META的Hiera:减少复杂性以提高准确性
| 人工智能 | 计算机视觉 | VITs |
简单性使AI能够达到惊人的性能和惊人的速度
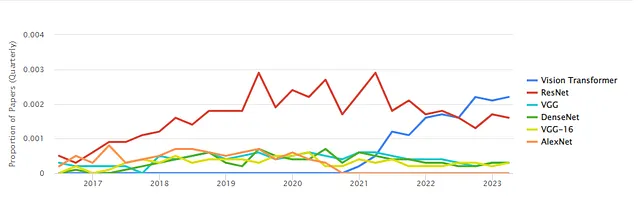
卷积网络支配了计算机视觉领域超过二十年。随着Transformer的到来,人们认为它们将被放弃。然而,许多从业者在项目中使用基于卷积的模型。为什么?
本文试图回答以下问题:
- 什么是Vision Transformer?
- 它们的局限性是什么?
- 我们可以试图克服它们吗?
- 为什么以及META Hiera如何成功?
Vision Transformer:一张图像值多少个单词?

近年来,Vision Transformer主导了视觉基准测试,但它们到底是什么?
直到几年前,卷积神经网络是视觉任务的标准。然而,在2017年,Transformer发布并颠覆了自然语言处理世界。在文章《Attention is all you need》中,作者展示了仅使用自我关注构建的模型比RNN和LSTM具有更优越的性能。因此人们很快就会想:is它可能将Transformer应用于图像吗?
在2020年之前,已经尝试了包含自我关注集成的混合模型。无论如何,这些模型无法很好地扩展。思路是找到一种方式,使Transformer可以在图像中本地使用。
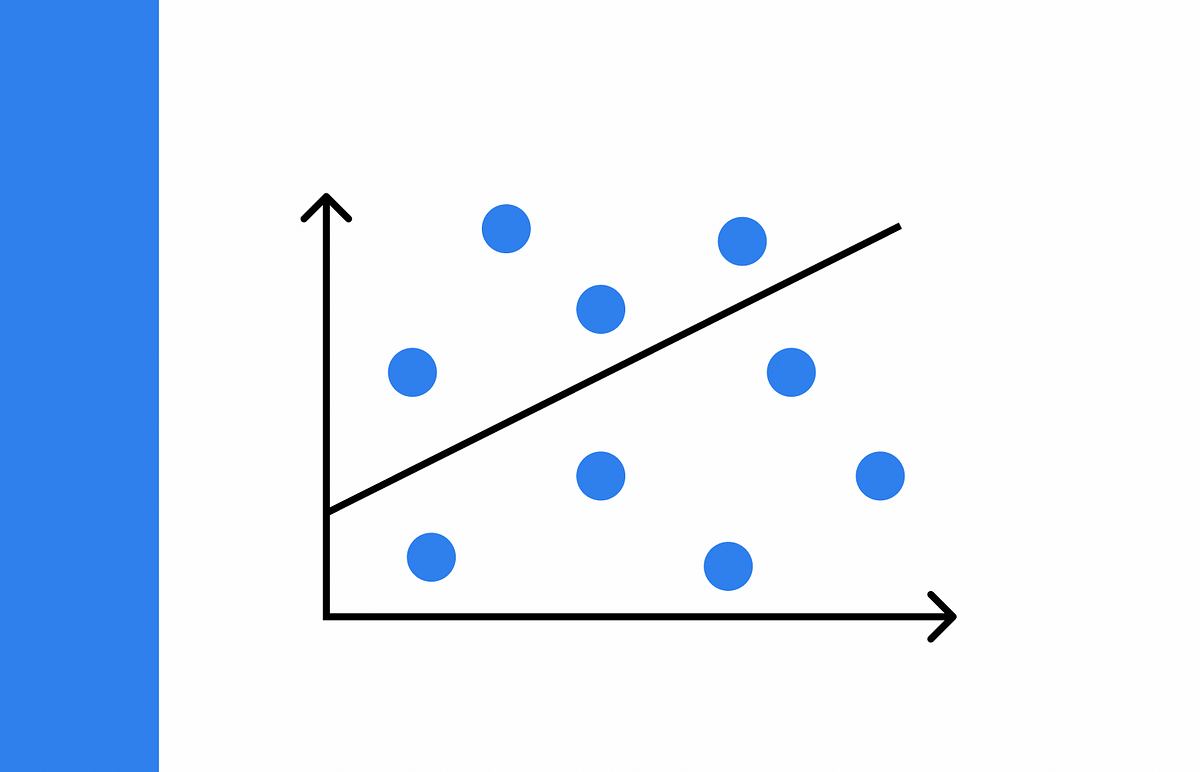
在2020年,Google的作者决定最好的方式是将图像分成不同的块,然后具有序列的嵌入。这样,图像基本上被视为来自模型的令牌(单词)。
在短时间内,卷积神经网络在计算机视觉领域的主导地位正在逐渐被削弱。Vision Transformer在以前一直由CNN主导的基准测试(如ImageNet)上表现出优越性。
实际上,如果提供足够的数据,Vision Transformers(ViTs)表现优于CNNs。同时也表现出尽管存在几个差异,但也有几个相似之处:
- ViTs和CNNs都构建了复杂和渐进的表示。
- 然而,ViTs更能够利用背景中存在的信息,并且显得更加健壮。
视觉转换器看到什么的视觉旅程
最大的模型如何看待世界
pub.towardsai.net
