机器学习中再现性的重要性
如何通过更好的数据管理、版本控制和实验追踪方法来帮助构建可重复的机器学习流程

当我自学机器学习时,经常会尝试跟着项目教程编写代码。我会按照作者所概述的步骤进行操作。但是,有时我的模型表现会比教程作者的模型要差。也许你也遇到过类似的情况。或者你只是从GitHub上拉取了同事的代码。你的模型的性能指标与同事报告的指标不同。所以,同样的方法并不能保证获得相同的结果,对吗?这是机器学习中一个普遍存在的问题:可复现性的挑战。
毋庸置疑,只有当他人能够复制实验并获得相同的结果时,机器学习模型才有用。从典型的“在我的机器上能运行”问题到机器学习模型训练方式的微小变化,可复现性面临着多个挑战。
在本文中,我们将更详细地探讨机器学习可复现性的重要性及其挑战,以及数据管理、版本控制和实验跟踪在解决机器学习可复现性挑战中的作用。
机器学习中的可复现性是什么?
让我们看看如何在机器学习的背景下最好地定义可复现性。
假设有一个使用特定机器学习算法在给定数据集上的现有项目。在给定数据集和算法的情况下,我们应该能够运行该算法(尽可能多次),并在每次运行中产生相同的结果。
但是,在机器学习中,可复现性并非没有挑战。我们已经讨论了其中的一些,接下来我们将更详细地讨论它们。
机器学习中可复现性的挑战
对于任何应用程序,都有可靠性和可维护性等挑战。然而,在机器学习应用程序中,存在额外的挑战。
当我们谈论机器学习应用程序时,通常指的是端到端的机器学习流程,通常包括以下步骤:
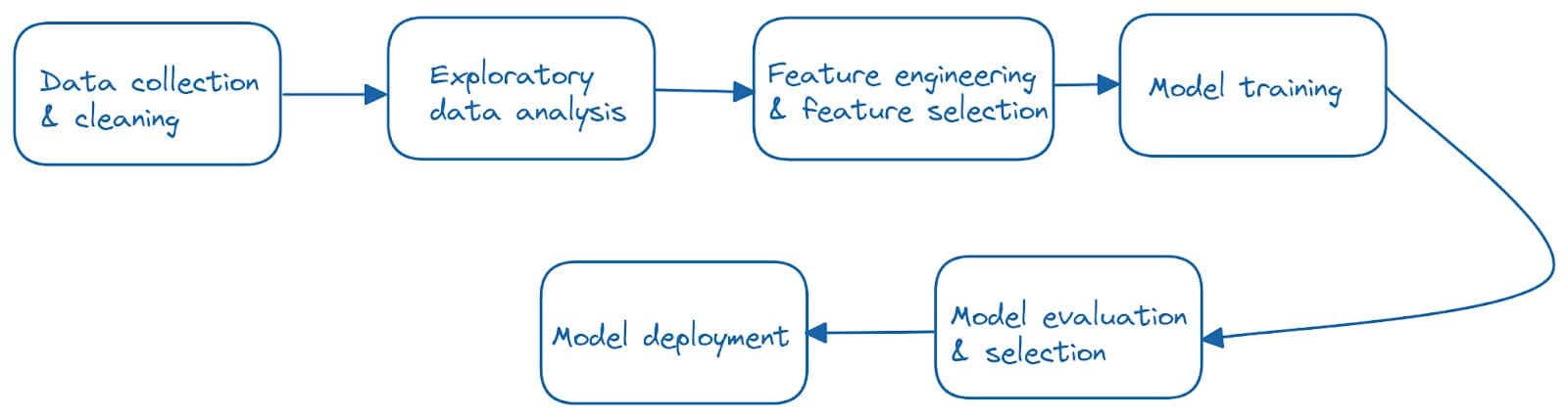
因此,由于其中一个或多个步骤的更改,可能会出现可复现性挑战。而大多数更改可以归纳为以下几个方面:
- 环境变化
- 代码变化
- 数据变化
让我们看看每种变化如何阻碍可复现性。
环境变化
Python和基于Python的机器学习框架可以轻松开发ML应用程序。但是,在Python中进行依赖项管理-管理给定项目所需的不同库和版本是一个非常棘手的挑战。例如,使用不同版本的库和使用不推荐的参数调用函数等微小更改足以破坏代码。
这也包括操作系统的选择。存在与硬件相关的挑战,例如GPU浮点精度的差异等。
代码变化
从对输入数据集进行洗牌以确定哪些样本进入训练数据集到在训练神经网络时随机初始化权重-随机性在机器学习中扮演重要角色。
设置不同的随机种子可能会导致完全不同的结果。对于我们训练的每个模型,都有一组超参数。因此,调整一个或多个超参数也可能导致不同的结果。
数据变化

即使使用相同的数据集,我们也已经看到超参数值和随机性的不一致可能会使结果难以复制。因此,当数据发生变化时-数据分布的变化,对一部分记录进行修改或删除样本-会使结果难以复制。
总之:当我们尝试复制机器学习模型的结果时,即使是代码、使用的数据集和机器学习模型运行的环境中的微小更改也可能会阻止我们获得与原始模型相同的结果。
如何应对可重复性挑战
现在我们将看到如何解决这些挑战。 
数据管理
我们看到可重复性中最明显的挑战之一就是数据。有一些数据管理方法,例如对数据集进行版本控制,以便我们可以跟踪数据集的更改,并在数据集上存储有用的元数据。
版本控制
任何对代码的更改都应该使用版本控制系统,例如Git进行跟踪。
在现代软件开发中,你可能已经遇到了CI/CD流程,这使得跟踪更改、测试新更改以及将它们推向生产变得更加简单和高效。
在其他软件应用程序中,跟踪代码的更改很容易。但是,在机器学习中,代码的更改也可能涉及使用的算法和超参数值的更改。即使对于简单的模型,我们可以尝试的可能性也是组合性很大的。这就是实验跟踪变得相关的地方。
实验跟踪
构建机器学习应用程序是与广泛的实验相等的。从算法到超参数,我们使用不同的算法和超参数值进行实验。所以跟踪这些实验非常重要。
跟踪机器学习实验包括:
- 记录超参数扫描
- 记录模型的性能指标、模型检查点
- 存储有关数据集和模型的有用的元数据
机器学习实验跟踪、数据管理等工具
正如所见,版本控制数据集、跟踪代码更改和跟踪机器学习实验可以复制机器学习应用程序。下面是一些可以帮助您构建可重复的机器学习流程的工具:
- Weights and Biases
- MLflow
- Neptune.ai
- Comet ML
- DVC
总结
综上所述,我们回顾了机器学习中可重复性的重要性和挑战。我们介绍了数据和模型版本控制和实验跟踪等方法。此外,我们还列出了一些可以用于实验跟踪和更好的数据管理的工具。
DataTalks.Club的MLOps Zoomcamp是一个优秀的资源,可以通过使用其中一些工具来获得经验。如果您喜欢构建和维护端到端机器学习流程,您可能对了解MLOps工程师的角色感兴趣。Bala Priya C是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她感兴趣和擅长的领域包括DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过编写教程、指南、观点文章等来学习和与开发人员社区分享她的知识。