基于AWS的深度学习驾驶辅助系统的自动标注模块
在计算机视觉(CV)中,为了识别感兴趣的对象或定位对象而添加标签或边界框的过程被称为标注。这是为了准备训练数据以训练深度学习模型的先决任务之一。为了各种CV用例,从图像和视频中生成高质量的标签需要耗费数十万个工时。您可以使用Amazon SageMaker数据标注的两种方式来创建这些标签:
- Amazon SageMaker Ground Truth Plus – 这项服务提供了一个经过ML任务培训的专业团队,可以帮助满足您的数据安全、隐私和合规要求。您上传数据,Ground Truth Plus团队代表您创建和管理数据标注工作流和工作人员。
- Amazon SageMaker Ground Truth – 或者,您可以自行管理数据标注工作流和工作人员来标注数据。
具体而言,对于基于深度学习的自动驾驶(AV)和高级驾驶辅助系统(ADAS),需要从头开始标注复杂的多模态数据,包括同步的LiDAR、RADAR和多摄像头流。例如,下图显示了LiDAR数据中一个汽车的3D边界框以及侧面的正交LiDAR视图和七个不同的摄像头流,其中边界框的投影标签。
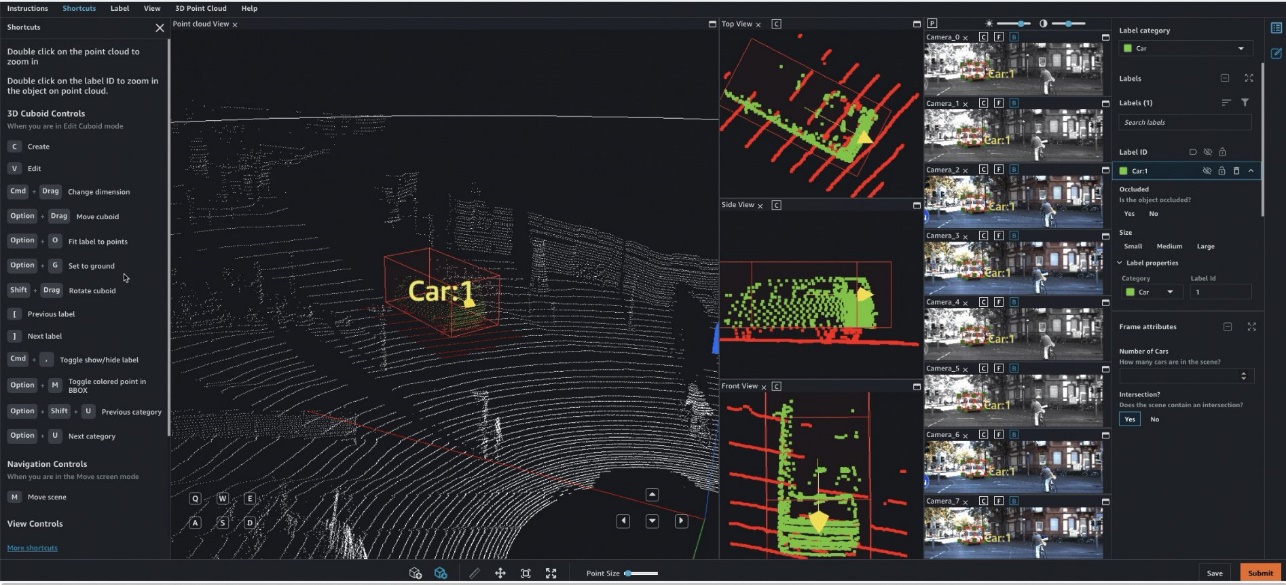
AV/ADAS团队需要从头标注数千帧,并依靠标签合并、自动校准、帧选择、帧序列插值和主动学习等技术来获得一个标注数据集。Ground Truth支持这些功能。有关功能的完整列表,请参阅Amazon SageMaker数据标注功能。然而,对于从事创建AV/ADAS系统业务的公司来说,为数万英里的录制视频和LiDAR数据进行标注可能是具有挑战性、昂贵且耗时的。目前用于解决这个问题的一种技术是自动标注,如下图所示的ADAS在AWS上的模块化功能设计中所突出显示的。

在本文中,我们将演示如何使用SageMaker的功能,如Amazon SageMaker JumpStart模型和异步推理能力,以及Ground Truth的功能来执行自动标注。
自动标注概述
自动标注(有时也称为预标注)发生在手动标注任务之前或同时进行。在该模块中,为特定任务(例如行人检测或车道分割)训练的最佳模型被用于生成高质量的标签。手动标注者只需验证或调整从结果数据集中自动生成的标签。这比从头标注这些大型数据集更容易、更快速和更便宜。下游模块,如训练或验证模块,可以直接使用这些标签。
主动学习是与自动标注密切相关的另一个概念。它是一种机器学习(ML)技术,用于确定应由您的工作人员标注的数据。Ground Truth的自动化数据标注功能就是主动学习的一个示例。当Ground Truth启动自动化数据标注作业时,它会选择一组随机样本的输入数据对象并将其发送给人工工作者。当标记数据返回时,它被用于创建一个训练集和一个验证集。Ground Truth使用这些数据集来训练和验证用于自动标注的模型。然后,Ground Truth运行批量转换作业来为未标记的数据生成标签,并为新数据生成置信度分数。置信度得分较低的标记数据会被发送给人工标注者。这个训练、验证和批量转换的过程会重复,直到整个数据集被标注。
