AWS中多模型终端的CI/CD
一种简单、灵活的可持续机器学习解决方案的替代方案

自动化生产机器学习解决方案的重新训练和部署是确保模型考虑到协变量偏移的关键步骤,同时限制容易出错和不必要的人力投入。
对于使用AWS堆栈,特别是SageMaker部署的模型,AWS提供了一种标准的CI/CD解决方案,使用SageMaker Pipelines自动重新训练/部署,以及SageMaker Model Registry跟踪模型的血统。
尽管标准解决方案对于标准情况很有效,但对于更复杂的情况存在几个限制:
- 输入数据需要来自AWS s3。
- 设置动态热启动超参数调整的难度较大。
- 需要进行额外的模型训练步骤以训练多个模型。
- 执行管道的引导时间较长。
- 调试工具有限。
幸运的是,AWS推出了可以用于构建CI/CD管道的新功能,该功能克服了这些限制。以下功能可以在SageMaker Studio中访问,这是AWS面向机器学习的集成开发环境:
- 新兴能力揭示:只有成熟的AI像GPT-4才能自我改进吗?探索语言模型自主增长的影响
- 逐步解释和可视化的循环神经网络
- 通过MINILLM揭示人工智能的潜力:深入探讨从更大的语言模型到更小的对应模型的知识蒸馏
- 使用自定义SageMaker图像
- Git/SageMaker Studio集成
- 动态热启动超参数调整
- SageMaker Studio笔记本作业
- 跨帐户模型注册表
本文的目的是…
概述通过AWS云的替代CI/CD解决方案的关键细节,提供更灵活和更快的上市速度。
解决方案组件概述:
1. 用于PostgreSQL查询的自定义SageMaker Studio映像
2. 动态热启动超参数调整
3. 在单个交互式Python笔记本中将多个模型注册到模型注册表中
4. 使用新模型刷新多模型端点
5. 安排重新训练/重新部署笔记本以在一组节奏上运行
让我们开始吧。
1. 用于PostgreSQL查询的自定义SageMaker Studio映像
虽然SageMaker管道允许从s3获取输入数据,但如果新的输入数据位于像AWS Redshift或Google BigQuery这样的数据仓库中,该怎么办呢?当然,可以使用ETL或类似的过程将数据批量移动到s3中,但与在管道中直接查询数据相比,这只会增加不必要的复杂性/刚性。
SageMaker Studio提供了几个默认映像来初始化环境,其中一个示例是“Data Science”,其中包括常见的包如numpy和pandas。但是,要在Python中连接到PostgreSQL数据库,需要一个驱动程序或适配器。Psycopg2是Python编程语言中最受欢迎的PostgreSQL数据库适配器。幸运的是,可以使用自定义映像来初始化Studio环境,尽管有特定的要求。我已经打包好了一个满足这些要求的Docker映像,并在Python Julia-1.5.2映像的基础上添加了psycopg2驱动程序。该映像可以在此git存储库中找到。然后可以使用这里概述的步骤使映像在Studio域中可访问。
2. 动态热启动超参数调整
模型重新训练与初始模型训练的性质不同。在重新训练模型时,投入相同的资源来搜索最佳模型超参数并在同样大的搜索空间中进行搜索并不实用。特别是当预计从上一个生产模型中仅进行最小调整以获得最佳超参数时,这一点尤为真实。
因此,在本文推荐的CI/CD中推荐使用的超参数调整解决方案不会尝试使用K折交叉验证、热池等方式来进行重新调整。所有这些都可以在初始模型训练中非常有效。但是,对于重新训练,我们希望从已经在生产中表现良好的模型开始,并对新可用数据进行小的调整。因此,使用动态热启动超参数调整是完美的解决方案。进一步地,可以创建一个动态热启动调整系统,该系统使用最新的生产调整作为父调整。例如,对于XGBoost贝叶斯调整作业,解决方案可以如下所示:
# 设置运行参数
testing=False
hyperparam_jobs=10
# 设置最大作业数
if testing==False:
max_jobs=hyperparam_jobs
else:
max_jobs=1
# 加载包
from sagemaker.xgboost.estimator import XGBoost
from sagemaker.tuner import IntegerParameter
from sagemaker.tuner import ContinuousParameter
from sagemaker.tuner import HyperparameterTuner
from sagemaker.tuner import WarmStartConfig, WarmStartTypes
# 配置热启动
number_of_parent_jobs=1 # 可以多达5个,但代码中目前仅支持1个
# 注意需要设置base_dir,也可以留空
try:
eligible_parent_tuning_jobs=pd.read_csv(f"""{base_dir}logs/tuningjobhistory.csv""")
except:
eligible_parent_tuning_jobs=pd.DataFrame({'datetime':[],'tuningjob':[],'metric':[],'layer':[],'objective':[],'eval_metric':[],'eval_metric_value':[],'trainingjobcount':[]})
