窗口函数:数据工程师和数据科学家必备知识
回到基础 | 揭秘SQL窗口函数

过去几年中,数据增长非常迅猛,尽管我们拥有各种各样的工具和技术,但 SQL 仍然是大多数工具的核心。它是数据分析的基本语言,被各种规模的公司广泛使用,用于解决与数据相关的问题。
我始终相信,你不需要仅仅为了通过面试或解决某个特定问题而掌握某些概念。如果你关心学习这些概念和底层架构,它将帮助你在任何地方都能胜任工作。窗口函数有点棘手,一开始可能会让人感到有些害怕,但一旦掌握了它,就会觉得非常有趣。
如果你熟悉 SQL 聚合函数,那么理解窗口函数的概念会更容易。聚合函数对一组值执行计算并返回一个值;当与 GROUP BY 子句配对使用时,它返回每个组的单个值。你可以在这里阅读更多相关信息:
为你的下一次数据科学面试准备的SQL聚合函数
回到基础 | 面向初学者的SQL基础知识
towardsdatascience.com
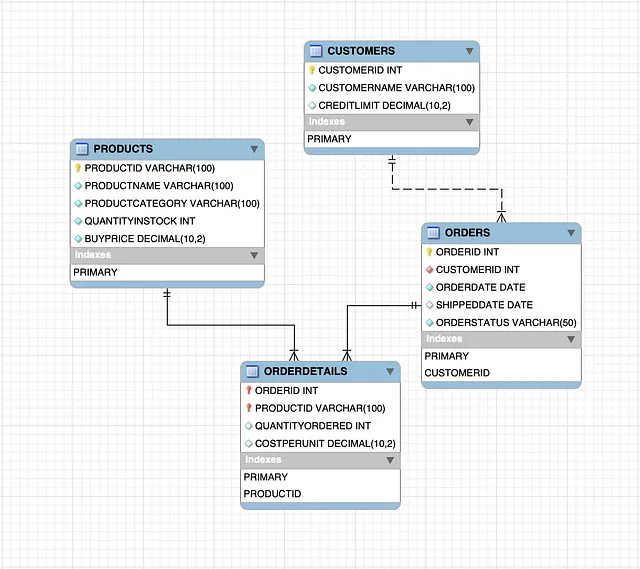
在继续之前,让我向你介绍示例数据库。我们将使用来自虚构车辆零售公司的数据,你可以在我的 GitHub 存储库中找到源数据,
什么是窗口函数?
传统的窗口函数定义是:
窗口函数在与当前行有关的一组表行上执行计算。
如果我把它分解一下,窗口函数使我们能够针对分区执行计算。分区只是用户定义的一组行的子集、子组或桶,窗口函数将在此集合上执行计算。
它们也被广泛称为分析函数。
为什么需要窗口函数?
我们知道,聚合函数将多个行的数据汇总成单个行(如果与 GROUP BY 子句一起使用,则为每个组一个单独的行);而窗口函数也对一组行执行计算,但与聚合函数不同的是,它们不会将结果集汇总成一个单独的行。相反,所有行都保持其原始形式/身份,计算出的行将为每行添加到结果集中。
听起来很有趣,对吧?让我们来分解一下。这是来自 PRODUCTS 表的样本数据:
--查询PRODUCTS表SELECT * FROM PRODUCTS LIMIT 10;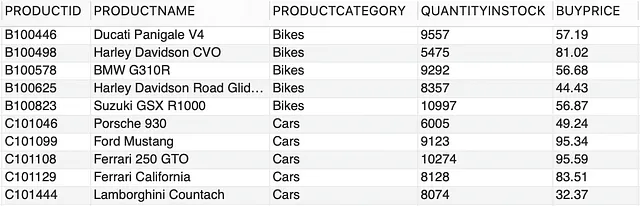
假设我们需要每个 PRODUCTCATEGORY 的平均购买价格的信息,
--每个产品类别的平均购买价格SELECT PRODUCTCATEGORY, FORMAT(AVG(BUYPRICE),2) AS AVERAGE_BUYPRICEFROM PRODUCTSGROUP BY PRODUCTCATEGORY;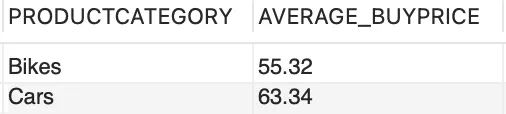
