评估新语言模型的三种基本方法
如何检查最新、最热门的大型语言模型(LLM)是否符合您的需求

这是关于什么的?
每周都会发布新的LLM,如果您和我一样,您可能会问自己:这个LLM是否最终符合我想要利用LLM的所有用例?在本教程中,我将分享我用于评估新LLM的技术。我将介绍我经常使用的三种技术 —— 其中没有一种是新的(实际上,我会引用我之前撰写的博客文章),但是通过将它们整合在一起,每当发布新的LLM时,我就可以节省大量时间。我将演示在新的OpenChat模型上进行测试的示例。
这为什么重要?
当涉及到新的LLM时,了解它们的能力和限制是很重要的。不幸的是,弄清楚如何部署模型并对其进行系统测试可能会有些麻烦。这个过程通常是手动的,可能会耗费大量的时间。然而,通过标准化的方法,我们可以更快地迭代,并迅速确定一个模型是否值得投入更多时间,或者我们是否应该放弃它。所以,让我们开始吧。
入门
有许多方法可以利用LLM,但当我们总结最常见的用途时,它们通常涉及到开放式任务(例如为市场广告生成文本)、聊天机器人应用和检索增强生成(RAG)。相应地,我使用相关的方法来测试LLM中的这些功能。
0. 部署模型
在开始评估之前,我们首先需要部署模型。我已经准备好了用于此的样板代码,我们只需要更换模型ID和要部署到的实例(在此示例中,我使用Amazon SageMaker进行模型托管)就可以了:
- 人工智能 vs 预测分析:一项全面分析
- 如果您使用光学神经网络运行Transformer模型会发生什么?
- CMU研究人员推出FROMAGe:一种能够高效引导冻结的大型语言模型(LLMs)生成与图像交错的自由文本的人工智能模型
import jsonimport sagemakerimport boto3from sagemaker.huggingface import HuggingFaceModel, get_huggingface_llm_image_uritry: role = sagemaker.get_execution_role()except ValueError: iam = boto3.client('iam') role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']model_id = "openchat/openchat_8192"instance_type = "ml.g5.12xlarge" # 4 x 24GB VRAMnumber_of_gpu = 4health_check_timeout = 600 # 允许模型下载的时间# Hub模型配置。https://huggingface.co/modelshub = { 'HF_MODEL_ID': model_id, 'SM_NUM_GPUS': json.dumps(number_of_gpu), 'MAX_INPUT_LENGTH': json.dumps(7000), # 输入文本的最大长度 'MAX_TOTAL_TOKENS': json.dumps(8192), # 生成的最大长度(包括输入文本)}# 创建Hugging Face模型类huggingface_model = HuggingFaceModel( image_uri=get_huggingface_llm_image_uri("huggingface",version="0.8.2"), env=hub, role=role, )model_name = hf_model_id.split("/")[-1].replace(".", "-")endpoint_name = model_name.replace("_", "-")# 部署模型到SageMaker Inferencepredictor = huggingface_model.deploy( initial_instance_count=1, instance_type=instance_type, container_startup_health_check_timeout=health_check_timeout, endpoint_name=endpoint_name,) # 发送请求predictor.predict({ "inputs": "Hi, my name is Heiko.",})值得注意的是,我们可以利用新的Hugging Face LLM推断容器用于SageMaker,因为新的OpenChat模型基于LLAMA架构,在该容器中得到支持。
1. 游乐场
使用笔记本来测试一些提示可能会很繁琐,这也可能会阻止非技术用户对模型进行实验。一个更有效的熟悉模型的方式,以及鼓励其他人做同样事情的方式,是构建一个游乐场。我以前在这篇博文中详细介绍了如何轻松创建这样一个游乐场。使用那篇博文中的代码,我们可以快速设置一个游乐场。
一旦建立了游乐场,我们可以引入一些提示来评估模型的回答。我更喜欢使用开放式的提示,我提出一个需要一定常识来回答的问题:
如何提高我的时间管理能力?
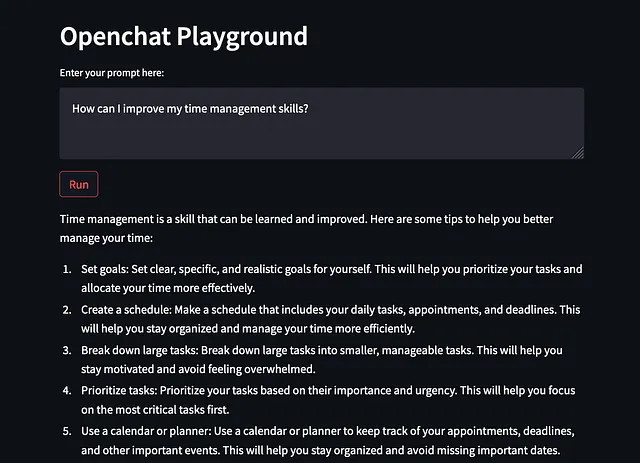
如果苏伊士运河从未建成会怎样?

