5种高效的方法来查找和解决数据问题
揭示隐藏的异常和不一致性
根据 Gartner 的一项调查,近60%的组织不测量低质量数据的年度财务成本。我认为另外的40%在说谎。在我的经验中,数据质量带来的损失很少被组织量化,尽管它每天都会打击它们。
我认为我们的状态不是由于缺乏努力,而是因为我们不知道从哪里入手。像不良习惯一样,试图一次性或在一年的项目中修复所有问题都会导致失败。需要有一种文化转变,即责任制、清晰的流程和一点技术帮助。
今天,我们将深入探讨五种发现和解决问题的方法。让我们开始吧!
1. 对来自源系统的数据进行审核
像大多数大型组织一样,如果您有旧的过时的源系统来提供数据仓库/数据湖的信息,那么您知道源数据是一个大问题。
如果这些系统已经老旧,可能很难接受更改。在这种情况下,当数据在您的数据仓库接收或分阶段时,应用重复和对账检查将确保在它们污染更广泛的数据系统之前捕捉到这些问题。
一旦发现问题,您可以拒绝让这些不良记录流向更远的地方,或在您的管道设计中处理问题。只要您知道数据问题的存在,您就可以警报用户,从而避免做出错误决策。
例如,当您从源接收客户数据文件时,建议进行完整性检查。这将确保必要的字段,如 last_name、date_of_birth 和 address 完全填充。如果存在缺失数据,则建议丢弃那些记录,不用进行分析。或者,您可以为缺少的信息添加默认记录。例如,您可以将 01/01/1800 作为默认的 date_of_birth,这将帮助您识别缺少关键信息的记录,从而在分析过程中促进更好的决策。
2. 修复现有表中的数据问题
随着时间的推移,由于缺乏治理流程,数据质量逐渐下降。一些键被回收,重复信息被添加,或应用了补丁,这使情况变得更糟。
简单的数据概要可以提供给定表中数据的当前状态。现在,关注具有这些问题的核心属性/列。关键是尽可能地隔离问题。一旦确定了属性,应用一次性修复。例如,如果数据重复,与数据管理员协商如何得到一个单一的记录。如果数据不准确,如出生日期、开始和结束日期等,则协商正确的替换并应用修复。
一旦应用了修复,您必须将此过程操作化,以避免数据质量进一步恶化。这个清理工作可以每天运行,通过运行更新语句来修复数据。或者可能是通过终端用户评估审核表的手动干预。
例如,如果您的客户数据表具有重复的客户记录,可以使用数据质量工具对数据进行概要分析。这将帮助您识别重复项并确定其原因。重复可能是由于源多次发送相同的信息、糟糕的数据管道代码或业务流程引起的。一旦确定了重复项及其根本原因,您可以合并记录或删除冗余记录。如果不能解决根本原因,可以设置一个清理作业,定期执行重复检查,匹配客户,合并他们,并删除冗余记录(主数据管理)。
3. 重新创建设计不良的数据管道
数据问题有时可以源于设计不良或效率低下的数据管道。您可以通过重新评估和重构这些管道来增强数据流、转换和集成过程。
设计不良的管道可能会受到瓶颈的影响,从而降低数据的及时处理,或者复杂的数据转换和集成过程可能会引入错误和不一致性。分析管道对于隔离问题并应用修复至关重要。
对于瓶颈,可以重新设计管道以在多个节点上执行;对于数据转换问题,可以将管道分解成各个阶段(避免冗余连接、多次查询大型表等)以减少总体复杂性。
例如,如果您的客户数据表更新时间过长,通过分解其组件来评估管道将会很有帮助。经过仔细检查,您会发现管道设计由于依赖于多个表、引用查找和生成主记录输出而变得复杂。为了提高性能并隔离问题,建议设计和测试每个管道组件。这个过程可能会揭示特定的表连接需要比预期更长的时间。在这一点上,您可以检查表格并确定它是否执行笛卡尔(交叉)连接或由于连接设计而读取多次。一旦您确定了问题,进一步分解并删除这些连接或创建其他分段表以简化管道。
4. 利用数据可视化仪表板
解决问题的难点在于首先找到它们。您会听到厂商的常规介绍,称他们的技术是单独解决数据问题的下一个最佳选择。事实上,您需要一个地方来可视化问题。
一个简单的数据概要和一个更简单的仪表板,显示异常值、间隙、不一致性和偏斜,就能完成工作。在展示客户交易金额随时间变化的散点图中,可以轻松识别表示异常大交易的异常数据点。
表示每天网站流量的线状图显示突然下降或零活动期间,可能表示缺少数据点或数据发生了巨大变化。
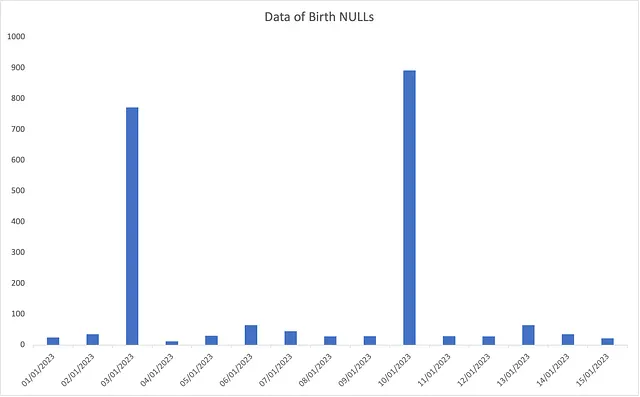
例如,如果您的表中存在客户数据不完整的问题,请考虑使用可视化仪表板来突出显示特定列(如出生日期)中的空值。每日柱状图可以跟踪此属性并检测数据中的任何突然峰值,如下所示。
5. 用于检测和解决的机器学习
随着自动化时代的进步,机器学习可用于提高数据质量。通过对历史数据进行模型训练,机器学习算法可以学习模式和异常,实现自动识别和解决数据问题。
机器学习还可以通过识别和纠正常见的数据问题来自动化数据清理过程。例如,模型可以填补缺失值、更正格式错误或标准化不一致的数据。
例如,可以使用历史客户数据表训练集创建异常检测模型。该模型基于训练数据的分布和统计属性学习正常出生日期的模式和特征。模型使用训练数据在“出生日期”列上建立一个正常阈值。这个阈值通常基于观察训练数据集中出生日期的平均值、标准差或范围等统计量。模型在异常检测阶段评估新的客户记录并将其出生日期与建立的正常阈值进行比较。如果出生日期超出了阈值或与预期模式明显偏离,则会被标记为异常。
结论
投资解决数据问题将为所有下游分析和人工智能用例带来回报。垃圾输入将导致垃圾输出。这五种方法应该能帮助您开始解决数据问题的旅程。
但是,如果您想了解如何实现数据质量的所有核心方面,请查看我的《终极数据质量手册》。
终极数据质量手册
解锁数据的力量:终极数据质量手册是实现数据卓越的综合指南…
hanzalaqureshi.gumroad.com
如果您尚未订阅小猪AI,请考虑使用我的推荐链接订阅。它比 Netflix 更便宜,而且客观上是更好的时间利用方式。如果您使用我的链接,我将获得一小部分佣金,而您将获得在小猪AI上无限阅读的权限,双赢。