现在,这些信息单独来看并没有什么用。是的,现在你知道每个 PRODUCTCATEGORY 的平均购买价格,但下一步呢?这些信息如何产生商业洞察力?如果我想将每个产品的购买价格与特定 PRODUCTLCATEGORY 的平均购买价格进行比较怎么办?让我重新表述一下我的新需求,
- 显示 PRODUCTCATEGORY 中每个产品的购买价格以及该 PRODUCTCATEGORY 的平均购买价格。
- 将结果集按 PRODUCTCATEGORY 分组排列。
您能仅通过常规的聚合函数实现此功能吗?上述要求希望显示一些信息(例如 PRODUCTCATEGORY、PRODUCTNAME、原始格式的 BUYPRICE),并额外添加一个新列,显示每个 PRODUCTCATEGORY 的平均购买价格。这就是英勇的窗口函数所发挥的作用,
--使用窗口函数SELECT PRODUCTCATEGORY, PRODUCTNAME, BUYPRICE, FORMAT(AVG(BUYPRICE) OVER (PARTITION BY PRODUCTCATEGORY),2) AS AVERAGE_BUYPRICEFROM PRODUCTS; 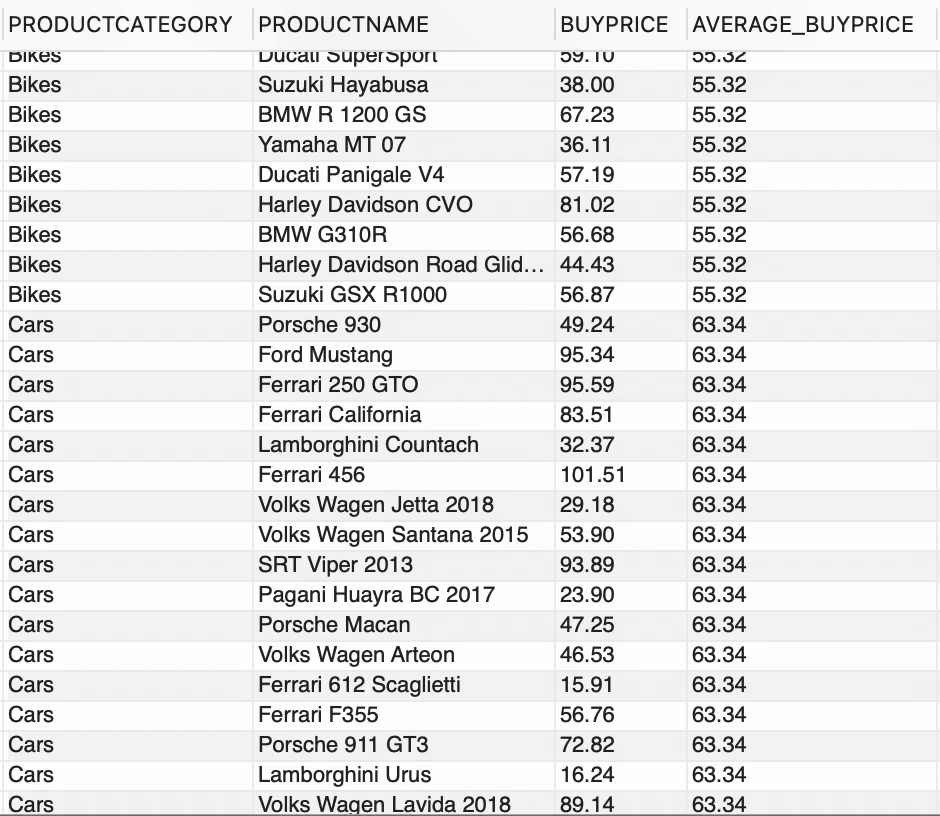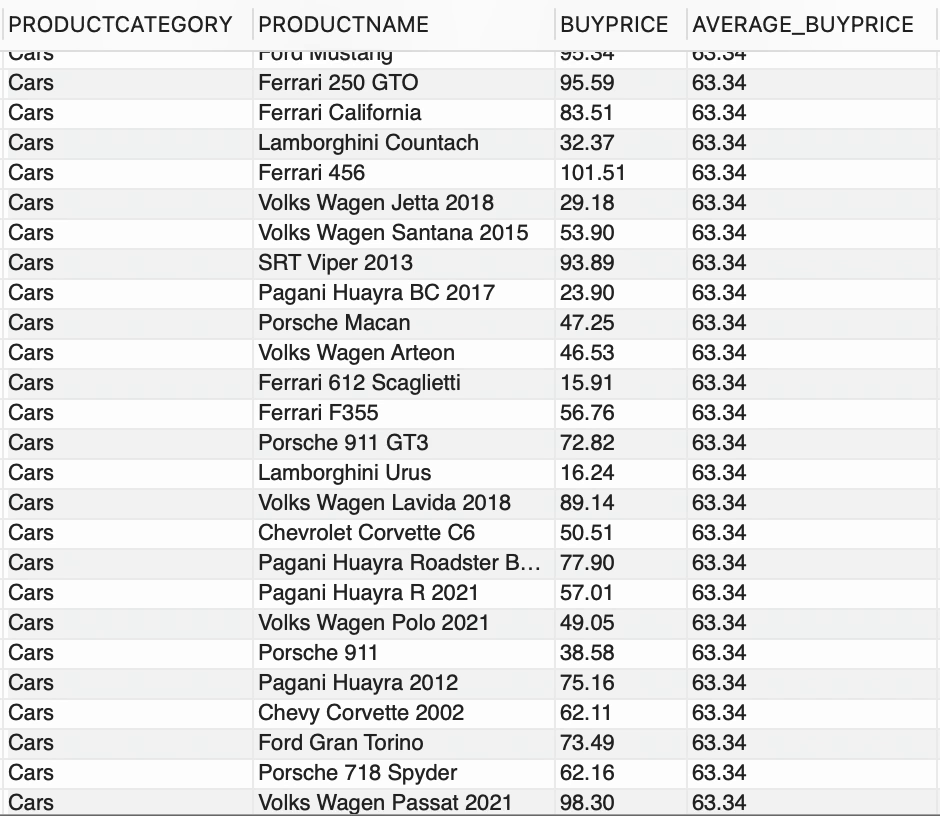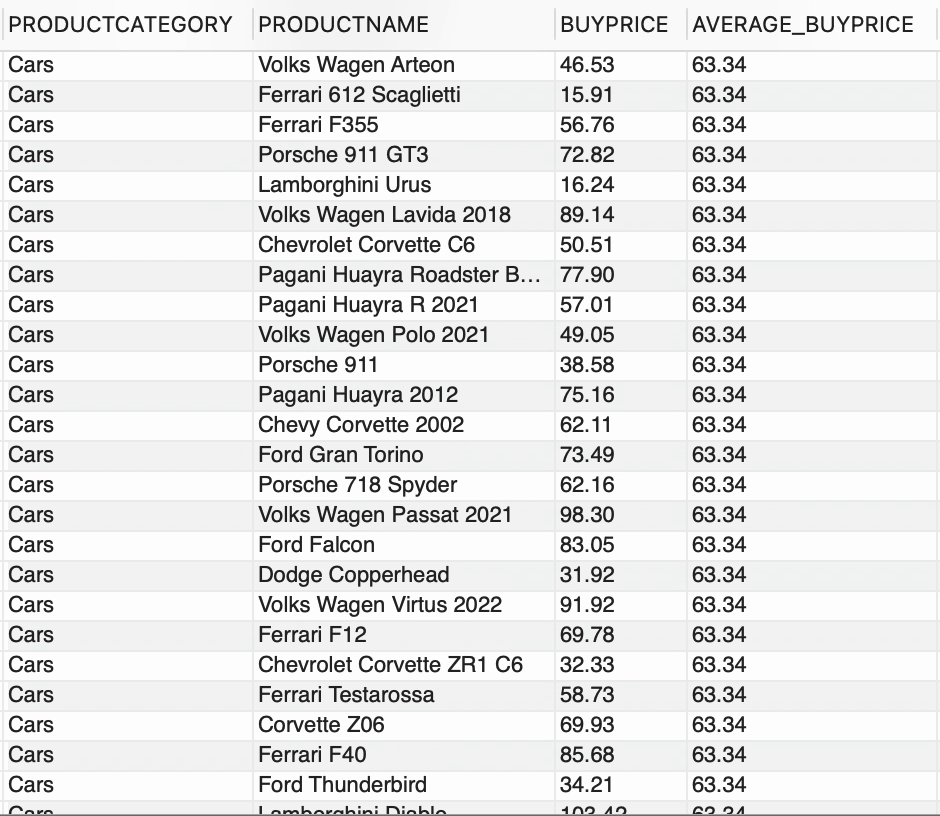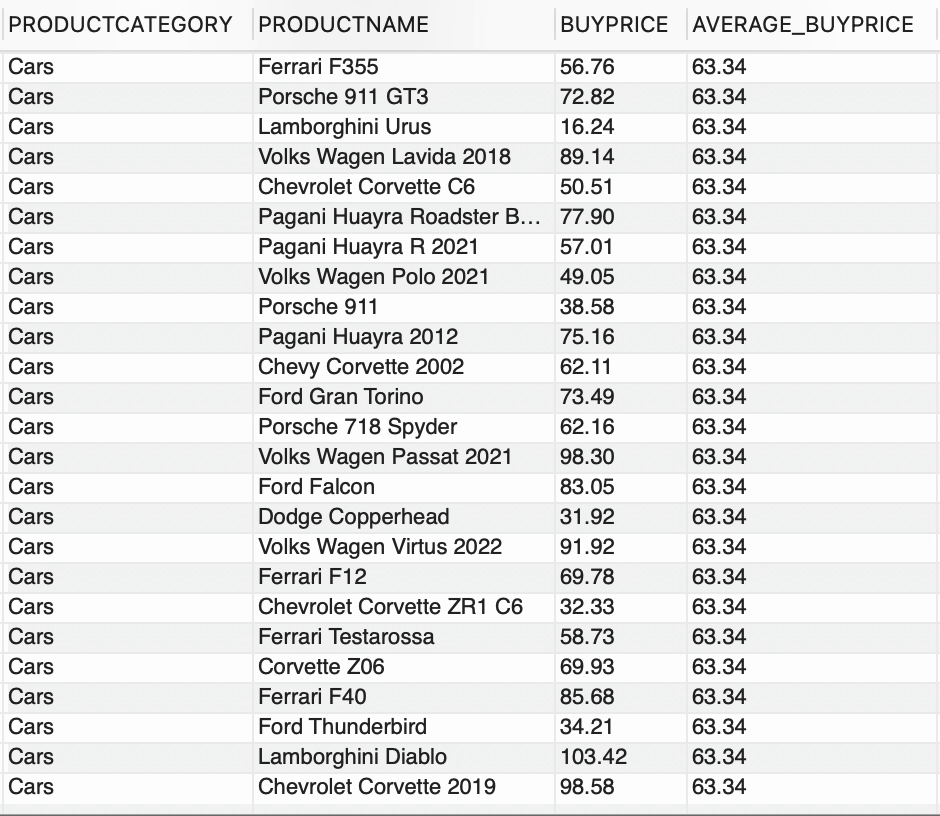
在我们开始使用常用的窗口函数之前,让我们先了解与之配对的基本语法和子句。
窗口函数的一般语法为:

其中,
- OVER() 子句定义了用户特定的行集。窗口函数仅对该特定集合执行计算。它专门用于窗口函数,但也可以与聚合函数一起使用,就像我们在上面使用 AVG() 函数一样,并通过这样做将其转换为窗口函数。如果您没有在 OVER() 中提供任何内容,则窗口函数将应用于整个结果集。
- PARTITION BY 与 OVER 子句一起使用。它将查询结果集分成分区,然后窗口函数对每个分区应用。它是可选的,因此,如果您未指定 PARTITION BY 子句,则该函数将所有行视为单个分区。
