现代数据工程与MAGE:赋能高效数据处理
介绍
在今天的数据驱动世界中,各行各业的组织都在处理海量数据、复杂管道和高效数据处理的需求。传统的数据工程解决方案,如 Apache Airflow,在编排和控制数据操作方面发挥了重要作用,以应对这些困难。然而,随着技术的快速发展,一个新的竞争者出现了——Mage,以重塑数据工程领域的格局。
学习目标
- 无缝集成和同步第三方数据
- 使用 Python、SQL 和 R 构建实时和批处理管道进行转换
- 可重复使用和可测试的模块化代码,带有数据验证
- 在您睡觉时运行、监控和编排多个管道
- 在云端协作、版本控制使用 Git,并在不等待共享暂存环境的情况下测试管道
- 通过 terraform 模板快速部署在 AWS、GCP 和 Azure 等云提供商上
- 直接在您的数据仓库中或通过与 Spark 的本地集成转换非常大的数据集
- 通过直观的用户界面内置监控、警报和可观测性
是不是容易得像掉树上的果子一样?那你一定要尝试 Mage!
在本文中,我将讨论 Mage 的功能和功能,重点介绍我迄今为止学到的内容以及我使用它构建的第一个管道。
本文是数据科学博客马拉松的一部分。
什么是 Mage?
Mage 是一个由人工智能驱动的现代数据编排工具,建立在机器学习模型之上,旨在前所未有地简化和优化数据工程流程。它是一个轻松而有效的开源数据管道工具,用于数据转换和集成,可以是像 Airflow 这样的成熟工具的强有力的替代品。通过结合自动化和智能的力量,Mage 改变了数据处理工作流程,改变了数据的处理方式。Mage 旨在简化和优化数据工程流程,具有无与伦比的能力和用户友好的界面,与以往任何工具都不同。
步骤 1:快速安装
Mage 可以使用 Docker、pip 和 conda 命令安装,也可以作为虚拟机托管在云服务上。
使用 Docker
#使用 Docker 安装 Mage 的命令行
>docker run -it -p 6789:6789 -v %cd%:/home/src mageai/mageai /app/run_app.sh mage start [project_name]
#使用不同端口在本地安装 Mage 的命令行
>docker run -it -p 6790:6789 -v %cd%:/home/src mageai/mageai /app/run_app.sh mage start [project_name]使用 Pip
#使用 pip 命令安装
>pip install mage-ai
>mage start [project_name]
#使用 conda 安装
>conda install -c conda-forge mage-ai还有其他安装 Mage 的附加包,如使用 Spark、Postgres 等。在本示例中,我使用了 Google Cloud Compute Engine 通过 SSH 访问 Mage(作为 VM)。安装必要的 Python 包后,我运行了以下命令。
#安装 Mage 的命令
~$ mage sudo pip3 install mage-ai
#启动项目的命令
~$ mage start nyc_trides_project
检查端口 6789...
Mage 在 http://localhost:6789 上运行,并提供 /home/srinikitha_sri789/nyc_trides_proj 项目
INFO:mage_ai.server.scheduler_manager:Scheduler status: running.步骤 2:构建
Mage 提供了几个内置代码块,具有测试案例,可以根据项目要求进行自定义。

我使用了数据加载器、数据转换器和数据导出器块(ETL)从 API 加载数据,转换数据并将其导出到 Google Big Query 以进行进一步分析。
让我们学习每个块的工作原理。
I) 数据加载器
“数据加载器”块作为管道内数据源和后续数据处理阶段之间的桥梁。数据加载器从源中摄取数据并将其转换为适合进一步处理的合适格式。
关键功能
- 数据源连接:数据加载器块允许连接到各种数据库、API、云存储系统(Azure Blob Storage、GBQ、GCS、MySQL、S3、Redshift、Snowflake、Delta Lake等)和其他流媒体平台。
- 数据质量检查和错误处理:在数据加载过程中,它执行数据质量检查,以确保数据准确、一致且符合已建立的验证标准。所提供的数据管道逻辑可用于记录、标记或解决发现的任何错误或异常。
- 元数据管理:数据加载器块管理和捕获与摄取数据相关的元数据。数据源、抽取时间戳、数据模式和其他事实都包含在此元数据中。通过有效的元数据管理,使数据流水线中的数据血统、审计和跟踪数据转换更加容易。
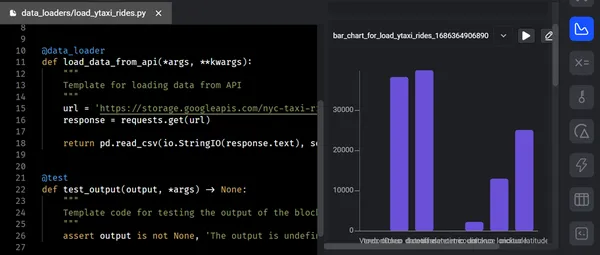
下面的屏幕截图显示了使用数据加载器从API加载原始数据到Mage。在执行数据加载器代码并成功通过测试用例后,输出以树形结构呈现在终端中。