此外,变压器的可扩展性是其额外的优势。这是ViTs的竞争优势,使它们成为受欢迎的选择。
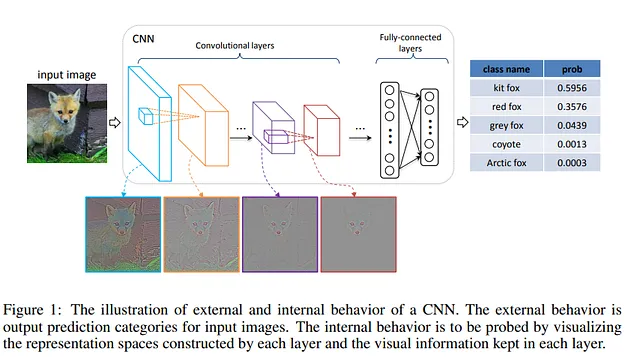
事实上,多年来我们已经看到了数百万参数的CNN和达到数十亿参数的ViT。去年,谷歌展示了如何将ViTs扩展至20 B参数,未来可能会看到更大的模型。
为什么有巨大的语言模型和小的视觉转换器?
Google ViT-22为新的大型变压器铺平了道路,并革命了计算机视觉
towardsdatascience.com
视觉转换器的限制
虽然自适应变换器在本质上适应了转换器,但代价很高:ViTs在使用参数时效率低下。这是因为它们在网络中使用相同的空间分辨率和通道数。
CNN具有两个方面,这两个方面决定了它们最初的运用(都受到人类皮层的启发):
- 在层次结构中向上移动时降低空间分辨率。
- 增加不同“通道”的数量,每个通道变得越来越专业化。
另一方面,变换器的结构是一系列的自我关注块,其中发生了两个主要操作,从而使其具有很好的泛化能力:
- 关注操作用于建模元素间的关系。
- 全连接层用于建模元素间的关系。
事实上,这早就被指出来,原因是变形器是为单词而设计的,而不是为图像而设计的。毕竟,文本和图像是两种不同的模式。其中一个区别是单词不会随着图像变化而变化,而图像会。 当您必须关注在目标检测中按比例变化的元素时,这是冲突的。
此外,图像中像素的分辨率高于文本段落中单词的分辨率。由于关注成本是二次成本,因此使用高分辨率图像具有较高的计算成本。
以往的研究尝试使用分层特征图来解决这个问题。例如,Swin Transformer通过从小的补丁开始然后逐渐合并各种邻居补丁来构建分层表示。
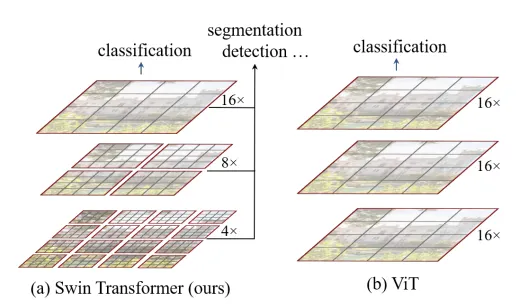
其他研究尝试在ViTs中实现多通道。例如,MVIT尝试创建最初的通道,重点放在简单的低级视觉信息上,而更深的通道则专注于CNN中的复杂高级特征。

然而,这些并没有完全解决问题。随着时间的推移,越来越复杂的模型和专业模块被提出,这在某种程度上提高了性能,但使ViTs训练变得相当缓慢。
我们是否可以解决这些变压器限制,而不需要复杂的解决方案?