- ORDER BY 子句用于在结果集的每个分区内按升序或降序排序结果集。默认情况下,它按升序排序。
- ROWS/RANGE 是 FRAME 子句的一部分,用于定义分区内的子集。
您可以在这里阅读有关窗口函数与聚合函数以及窗口函数子句的详细比较:SQL 窗口函数解剖。
现在我们已经熟悉窗口函数的基本结构,让我们来探索最常用的一种:
ROW_NUMBER()
ROW_NUMBER() 为表中的每一行或分区分配一个连续的整数号码(如果我们使用 PARTITION BY 子句)。通用语法为:
ROW_NUMBER() OVER ([PARTITION BY 子句] [ORDER BY 子句])
这是来自 PRODUCTS 表的示例数据,它包含车辆零售商提供的一系列产品的数据。
--查询 PRODUCTS 表SELECT * FROM PRODUCTS LIMIT 10;让我们从基础开始,
--为表中的每一行分配行号SELECT *, ROW_NUMBER() OVER() AS ROW_NUMFROM PRODUCTS;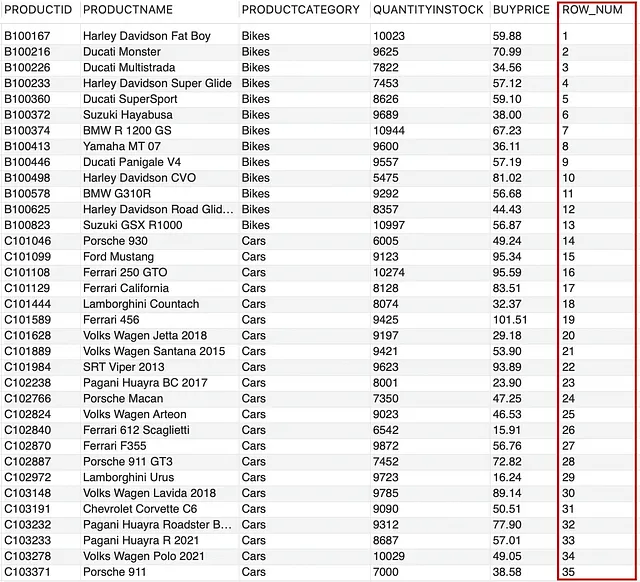
这里,ROW_NUMBER() 为 PRODUCTS 表的每一行分配了一个从 1 开始的连续整数号码。让我们再进一步,为每个 PRODUCTCATEGORY 添加行号,为此,我们必须使用 PARTITION BY 子句。
--按 productcategory 排序的行号SELECT *, ROW_NUMBER() OVER(PARTITION BY PRODUCTCATEGORY) AS ROW_NUMFROM PRODUCTS;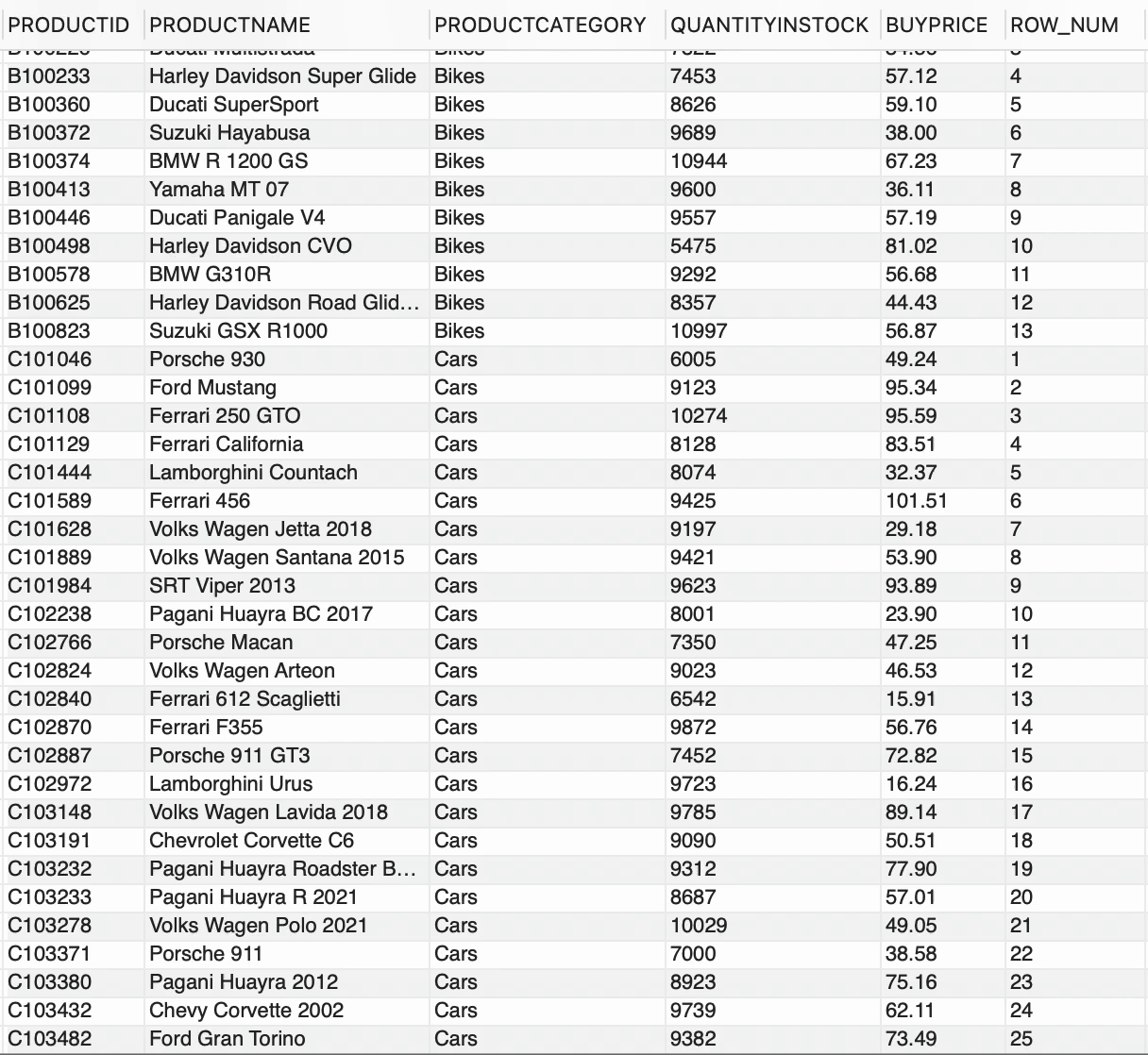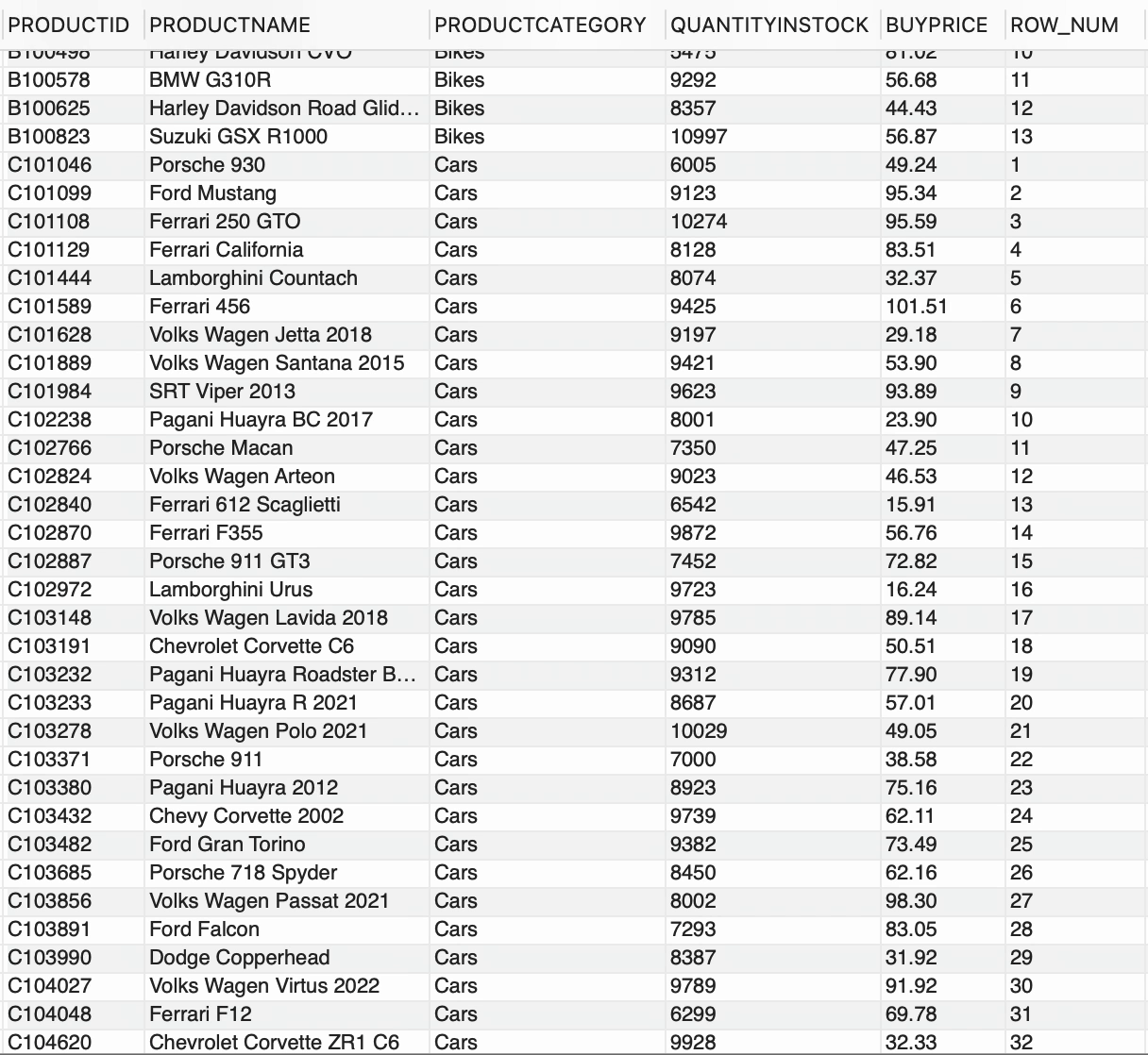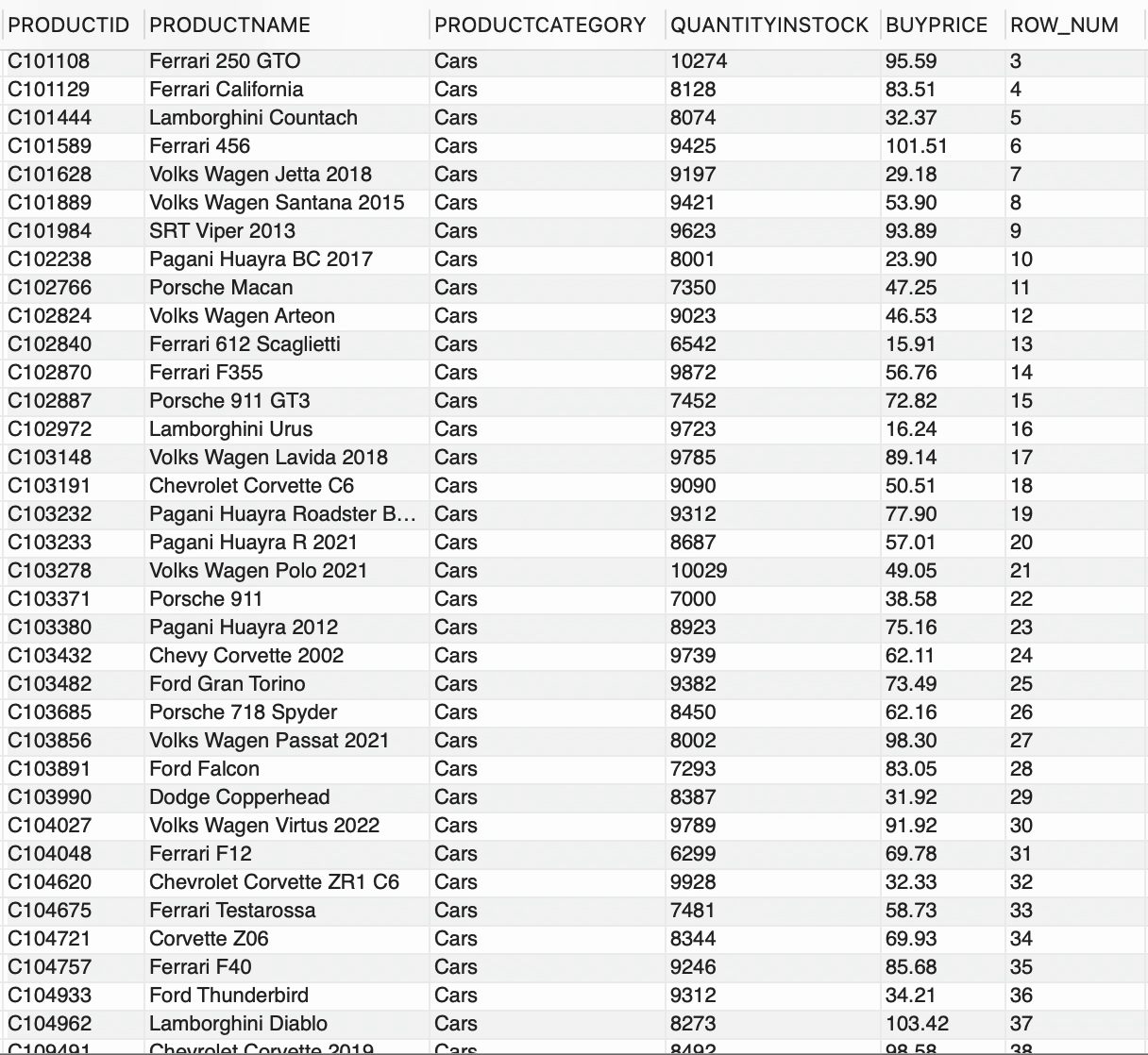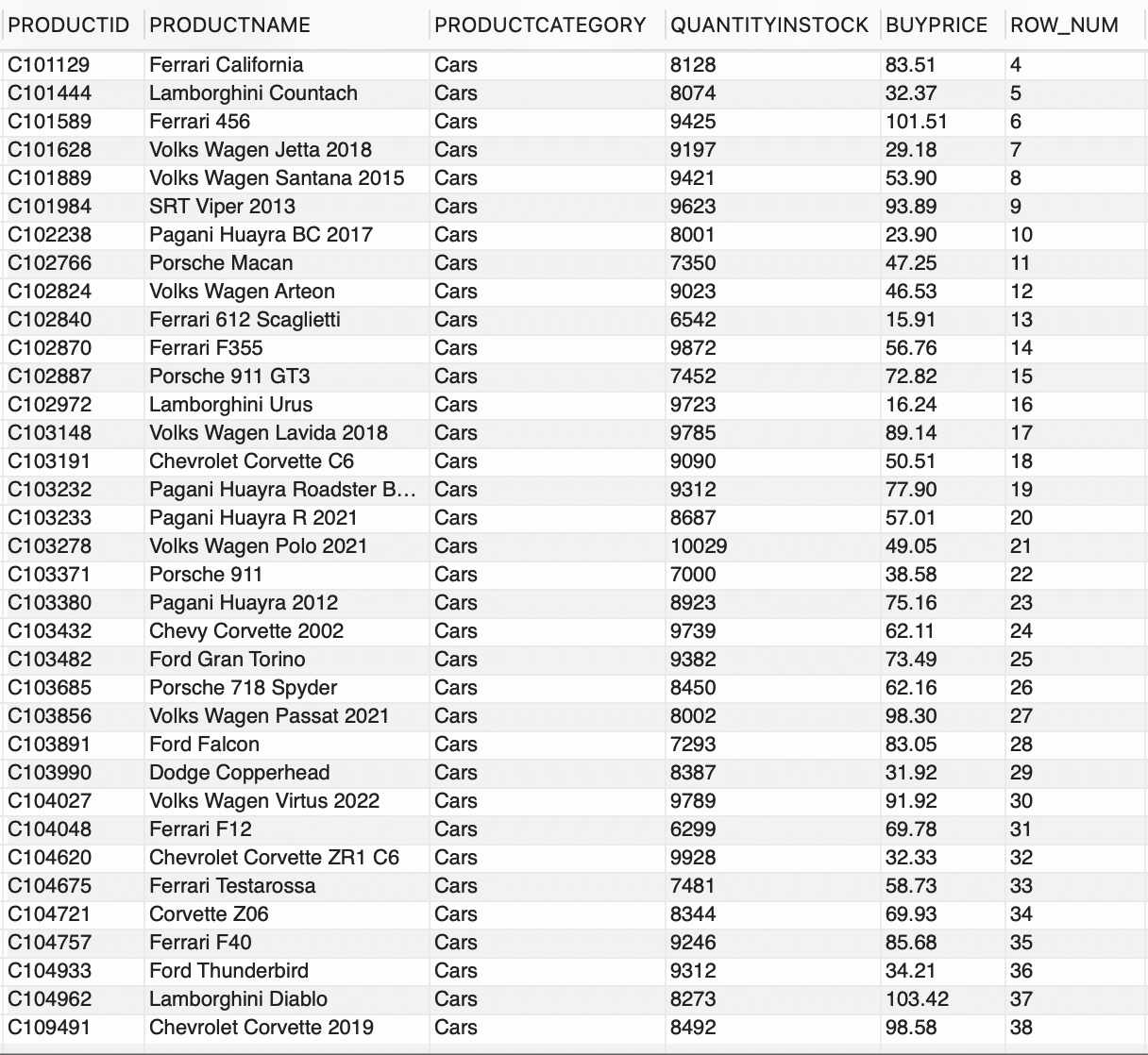
我们在PRODUCTS表中有两个不同的PRODUCTCATEGORY可用,
ROW_NUMBER()为每行生成一个顺序整数号码,PARTITION BY子句基于PRODUCTCATEGORY将结果集分成桶。因此,ROW_NUMBER()与OVER和PARTITION BY子句一起,为每个PRODUCTCATEGORY生成了一个唯一的数字序列。