eligible_parent_tuning_jobs.to_csv(f"""{base_dir}logs/tuningjobhistory.csv""",index=False)
eligible_parent_tuning_jobs=eligible_parent_tuning_jobs[(eligible_parent_tuning_jobs['layer']==prefix)&(eligible_parent_tuning_jobs['metric']==metric)&(eligible_parent_tuning_jobs['objective']==trainingobjective)&(eligible_parent_tuning_jobs['eval_metric']==objective_metric_name)&(eligible_parent_tuning_jobs['trainingjobcount']>1)].sort_values(by='datetime',ascending=True)
eligible_parent_tuning_jobs_count=len(eligible_parent_tuning_jobs)
if eligible_parent_tuning_jobs_count>0:
parent_tuning_jobs=eligible_parent_tuning_jobs.iloc[(eligible_parent_tuning_jobs_count-(number_of_parent_jobs)):eligible_parent_tuning_jobs_count,1].iloc[0]
warm_start_config = WarmStartConfig(WarmStartTypes.TRANSFER_LEARNING, parents={parent_tuning_jobs})
# 注意当适用时,可以使用WarmStartTypes.IDENTICAL_DATA_AND_ALGORITHM
print(f"""使用调整作业进行热启动:{parent_tuning_jobs[0]}""")
else:
warm_start_config = None
# 定义探索边界(Amazon SageMaker文档中推荐的默认值)
hyperparameter_ranges = {
'eta': ContinuousParameter(0.1, 0.5, scaling_type='Logarithmic'),
'max_depth': IntegerParameter(0,10,scaling_type='Auto'),
'num_round': IntegerParameter(1,4000,scaling_type='Auto'),
'subsample': ContinuousParameter(0.5,1,scaling_type='Logarithmic'),
'colsample_bylevel': ContinuousParameter(0.1, 1,scaling_type="Logarithmic"),
'colsample_bytree': ContinuousParameter(0.5, 1, scaling_type='Logarithmic'),
'alpha': ContinuousParameter(0, 1000, scaling_type="Auto"),
'lambda': ContinuousParameter(0,100,scaling_type='Auto'),
'max_delta_step': IntegerParameter(0,10,scaling_type='Auto'),
'min_child_weight': ContinuousParameter(0,10,scaling_type='Auto'),
'gamma':ContinuousParameter(0, 5, scaling_type='Auto'),
}
tuner_log = HyperparameterTuner(
estimator,
objective_metric_name,
hyperparameter_ranges,
objective_type='Minimize',
max_jobs=max_jobs,
max_parallel_jobs=10,
strategy='Bayesian',
base_tuning_job_name="transferlearning",
warm_start_config=warm_start_config
)
# 注意需要实例化SageMaker XGBoost估计器进行高级训练
training_input_config = sagemaker.TrainingInput("s3://{}/{}/{}".format(bucket,prefix,filename), content_type='csv')
validation_input_config = sagemaker.TrainingInput("s3://{}/{}/{}".format(bucket,prefix,filename), content_type='csv')
# 注意需要设置bucket、prefix和filename对象/别名
# 开始超参数调整作业
tuner_log.fit({'train': training_input_config, 'validation': validation_input_config})