如何学习空间关系

ViT已经成为计算机视觉的模型,然而,越来越复杂的修改已经成为必要的适应措施。
我们能否解决这些Transformer的限制,而不需要复杂的解决方案?
近年来,努力简化模型并加快速度。经常使用的一种方法是引入稀疏性。在计算机视觉的情况下,一个非常成功的模型是掩蔽自编码器(MAE)。
在这种情况下,将图像分成多个部分,然后遮盖多个部分。然后,解码器必须从遮盖部分重构。 ViT编码器然后仅在25%的补丁上运行。在这种情况下,您可以使用计算和内存的一小部分来训练宽编码器。
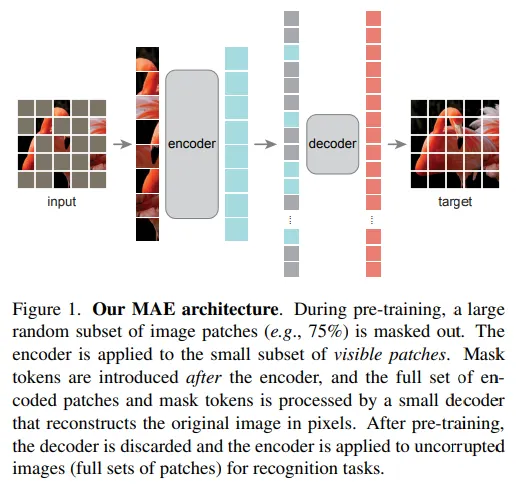
已经证明,该方法能够教授空间推理,达到与Swin和Mvit相当甚至更好的结果(然而,它们计算上要复杂得多)。
另一方面,虽然稀疏性方案获得了训练效率,但CNN的一个伟大优点是层次结构方法。但它与稀疏性相冲突。
实际上,以前已经进行过测试,但没有取得太大的成功:
- 得到的模型速度太慢(MaskFeat或SimMIM)。
- 修改使模型变得不必要地复杂,而且没有提高准确性(UM-MAE或MCMAE)。
能否设计一种稀疏和分层但高效的模型?