现在,让我们也利用ORDER BY子句。这也是入门/中级层面最常问的面试问题之一。例如,我们想知道每个PRODUCTCATEGORY中库存数量最高的前3个产品。
--每个产品类别中具有最高数量的前3个产品WITH PRODUCT_INVENTORY AS(SELECT PRODUCTCATEGORY, PRODUCTNAME, QUANTITYINSTOCK, ROW_NUMBER() OVER (PARTITION BY PRODUCTCATEGORY ORDER BY QUANTITYINSTOCK DESC) AS ROW_NUMFROM PRODUCTS)SELECT PRODUCTCATEGORY, PRODUCTNAME, QUANTITYINSTOCK, ROW_NUM AS TOP_3_PRODUCTSFROM PRODUCT_INVENTORYWHERE ROW_NUM <= 3;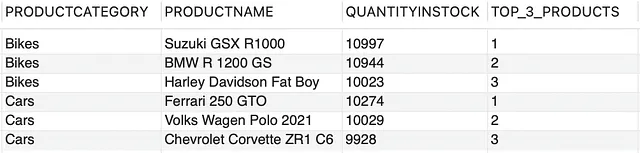
首先,让我们将整个查询分解为两个部分,如下图所示。首先,我们正在创建一个PRODUCT_INVENTORY。表数据将被划分为每个PRODUCTCATEGORY的分区/组,按照每个产品类别中库存量的降序排序。随后,ROW_NUMBER()将为每个分区生成顺序整数号码。这里很酷的部分是,每个行的行号在每个PRODUCTCATEGORY中都被重置。
上述查询将返回以下结果,

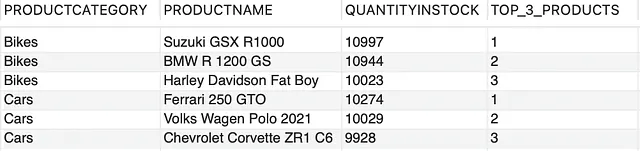
现在我们的查询的第二部分非常简单。它将使用此结果集作为输入,并根据条件ROW_NUM ≤ 3从每个PRODUCTCATEGORY中选择前3个产品。最终结果如下所示,

这将导致我们的最终结果为,
RANK()
顾名思义,RANK()为表中的每行或每个分区的每行分配一个排名。一般语法是,
RANK() OVER ([PARTITION BY子句] [ORDER BY子句])
继续我们的PRODUCTS表示例,让我们根据每个PRODUCTCATEGORY中可用库存的数量,按照降序为产品分配一个排名。