相比之下,自动标注假设存在一个高质量的预训练模型(可以是公司内部的私有模型,也可以是公共的模型库)。该模型用于生成可信任并可用于下游任务(如标签验证任务、训练或模拟)的标签。在AV/ADAS系统的情况下,该预训练模型部署在车辆边缘,并可在云上进行大规模的批量推理作业以生成高质量的标签。
JumpStart提供了预训练的开源模型,用于各种问题类型的机器学习入门。您可以使用JumpStart在组织内共享模型。让我们开始吧!
解决方案概述
在本文中,我们概述了主要步骤,而没有详细介绍示例笔记本中的每个单元格。要跟随或自行尝试,请在Amazon SageMaker Studio中运行Jupyter笔记本。
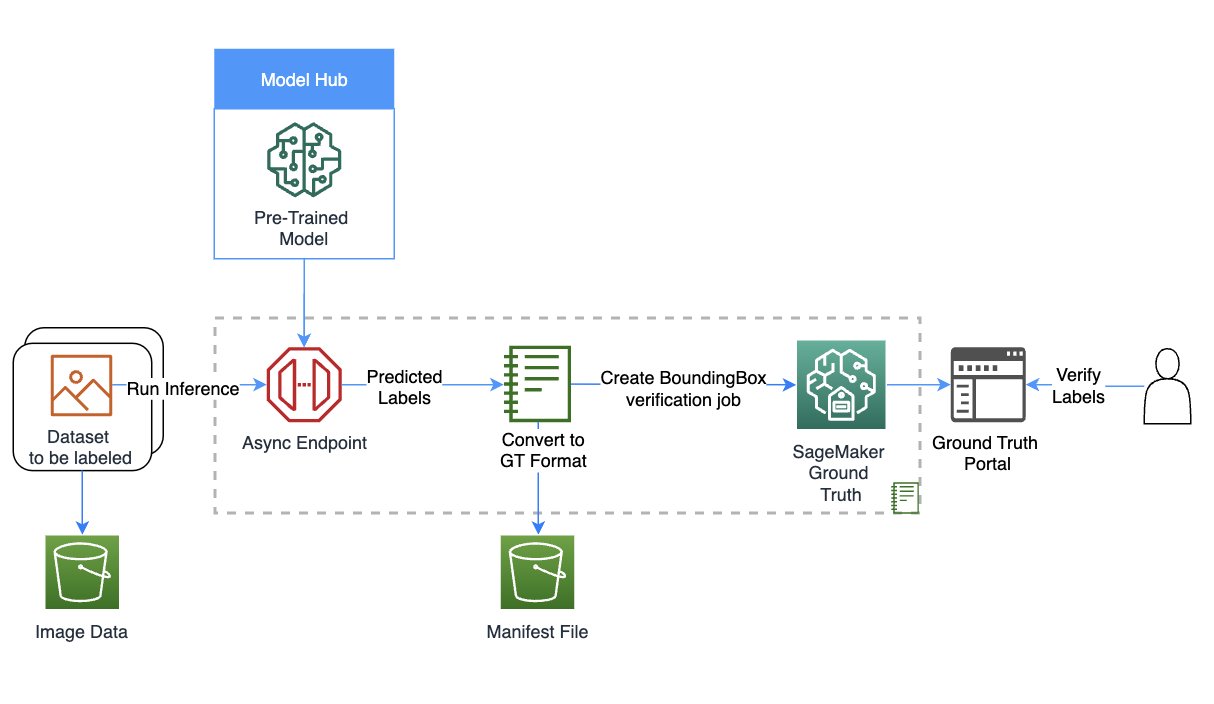
以下图表提供了解决方案概述。
设置角色和会话
在本示例中,我们在ml.m5.large实例类型的Studio中使用了Data Science 3.0内核。首先,我们进行了一些基本导入,并设置了稍后在笔记本中使用的角色和会话:
import sagemaker, boto3, json
from sagemaker import get_execution_role
from utils import *使用SageMaker创建模型
在此步骤中,我们为自动标注任务创建了一个模型。您可以从以下三个选项中选择创建模型:
- 从JumpStart创建模型 – 使用JumpStart,我们可以对预训练模型执行推理,即使没有在新数据集上对其进行微调
- 使用JumpStart与团队或组织共享的模型 – 如果您想使用组织内的团队之一开发的模型,可以使用此选项
- 使用现有终端节点 – 如果您的帐户中已经部署了现有模型,可以使用此选项
要使用第一个选项,我们从JumpStart中选择一个模型(这里,我们使用mxnet-is-mask-rcnn-fpn-resnet101-v1d-coco)。模型列表可在JumpStart提供的models_manifest.json文件中找到。
我们使用这个公开可用并在实例分割任务上进行训练的JumpStart模型,但您也可以自由地使用私有模型。在下面的代码中,我们使用image_uris、model_uris和script_uris来检索正确的参数值,以便在sagemaker.model.Model API中使用这个MXNet模型创建模型:
from sagemaker import image_uris, model_uris, script_uris, hyperparameters