META的新工作已经摆脱了MAE训练和其他技巧,构建了一种高效而准确的ViT,无需过去所使用的所有这些复杂结构。
Hiera:没有花哨的分层视觉Transformer
现代分层视觉Transformer在追求监督时添加了几个视觉特定组件…
arxiv.org
Hiera:分层,稀疏,高效的ViT
模型
基本思想是,在训练具有高视觉任务准确性的分层ViT时,不需要使用使其变慢和复杂的整个系列元素。根据作者的说法,可以使用掩蔽自编码器训练来从模型中学习空间偏差。
在MAE中,删除了图像的一部分,因此在分层模型中,重构2D网格(和空间关系)存在问题。作者解决了这个问题,使得核心不能在掩蔽单元之间重叠(在池化期间,与掩蔽单元没有重叠)。

然后,作者从现有的ViT分层模型MViTv2开始,并决定重复使用MAE训练。该模型由多个ViT块构建,但是如结构中所示,某个时刻会缩小大小,这是通过使用池化注意力实现的。
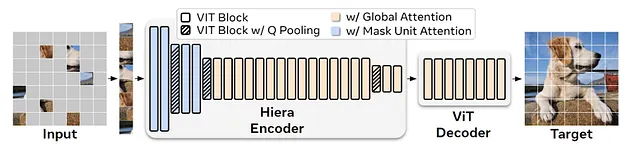
在池化注意力期间,使用3×3卷积局部聚合特征,然后计算自注意力(这是为了减少K和V的大小,从而减少计算计算)。使用视频时,这种机制可能变得昂贵。因此,作者将其替换为Mask Unit Attention。
换句话说,在Hiera中,在池化过程中,内核会移动,以使掩码部分不会进入池化。因此,对于每组标记(掩码大小),都有一种本地注意力。

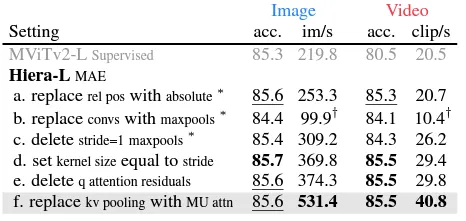
然后,MViTv2引入了一整套增加了复杂性的附件,但作者认为它们是不必要的并将它们删除:
- 相对位置嵌入。将位置嵌入添加到每个块的注意力中。
- 最大池化层,这将需要填充以在Hiera中使用。
- 注意力残差,其中Q(查询)和输出之间存在残差连接,以更好地学习池化注意力。作者已减少了层数,因此不再需要。
作者表明,这些变化的影响单独地促进了精度和速度的提高。
总的来说,简化模型不仅使Hiera变得更快(对于图像和视频),而且也比其对应的MViTv2模型和其他模型更准确。
Hiera在图像上比MViTv2快2.4倍,在视频上比MViTv2快5.1倍,而且实际上更准确,因为MAE(来源)
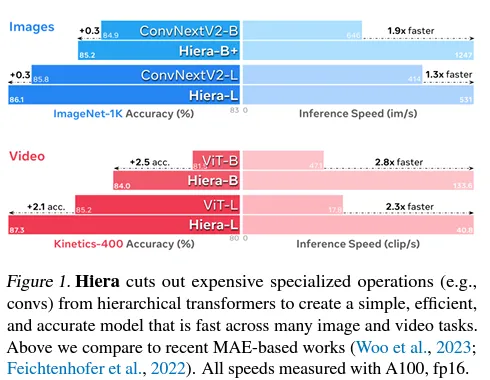
作者指出,该模型不仅在推断方面更快,而且训练速度也更快。

结果
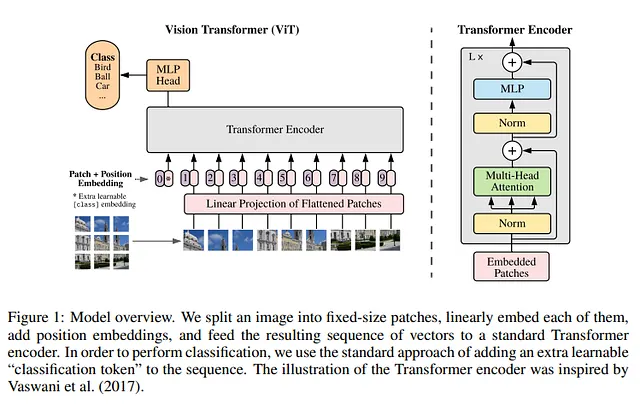
作者展示了基本模型确实使用有限数量的参数在Imagenet 1K(最重要的图像分类数据集之一)上取得了良好的结果。
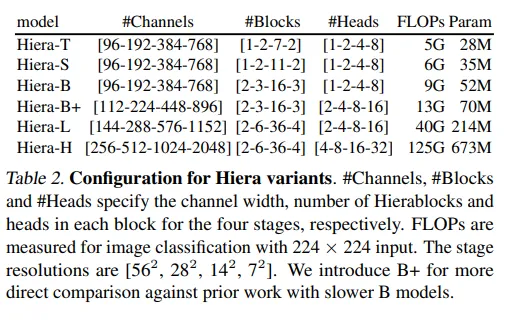