--为每个产品类别生成排名SELECT PRODUCTCATEGORY, PRODUCTNAME, QUANTITYINSTOCK, RANK() OVER (PARTITION BY PRODUCTCATEGORY ORDER BY QUANTITYINSTOCK DESC) AS "RANK"FROM PRODUCTS;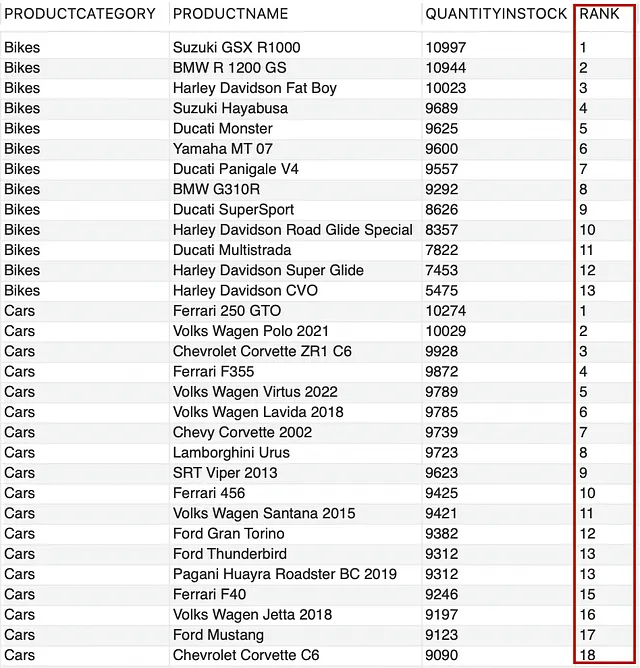
为了演示目的,我已经限制了结果集。现在,不要混淆 ROW_NUMBER() 和 RANK()。它们的结果集可能看起来很相似,但是它们之间有区别。ROW_NUMBER() 为表或分区的每一行分配一个唯一的顺序整数号码;而 RANK() 也为表或分区的每一行生成一个顺序整数号码,但是它为具有相同值的行分配相同的排名。
让我们通过一个例子来理解。这是来自 CUSTOMERS 表的样本数据:
-- sample data from table customersSELECT CUSTOMERID, CUSTOMERNAME, CREDITLIMITFROM CUSTOMERSLIMIT 10; 
在以下演示中,我已经为 CUSTOMERS 表生成了按其 CREDITLIMIT 降序排序的 ROW_NUMBER() 和 RANK()。
--row_number() and rank() comparisonSELECT CUSTOMERID, CUSTOMERNAME, CREDITLIMIT, ROW_NUMBER() OVER (ORDER BY CREDITLIMIT DESC) AS CREDIT_ROW_NUM, RANK() OVER (ORDER BY CREDITLIMIT DESC) AS CREDIT_RANKFROM CUSTOMERS;
为了演示目的,我已经限制了结果集。绿色部分是 ROW_NUMBER(),蓝色部分是 RANK()。
现在,如果您参考红色标记的三个记录,这就是两个函数结果集不同的地方;ROW_NUMBER() 为所有行生成了唯一的顺序整数号码。但是另一方面,RANK() 为 CUSTOMERID 为 239 和 321 的行分配了相同的排名,即 20,因为它们具有相同的信用额度,即 105000.00。不仅如此,对于下一个记录,即 CUSTOMERID 为 458,它跳过了排名 21,并将其分配为排名 22。
DENSE_RANK()
