我的推荐链接加入小猪AI
使用我的推荐链接加入小猪AI – Pranay Dave
作为小猪AI会员,您的会员费的一部分将用于支付您所阅读的作家,您将获得完全访问所有故事的权限…
pranay-dave9.medium.com
其他资源
网站
您可以访问我的网站,以零编码进行分析。https://experiencedatascience.com
YouTube频道
请访问我的YouTube频道,了解使用演示进行数据科学和AI用例的方法
数据科学演示
通过演示学习数据科学。无论您从事何种职业,都可以坐下来,放松身心,享受视频。我的名字是…
www.youtube.com