第二个要点是,通常在低参数区域,基于卷积的模型占主导地位。在这里,较小的模型显示出非常好的结果。对于作者来说,这证实了他们的直觉,即在训练过程中可以学习到空间偏差,因此即使是对于小型模型,ViTs也可以与卷积网络竞争。
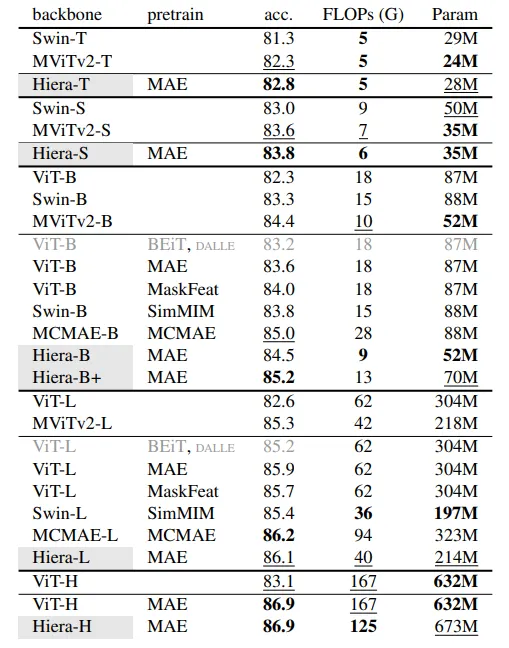
大型CNN模型的财富在于将它们用于迁移学习。ResNet和基于VGG的模型都已在Imagenet上进行了训练,然后由社区适应了许多任务。因此,作者使用两个数据集iNaturalists和Places测试了Hiera的迁移学习能力。
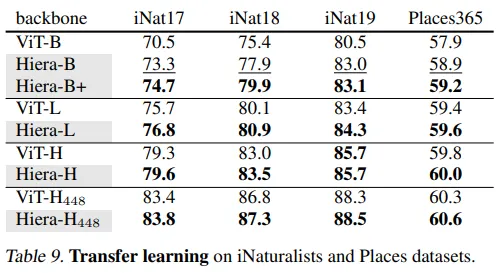
作者在这两个数据集上微调模型,并展示了他们的模型优于以前的ViTs。这表明他们的模型也可以用于其他数据集。
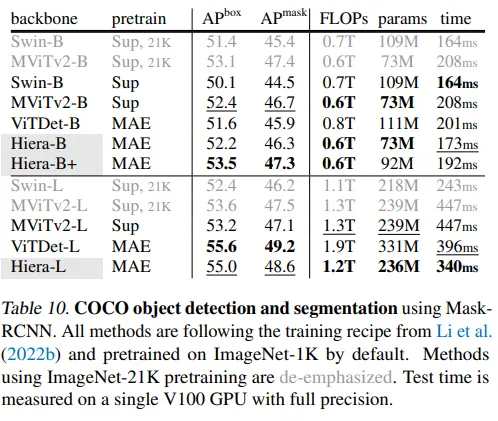
此外,作者还使用了另一个流行的数据集COCO。虽然iNaturalists和Places是用于图像分类的数据集,但COCO是计算机科学中最广泛使用的用于图像分割和目标检测的数据集之一。同样,该模型表现出了强大的缩放行为(随着参数的增加而性能增加)。此外,该模型在训练和推断期间都更快。
此外,该模型已在视频上进行了测试。具体来说,在两个视频分类数据集上进行了测试。Hiera表明,它在参数较少的情况下表现更好。该模型的推理速度也更快。作者表明,该模型在这种类型的任务中达到了最新颖的水平。
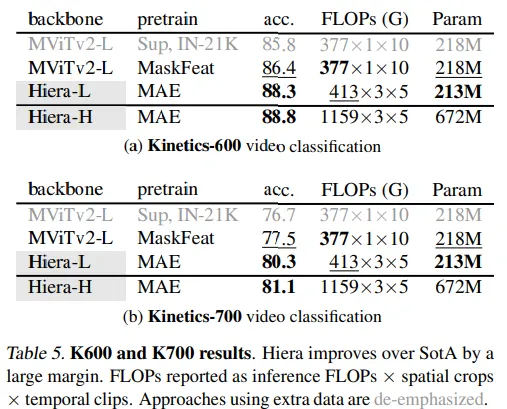
作者表明,该模型也可以用于其他视频任务,例如动作检测。
总结
在这项工作中,我们通过采用现有的视觉Transformer并消除所有添加元素的方式来创建一个简单的分层视觉Transformer,同时通过MAE预训练为模型提供空间偏置。 (来源)
作者表明,许多用于提高Transformer性能的元素实际上不仅是不必要的,而且会增加模型的复杂性,使其变慢。
相反,作者表明,使用MAE和分层结构可以导致ViT在图像和视频方面更快,更准确。
这项工作非常重要,因为对于许多任务,社区仍然使用基于卷积的模型。ViTs是非常大的模型,计算成本较高。因此,人们通常更喜欢使用基于ResNet和VGG的模型。更准确但尤其是推理更快的ViTs可能会改变游戏规则。
其次,它突显了在训练中利用稀疏性的趋势。它具有减少参数、加速训练和推理的优点。总的来说,稀疏性的想法在人工智能的其他领域也被看到,并且是一个活跃的研究领域。
如果您觉得这很有趣:
您可以查看我的其他文章,您还可以订阅以在我发布文章时收到通知,您可以成为小猪AI会员以访问所有故事(平台的附属链接,我可以获得小额收入而您不需要承担任何费用),您还可以在LinkedIn上连接或联系我。
这是我的GitHub存储库链接,我计划收集与机器学习、人工智能等相关的代码和资源。