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.utils import name_from_base
endpoint_name = name_from_base(f"jumpstart-example-infer-{model_id}")
inference_instance_type = "ml.p3.2xlarge"
# 检索推理docker容器uri
deploy_image_uri = image_uris.retrieve(
region=None,
framework=None, # 从model_id自动推断
image_scope="inference",
model_id=model_id,
model_version=model_version,
instance_type=inference_instance_type,
)
# 检索推理脚本uri。这包括模型加载、推理处理等脚本。
deploy_source_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="inference"
)
# 检索基础模型uri
base_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="inference"
)
# 创建SageMaker模型实例
model = Model(
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
model_data=base_model_uri,
entry_point="inference.py", # 在source_dir和deploy_source_uri中的入口点文件
role=aws_role,
predictor_cls=Predictor,
name=endpoint_name,
)设置异步推理和扩展
在部署模型之前,我们设置了一个异步推理配置。我们选择异步推理是因为它可以处理大的负载大小,并满足准实时的延迟要求。此外,您可以配置端点以自动扩展,并应用缩放策略将实例计数设置为零,当没有要处理的请求时。在下面的代码中,我们将max_concurrent_invocations_per_instance设置为4。我们还设置了自动扩展,这样在需要时端点可以扩展,并在自动标注作业完成后缩减到零。
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
async_config = AsyncInferenceConfig(
output_path=f"s3://{sess.default_bucket()}/asyncinference/output",
max_concurrent_invocations_per_instance=4)
.