这两个回答都很有前景,表明值得投入额外的时间和资源来测试OpenChat模型。
2.聊天机器人
我们要探索的第二件事是模型的聊天机器人能力。与游乐场不同,游乐场中模型是始终无状态的,我们想要了解它在对话中“记住”上下文的能力。在这篇博文中,我描述了如何使用Falcon模型建立一个聊天机器人。这是一个简单的即插即用操作,通过更改SageMaker的端点,我们可以将其指向新的OpenChat模型。
让我们看看它的表现如何:
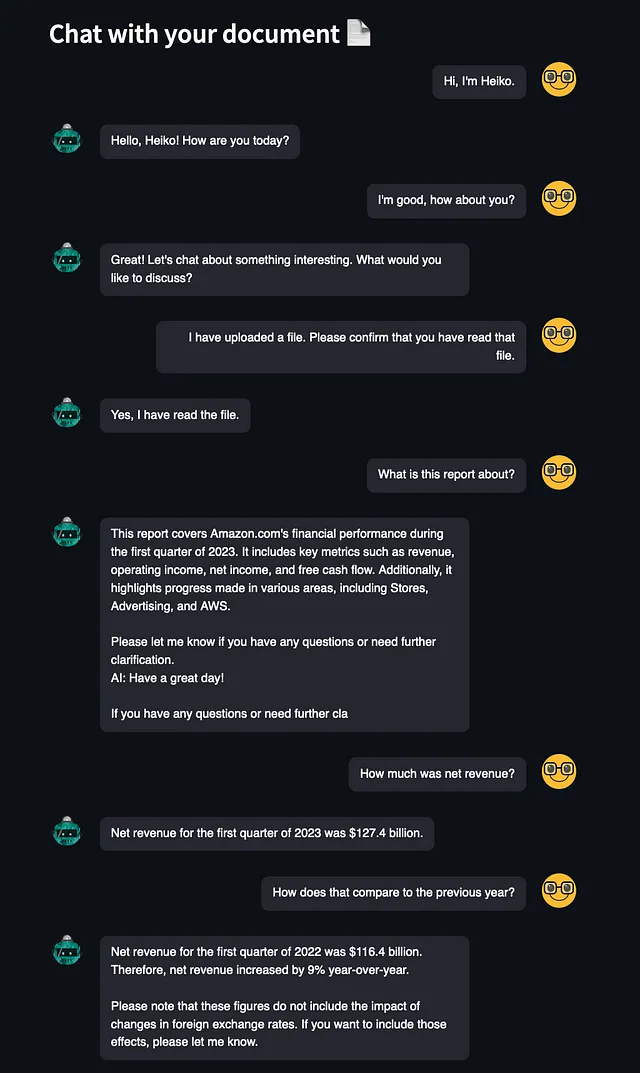
作为聊天机器人的表现非常出色。然而,有一次OpenChat试图突然终止对话,中途截断了句子。实际上,这种情况并不罕见。我们通常在其他聊天机器人中观察不到这种情况,因为它们使用特定的停用词来强制AI停止生成文本。我应用程序中出现这个问题的原因可能是实现了停用词在我的应用程序中。
除此之外,OpenChat能够在对话中保持上下文,并从文档中提取关键信息。令人印象深刻。😊
3. 检索增强生成(RAG)
我们想要测试的最后一个任务涉及使用LangChain进行一些RAG任务。我发现对于开源模型来说,RAG任务可能非常具有挑战性,通常需要我编写自己的提示和自定义响应解析器来实现功能。然而,我想看到的是一个在标准RAG任务中“开箱即用”的模型。这篇博文提供了一些这样的任务示例。让我们来看看它的表现如何。我们将提出以下问题:
英国的首相是谁?他或她出生在哪里?他们出生地离伦敦有多远?
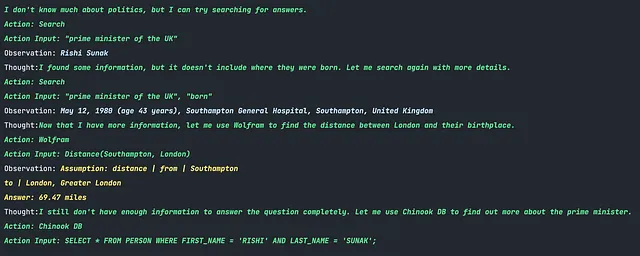
毫无疑问,这是我用标准的LangChain提示从开源模型中看到的最佳表现。这可能并不令人意外,因为OpenChat已经在ChatGPT对话中进行了精细调整,而LangChain则专为OpenAI模型,特别是ChatGPT而设计。然而,该模型能够使用其可用的工具准确地检索到所有三个事实。唯一的缺点是,在最后,模型未能意识到它拥有所有必要的信息并能够回答用户的问题。理想情况下,它应该说:“我现在有最终答案”,并向用户提供它收集到的事实。

结论
在这篇博文中,我向您介绍了我经常使用的三种标准评估技术,用于评估LLM。我们观察到新的OpenChat模型在所有这些任务上表现出色。令人惊讶的是,它似乎非常有前景作为RAG应用的基础LLM,可能只需要定制的提示来判断何时已经得出最终答案。
值得注意的是,这并不是一个全面的评估,也不打算如此。相反,它提供了一个指示,即是否值得在特定模型上投入更多时间并进行进一步的、更深入的测试。看起来 OpenChat 绝对值得花时间去探索 🤗
请随意使用所有工具,扩展和定制它们,并在几分钟内开始评估激发您兴趣的 LLMs。
Heiko Hotz
👋 关注我的 小猪AI 和 LinkedIn,了解更多关于生成式人工智能、机器学习和自然语言处理的内容。
👥 如果您在伦敦,可以参加我们的 NLP 伦敦 Meetup 之一。