GitHub—SalvatoreRa/tutorial: 机器学习、人工智能、数据科学教程
机器学习、人工智能、数据科学教程,包括数学解释和可重用的代码(使用Python…
github.com
或者您可能会对我最近的一篇文章感兴趣:
模仿游戏:驯服开源和专有模型之间的差距
模仿模型能否达到ChatGPT等专有模型的性能?
levelup.gitconnected.com
扩展并不是一切:更大的模型失败得更惨
大型语言模型真正理解编程语言吗?
salvatore-raieli.medium.com
META’S LIMA:Maria Kondo培训LLMs的方法
更少、更整洁的数据,创建一个能够与ChatGPT匹敌的模型
levelup.gitconnected.com
AI有趣吗?也许有点
AI为什么仍在努力学习幽默,以及这为什么是重要的一步
levelup.gitconnected.com
参考资料
以下是我撰写本文时参考的主要资料列表,仅列出了每篇文章的第一个作者。
- Chaitanya Ryali等人,2023年,Hiera: 一种没有花哨的分层视觉Transformer,链接
- Peng Gao等人,2022年,MCMAE: 掩模卷积遇见掩模自编码器,链接
- Xiang Li等人,2022年,Uniform Masking: 使金字塔视觉Transformer具有局部性能力的MAE预训练,链接
- Zhenda Xie等人,2022年,SimMIM: 一种用于掩模图像建模的简单框架,链接
- Ze Liu等人,2021年,Swin Transformer: 使用移位窗口的分层视觉Transformer,链接
- Haoqi Fan等人,2021年,多尺度视觉Transformer,链接
- Kaiming He等人,2021年,掩模自编码器是可扩展的视觉学习器,链接
- Chen Wei等人,2021年,自监督视觉预训练的掩模特征预测,链接
- Alexey Dosovitskiy等人,2020年,一张图片值16×16个单词:规模化图像识别的Transformer,链接
- Ashish Vaswani等人,2017年,注意力机制即全部,链接
- Kaiming He等人,2015年,深度残差网络用于图像识别,链接
- Wei Yu等人,2014年,卷积神经网络的可视化和比较,链接
- Karen Simonyan等人,2014年,用于大规模图像识别的非常深的卷积网络,链接
- 为什么我们有巨大的语言模型和小型视觉Transformer?,TDS,链接
- 视觉Transformer看到的视觉旅程,TowardsAI,链接
- Vision Transformer,paperswithcode,链接