.
.
response = client.put_scaling_policy(
PolicyName="Invocations-ScalingPolicy",
ServiceNamespace="sagemaker", # 提供资源的AWS服务的命名空间
ResourceId=resource_id, # 终端节点名称
ScalableDimension="sagemaker:variant:DesiredInstanceCount", # SageMaker仅支持Instance Count
PolicyType="TargetTrackingScaling", # 'StepScaling'|'TargetTrackingScaling'
TargetTrackingScalingPolicyConfiguration={
"TargetValue": 5.0, # 指标的目标值 - 在这里指标是SageMakerVariantInvocationsPerInstance
"CustomizedMetricSpecification": {
"MetricName": "ApproximateBacklogSizePerInstance",
"Namespace": "AWS/SageMaker",
"Dimensions": [{"Name": "EndpointName", "Value": endpoint_name}],
"Statistic": "Average",
},
"ScaleInCooldown": 300,
"ScaleOutCooldown": 300
},
)下载数据并进行推理
我们使用来自AWS开放数据目录的Ford Multi-AV Seasonal数据集。
首先,我们下载并准备用于推理的数据。我们在笔记本中提供了预处理步骤来处理数据集,你可以根据自己的数据集进行更改。然后,使用SageMaker API,我们可以启动异步推理作业,如下所示:
import glob
import time
max_images = 10
input_locations,output_locations, = [], []
for i, file in enumerate(glob.glob("data/processedimages/*.png")):
input_1_s3_location = upload_image(sess,file,sess.default_bucket())
input_locations.append(input_1_s3_location)
async_response = base_model_predictor.predict_async(input_path=input_1_s3_location)
output_locations.append(async_response.output_path)
if i > max_images:
break这可能需要最多30分钟或更长时间,具体取决于你上传的异步推理数据量。你可以按照以下方式可视化其中一个推理结果:
plot_response('data/single.out')
将异步推理输出转换为Ground Truth输入清单
在这一步中,我们为Ground Truth上的边界框验证任务创建一个输入清单。我们上传Ground Truth UI模板和标签分类文件,并创建验证任务。本文链接的笔记本使用私有工作人员执行标注,如果你使用其他类型的工作人员,可以进行更改。有关详细信息,请参阅笔记本中的完整代码。
在Ground Truth中验证自动标注过程中的标签
在这一步中,我们通过访问标注门户完成验证。有关详细信息,请参阅此处。
当你作为工作人员访问门户时,你将能够查看JumpStart模型创建的边界框,并根据需要进行调整。

你可以使用这个模板来使用许多任务特定的模型重复进行自动标注,可能合并标签,并将生成的标记数据集用于下游任务。
清理
在这一步中,我们通过删除先前步骤中创建的终端节点和模型来进行清理:
# 删除SageMaker终端节点
base_model_predictor.delete_model()
base_model_predictor.delete_endpoint()结论
在本文中,我们介绍了涉及JumpStart和异步推理的自动标注过程。我们使用自动标注过程的结果将标记数据转换和可视化到一个真实世界数据集上。你可以使用该解决方案来使用许多任务特定的模型进行自动标注,可能合并标签,并在下游任务中使用生成的标记数据集。你还可以探索使用诸如Segment Anything Model之类的工具,作为自动标注过程的一部分生成分割掩膜。在本系列的未来文章中,我们将讨论感知模块和分割。有关JumpStart和异步推理的更多信息,请参阅SageMaker JumpStart和Asynchronous inference。我们鼓励您在AV/ADAS之外的用例中重用此内容,并与AWS联系以获取任何帮助。