现在如果您想知道,既然我们已经配备了 RANK(),为什么还需要 DENSE_RANK() 呢?正如我们在上一个例子中所见,RANK() 为具有相同值的行生成相同的排名,然后跳过下一个连续的排名(请参考上面的图像)。
DENSE_RANK() 与 RANK() 类似,除了这一个区别,它在排列行时不跳过任何排名。常见的语法是:
DENSE_RANK() OVER ([PARTITION BY clause] [ORDER BY clause])
回到 CUSTOMERS 表,让我们比较 RANK() 和 DENSE_RANK() 的结果集:
--dense_rank() and rank() comparisonSELECT CUSTOMERID, CUSTOMERNAME, CREDITLIMIT, RANK() OVER (ORDER BY CREDITLIMIT DESC) AS CREDIT_RANK, DENSE_RANK() OVER (ORDER BY CREDITLIMIT DESC) AS CREDIT_DENSE_RANKFROM CUSTOMERS;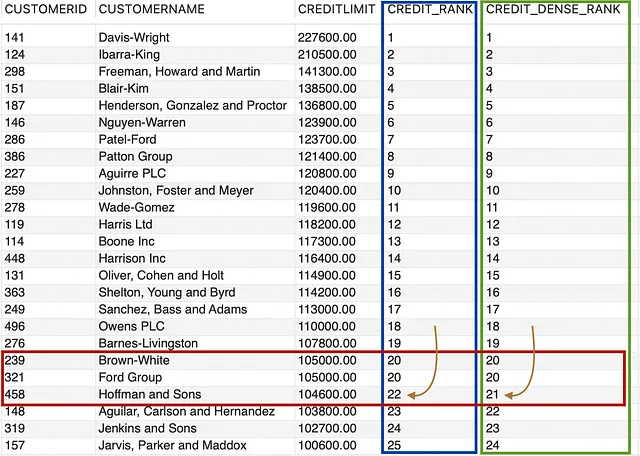
与 RANK()(蓝色部分)类似,DENSE_RANK()(绿色部分)为 CUSTOMERID 为 239 和 321 的行生成了相同的排名,但是 DENSE_RANK() 做的不同之处在于,它保持了顺序并为 CUSTOMERID 为 458 的行分配了 21 排名。
NTH_VALUE()
这个函数与我们到目前为止讨论的有些不同。NTH_VALUE()将返回指定窗口中表达式的第N行的值。常见的语法是:
NTH_VALUE(expression, N) OVER ([PARTITION BY clause] [ORDER BY clause] [ROW/RANGE clause])
‘N’必须是正整数值。如果数据不存在于第N个位置,函数将返回NULL。如果您注意到,我们在语法中有一个额外的子句,即ROW/RANGE子句。
RAW/RANGE是窗口函数中Frame Clause的一部分,它定义了窗口分区中的一个子集。ROW/RANGE定义了相对于当前行的起始和结束点,您将当前行的位置作为基准点,并以此参考来定义分区内的框架。
- ROWS – 通过指定在当前行之前或之后的行数来定义框架的开始和结束。