# 打印最新超参数调整作业的状态
boto3.client('sagemaker').describe_hyper_parameter_tuning_job( HyperParameterTuningJobName=tuner_log.latest_tuning_job.job_name)['HyperParameterTuningJobStatus']调整作业历史将保存在基础目录的日志文件中,示例如下:
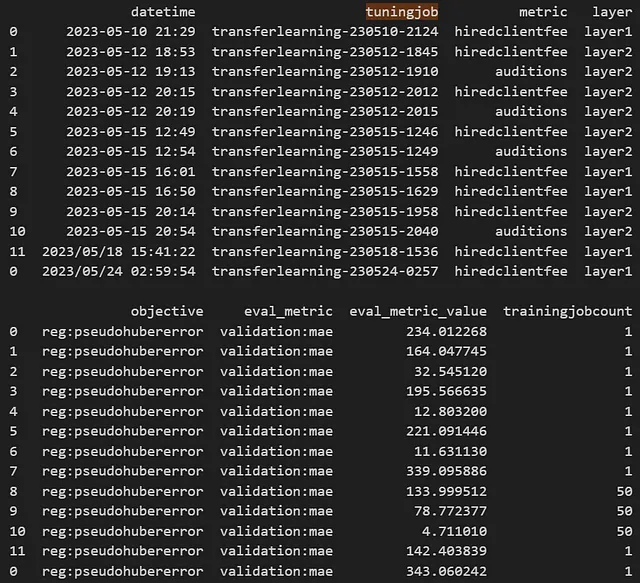
日期/时间戳,调整作业名称和元数据以.csv格式存储,新的调整作业将添加到文件中。
系统将动态热启动,使用满足所需条件的最新调整作业。在本示例中,条件在以下代码行中注明:
eligible_parent_tuning_jobs=eligible_parent_tuning_jobs[(eligible_parent_tuning_jobs['layer']==prefix)&(eligible_parent_tuning_jobs['metric']==metric)&(eligible_parent_tuning_jobs['objective']==trainingobjective)&(eligible_parent_tuning_jobs['eval_metric']==objective_metric_name)&(eligible_parent_tuning_jobs['trainingjobcount']>1)].sort_values(by='datetime',ascending=True)因为我们将要测试流水线是否正常工作,因此提供了一个testing=True运行选项,强制只进行一次超参数调整作业。添加了一个条件,只考虑只有1个调整的模型作为父级的作业,因为这些作业是为了测试。此外,调整作业日志文件可以用于不同的模型,因为理论上可以在模型之间使用父作业。在这种情况下,模型通过“metric”字段进行跟踪,并且符合当前训练实例中的指标的调整作业将被过滤。
完成重新训练后,我们将使用新的超参数调整作业附加日志文件,并将其本地写入,并打开版本控制上传到s3。
# Append Last Parent Job for Next Warm Starteligible_parent_tuning_jobs=pd.read_csv(f"""{base_dir}logs/tuningjobhistory.csv""")latest_tuning_job=boto3.client('sagemaker').describe_hyper_parameter_tuning_job( HyperParameterTuningJobName=tuner_log.latest_tuning_job.job_name)updatetuningjobhistory=pd.concat([eligible_parent_tuning_jobs,pd.DataFrame({'datetime':[datetime.now().strftime("%Y/%m/%d %H:%M:%S")],'tuningjob':[latest_tuning_job['HyperParameterTuningJobName']],'metric':[metric],'layer':prefix,'objective':[trainingobjective],'eval_metric':[latest_tuning_job['BestTrainingJob']['FinalHyperParameterTuningJobObjectiveMetric']['MetricName']],'eval_metric_value':latest_tuning_job['BestTrainingJob']['FinalHyperParameterTuningJobObjectiveMetric']['Value'],'trainingjobcount':[latest_tuning_job['HyperParameterTuningJobConfig']['ResourceLimits']['MaxNumberOfTrainingJobs']]})],axis=0)print(updatetuningjobhistory)# Write locallyupdatetuningjobhistory.to_csv(f"""{base_dir}logs/tuningjobhistory.csv""",index=False)# Upload to s3s3.upload_file(f"""{base_dir}logs/tuningjobhistory.csv""",bucket,'logs/tuningjobhistory.csv')3. 在单个交互式Python笔记本中将多个模型注册到模型注册表中
通常,组织将为不同的用例(即沙盒,QA和生产)拥有多个AWS帐户。您需要确定每个步骤的使用哪个帐户,然后添加本指南中所述的跨帐户权限。
建议是在同一帐户中执行模型训练和模型注册,特别是在沙盒或测试帐户中。因此,在下面的图表中,“数据科学”和“共享服务”帐户将是相同的。在该帐户中,将需要一个s3存储桶来存储模型工件并跟踪与流水线相关的其他文件的血统。模型/端点将通过引用训练/注册帐户中的模型工件和注册表在每个“部署”帐户(即沙盒,QA,生产)中分别部署。