II) 数据转换
“数据转换”块对传入数据进行操作,提取有意义的见解并为下游过程做好准备。它具有通用代码选项和一个包含可重用且可测试的模块化代码的独立文件,Python模板用于数据探索、重新缩放和必要的列操作、SQl和R的数据验证。
关键功能
- 数据合并:数据转换器块使从不同来源或不同数据集合并数据更容易。数据工程师可以根据相似的键特性组合数据,因为它支持各种连接,包括内连接、外连接和交叉连接。在进行数据增强或从多个来源合并数据时,此功能非常有用。
- 自定义函数:它允许定义和应用自定义函数和表达式来操作数据。您可以利用内置函数或编写用户定义的函数进行高级数据转换。
加载数据后,转换代码将执行所有必要的操作(在本例中,将平面文件转换为事实和维度表),并将代码转换为数据导出器。执行数据转换块后,树形图如下所示:


III) 数据导出器
“数据导出器”块将处理后的数据导出并传递到各种目的地或系统,以供进一步消费、分析或存储。它确保与外部系统的无缝数据传输和集成。我们可以使用Python默认模板(API、Azure Blob Storage、GBQ、GCS、MySQL、S3、Redshift、Snowflake、Delta Lake等)、SQL和R将数据导出到任何存储。
关键功能
- 模式适应:它允许工程师调整所导出数据的格式和模式,以满足目的系统的要求。
- 批处理和流处理:数据导出器块可以在批处理和流处理模式下工作。它通过在预定义的时间间隔或基于特定触发器导出数据来促进批处理。此外,它支持实时数据流传输,使连续而几乎瞬时的数据传输到下游系统成为可能。
- 合规性:它具有加密、访问控制和数据脱敏等功能,以保护导出数据中的敏感信息。
在数据转换之后,我们使用数据导出器将经过转换/处理的数据导出到 Google BigQuery,以进行高级分析。执行数据导出器块后,下面的树状图说明了后续步骤。


第三步:预览/分析
“预览”阶段使数据工程师能够在管道的某个给定点检查和预览经过处理或中间处理的数据。这提供了一个有益的机会,可以检查数据转换的准确性,判断数据的质量,并了解更多关于数据的信息。
在此阶段,每次运行代码时,我们都会以图表、表格和图形的形式收到反馈。这些反馈可以让我们收集有价值的见解和信息。我们可以通过交互式笔记本 UI 立即查看代码的输出结果。在管道中,每个代码块都会生成我们可以版本化、分区和编目以供将来使用的数据。
关键功能
- 数据可视化
- 数据抽样
- 数据质量评估
- 中间结果验证
- 迭代开发
- 调试和故障排除

第四步:启动
在数据管道中,“启动”阶段代表最后一步,我们将处理后的数据部署到生产或下游系统以进行进一步分析。这个阶段确保数据被定向到适当的目的地,并为预期的用例提供了访问。
关键功能
- 数据部署
- 自动化和调度
- 监控和警报
- 版本和回滚
- 性能优化
- 错误处理
您可以使用维护的 Terraform 模板将 Mage 部署到 AWS、GCP 或 Azure,可以直接在数据仓库中转换非常大的数据集或通过与 Spark 的本地集成来实现管道的操作,并使用内置的监控、警报和可观察性来操作您的管道。
以下截图显示了管道的总运行次数及其状态(如成功或失败)、每个块的日志及其级别。



此外,Mage 优先考虑数据治理和安全性。它为数据工程操作提供了安全的环境。由于具有端到端加密、访问限制和审计能力等复杂的内置安全机制,Mage 的架构基于严格的数据保护规则和最佳实践,保护数据的完整性和机密性。此外,您可以应用实际的用例和成功案例,突出 Mage 在金融、电子商务、医疗保健等各种行业中的潜力。
其他差异
| MAGE | 其他软件 |
| Mage是用于运行数据管道的引擎,可以移动和转换数据。然后可以将该数据存储在任何地方(例如S3),并用于在Sagemaker中训练模型。 | Sagemaker:Sagemaker是一个完全托管的ML服务,用于训练机器学习模型。 |
| Mage是一个开源数据管道工具,用于集成和转换数据(ETL)。 | Fivetran:Fivetran是一家提供托管ETL服务的闭源Saas(软件即服务)公司。 |
| Mage是一个开源的数据管道工具,用于集成和转换数据。 Mage的重点是提供简单的开发人员体验。 | AirByte:AirByte是一个领先的开源ELT平台之一,可将数据从API、应用程序和数据库复制到数据湖、数据仓库和其他目的地。 |
结论
总之,数据工程师和分析专家可以通过利用Mage工具中的每个阶段的功能和功能以及其高效的管理和处理数据的框架,有效地加载、转换、导出、预览和部署数据。这种能力使数据驱动的决策、提取有价值的见解,并确保准备就绪生产或下游系统变得更加容易。它以其尖端的能力、可扩展性和对数据治理的强调而广受认可,这使它成为数据工程的游戏规则改变者。
主要要点
- Mage为全面的数据工程提供了管道,包括数据摄取、转换、预览和部署。这个端到端平台确保快速的数据处理、有效的数据传播和无缝的连接。
- Mage的数据工程师有能力在数据转换阶段应用各种操作,确保数据经过清洁、丰富和准备好进行后续处理。预览阶段允许对处理后的数据进行验证和质量评估,保证其准确性和可靠性。
- 在整个数据工程管道中,Mage将效率和可扩展性放在首要位置。为了提高性能,它利用并行处理、数据分区和缓存等优化技术。
- Mage的启动阶段使处理后的数据轻松传输到下游或生产系统。它具有自动化、版本控制、错误解决和性能优化工具,提供可信赖和及时的数据传输。
常见问题
本文中显示的媒体不是Analytics Vidhya所拥有的,而是根据作者的判断使用的。