- RANGE – 与ROWS相反,RANGE指定与当前行的值相比较的值范围,以定义分区内的框架。
通用语法是:
{ROWS | RANGE} BETWEEN <frame_starting> AND <frame_ending>

每当您使用ORDER BY子句时,它将默认框架设置为:
{ROWS/RANGE} BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
如果没有ORDER BY子句,则默认框架为:
{ROWS/RANGE} BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
目前可能看起来有点多,但无需记忆语法和其含义,只需练习即可!您可以在此处阅读详细的Frame Clause及其大量示例:
SQL窗口函数的解剖
回到基础 | SQL入门基础
towardsdatascience.com
现在假设我们需要找出每个PRODUCTCATEGORY的PRODUCTNAME和第二高的买价,
--每个PRODUCTCATEGORY的PRODUCTNAME和第二高的买价SELECT PRODUCTNAME, PRODUCTCATEGORY, BUYPRICE, NTH_VALUE(PRODUCTNAME,2) OVER(PARTITION BY PRODUCTCATEGORY ORDER BY BUYPRICE DESC) AS SECOND_HIGHEST_BUYPRICEFROM PRODUCTS;
我们有另外两个类似于NTH_VALUE()的值函数; FIRST_VALUE()和LAST_VALUE()。正如名称所示,它们分别基于用户表达式从排序列表中返回最高(第一个)和最低(最后一个)值。常见的语法是:
FIRST_VALUE(expression) OVER ([PARTITION BY clause] [ORDER BY clause] [ROW/RANGE clause])
LAST_VALUE(expression) OVER ([PARTITION BY clause] [ORDER BY clause] [ROW/RANGE clause])
与上面的示例类似,您现在可以找出每个PRODUCTCATEGORY的最高和最低买价的PRODUCTNAME了吗?