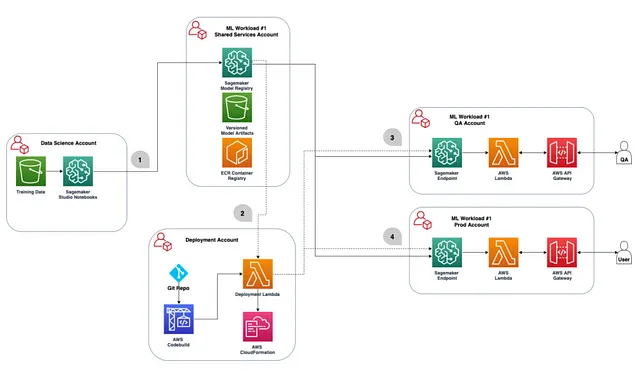
现在,我们已经决定使用哪个AWS帐户进行训练和存储模型注册表,现在可以构建初始模型并开发CI/CD解决方案。
使用SageMaker Pipelines时,为数据预处理、训练/调整、评估、注册和任何后处理创建单独的流水线步骤。虽然对于单个模型管道来说这很好,但在需要多个模型的机器学习解决方案时,它会创建大量的流水线代码重复。
因此,推荐的解决方案是在SageMaker Studio中构建和安排三个交互式Python笔记本。它们按顺序运行,并一起完成CI/CD流水线,一旦使用笔记本作业自动化:
A. 数据准备
B. 模型训练、评估和注册
C. 最新批准模型的端点刷新
A. 数据准备
在这里,我们将从数据仓库查询和加载数据,并将其写入本地和s3。我们可以使用当前日期设置动态日期/时间条件,并将结果日期底部和顶部传递给SQL查询。
# 连接到数据仓库dbname='<insert here>'host='<insert here>'password='<insert here>'port='<insert here>'search_path='<insert here>'user='<insert here>'import psycopg2data_warehouse= psycopg2.connect(f"""host={host} port={port} dbname={dbname} user={user} password={password} options = '-c search_path={search_path}'""")# 设置数据集日期底部和顶部以传递和应用于查询datestart=date(2000, 1, 1)pushbackdays=30dateend=date.today() - timedelta(days=pushbackdays)print(datestart)print(dateend)# 查询数据仓库modelbuildingset=pd.read_sql_query(f"""<insert query>""",data_warehouse)# 写入 .csvmodelbuildingset.to_csv(f"{base_dir}datasets/{filename}", index=False)modelbuildingset# 上传到 s3 以进行血统跟踪s3 = boto3.client('s3')s3.upload_file(f"{base_dir}datasets/{filename}",bucket,f"datasets/{filename}")此步骤结束时,将准备好的训练数据保存在本地以及s3中进行血统跟踪。
B. 模型训练、评估和注册
通过使用Studio中的交互式Python笔记本,我们现在可以在一个笔记本中完成模型训练、评估和注册。所有这些步骤都可以构建成一个函数,并应用于需要重新训练的其他模型。为了说明目的,提供了不使用函数的代码。
在继续之前,需要在注册表中为解决方案中的每个模型创建模型包组(可以在控制台或通过Python创建)。
# 获取最佳训练作业名称best_overall_training_job_name = latest_tuning_job['BestTrainingJob']['TrainingJobName']# latest_tuning_job来自于超参数调整部分latest_tuning_job['BestTrainingJob']# 安装 XGBoost! pip install xgboost# 下载最佳模型s3 = boto3.client('s3')s3.download_file('<s3 bucket>', f"""output/{best_overall_training_job_name}/output/model.tar.gz""", f"""{base_dir}models/{metric}/model.tar.gz""")# 在内存中打开并加载下载的模型工件tar = tarfile.open(f"""{base_dir}models/{metric}/model.tar.gz""")tar.extractall(f"""{base_dir}models/{metric}""")tar.close()model = pkl.load(open(f"""{base_dir}models/{layer}/{metric}/xgboost-model""", 'rb'))# 执行模型评估import jsonimport pathlibimport joblibfrom sklearn.metrics import mean_squared_errorfrom sklearn.metrics import mean_absolute_errorimport mathevaluationset=pd.read_csv(f"""{base_dir}datasets/{layer}/{metric}/{metric}modelbuilding_test.csv""")evaluationset['prediction']=model.predict(xgboost.DMatrix(evaluationset.drop(evaluationset.columns.values[0], axis=1), label=evaluationset[[evaluationset.columns.values[0]]]))# 