NTILE()
有时候,您希望将分区内的行排列到一定数量的组或桶中。NTILE()用于此目的,它将分区中的有序行分成特定数量的桶。每个这样的桶都被分配一个从1开始的组号。它将尝试尽可能创建大小相等的组。对于每行,NTILE()函数返回表示该行所属组的组号。
通用语法为,
NTILE(N) OVER ([PARTITION BY clause] [ORDER BY clause])
其中‘N’是一个正整数,用于定义要创建的组数。
例如,我们想将PRODUCTCATEGORY-‘Cars’分成三组,以便我们有一个高价位、中价位和低价位购买价格的汽车列表。
--将'Cars'按高价位、中价位和低价位购买价格分组SELECT PRODUCTNAME, BUYPRICE, NTILE(3) OVER (ORDER BY BUYPRICE DESC) AS BUYPRICE_BUCKETSFROM PRODUCTSWHERE PRODUCTCATEGORY = 'Cars';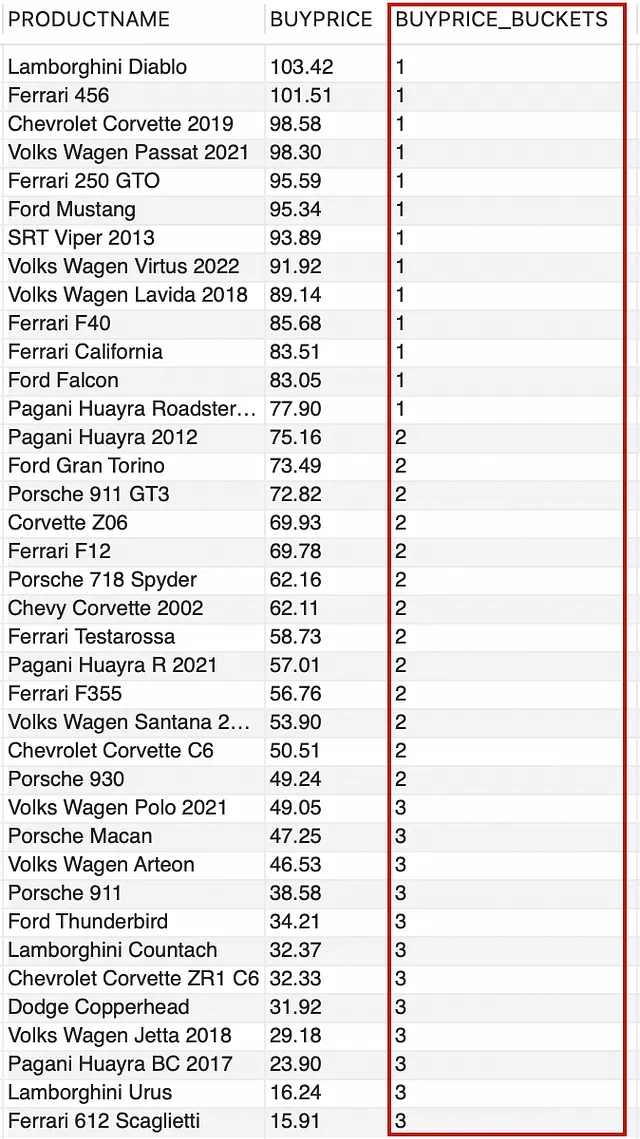
LAG() & LEAD()
我们经常遇到需要进行某种比较分析的情况。例如,将所选年份的销售额与上一年或下一年进行比较。当处理时间序列数据并计算跨时间的差异时,这样的比较非常有用。
LAG()从前面的行中获取数据。如果没有前面的行,则返回NULL。通用语法为,
LAG(expression, offset) OVER ([PARTITION BY clause] [ORDER BY clause])
LEAD()从后面的行获取数据。如果没有后续行,则返回NULL。通用语法为,
LEAD(expression, offset) OVER ([PARTITION BY clause] [ORDER BY clause])
其中偏移量是可选的,但是在使用时,其值必须为0或正整数,
- 当指定为0时,LAG()和LEAD()会为当前行评估表达式。
- 当省略时,默认为1,即将前一行或后一行作为当前行。
--每个产品类别的年度总销售额WITH YEARLY_SALES AS(SELECT PROD.PRODUCTCATEGORY, YEAR(ORDERDATE) AS SALES_YEAR, SUM(ORDET.QUANTITYORDERED * ORDET.COSTPERUNIT) AS TOTAL_SALESFROM PRODUCTS PRODINNER JOIN ORDERDETAILS ORDET ON PROD.PRODUCTID = ORDET.PRODUCTIDINNER JOIN ORDERS ORD ON ORDET.ORDERID = ORD.ORDERIDGROUP BY PRODUCTCATEGORY, SALES_YEAR )SELECT PRODUCTCATEGORY, SALES_YEAR, LAG(TOTAL_SALES) OVER (PARTITION BY PRODUCTCATEGORY ORDER BY SALES_YEAR) AS LAG_PREVIOUS_YEAR, TOTAL_SALES, LEAD(TOTAL_SALES) OVER (PARTITION BY PRODUCTCATEGORY ORDER BY SALES_YEAR) AS LEAD_FOLLOWING_YEARFROM YEARLY_SALES;这里,我们首先使用CTE(公共表达式)获取每个PRODUCTCATEGORY按年份划分的总销售数据。然后,我们使用LAG()和LEAD()将按PRODUCTCATEGORY分区并按SALES_YEAR排序的总销售数据,分别获取前一年和后续日历年的数据。

结论
窗口函数在多种分析数据的方式中非常有用。不同的SQL版本可能有稍微不同的实现方式,因此最好参考特定SQL版本的官方文档。以下是一些资源,供您开始使用,
- 窗口函数的解剖
- 窗口函数的概念和语法
- MySQL窗口函数限制
- SQL窗口函数速查表
如果您记得某些东西非常好,那么您一定练习得很好,
- HackerRank或LeetCode练习基本/中级/高级SQL问题。
成为会员,阅读小猪AI上的所有故事。
愉快学习!