在示例中使用一个回归问题,并使用MAE和RMSE作为评估指标mae = mean_absolute_error(evaluationset[evaluationset.columns.values[0]], evaluationset['prediction'])rmse = math.sqrt(mean_squared_error(evaluationset[evaluationset.columns.values[0]], evaluationset['prediction']))stdev_error = np.std(evaluationset[evaluationset.columns.values[0]] - evaluationset['prediction'])evaluation_report=pd.DataFrame({'datetime':[datetime.now().strftime("%Y/%m/%d %H:%M:%S")], 'testing':[testing], 'trainingjob': [best_overall_training_job_name], 'objective':[trainingobjective], 'hyperparameter_tuning_metric':[objective_metric_name], 'mae':[mae], 'rmse':[rmse], 'stdev_error':[stdev_error]})# 读取过去的评估报告try: past_evaluation_reports=pd.read_csv(f"""{base_dir}models/{metric}/evaluationhistory.csv""")except: past_evaluation_reports=pd.DataFrame({'datetime':[],'testing':[], 'trainingjob': [], 'objective':[], 'hyperparameter_tuning_metric':[], 'mae':[], 'rmse':[], 'stdev_error':[]})evaluation_report=pd.concat([past_evaluation_reports,evaluation_report],axis=0)print(evaluation_report)# 写入 .csvevaluation_report.to_csv(f"""{base_dir}models/{metric}/evaluationhistory.csv""",index=False)# 写入 s3s3.upload_file(f"""{base_dir}models/{metric}/evaluationhistory.csv""",'<s3 bucket>',f"""{layer}/{metric}/evaluationhistory.csv""")# 注意,也可以将注册模型与评估指标相关联,但此处将跳过report_dict = {}# 注册模型model_package_group_name='<>'modelpackage_inference_specification = { "InferenceSpecification": { "Containers": [ { "Image": xgboost_container, "ModelDataUrl": f"""s3://{s3 bucket}/output/{best_overall_training_job_name}/output/model.tar.gz""" } ], "SupportedContentTypes": [ "text/csv" ], "SupportedResponseMIMETypes": [ "text/csv" ], } }create_model_package_input_dict = { "ModelPackageGroupName" : model_package_group_name, "ModelPackageDescription" : "<insert description here>", "ModelApprovalStatus" : "PendingManualApproval", "ModelMetrics" :report_dict}create_model_package_input_dict.update(modelpackage_inference_specification)sm_client = boto3.client('sagemaker')create_model_package_response = sm_client.create_model_package(**create_model_package_input_dict)model_package_arn = create_model_package_response["ModelPackageArn"]print('ModelPackage Version ARN : {}'.format(model_package_arn))通过在注册表中打开模型包组,您可以查看所有已注册的模型版本、注册日期和审批状态。
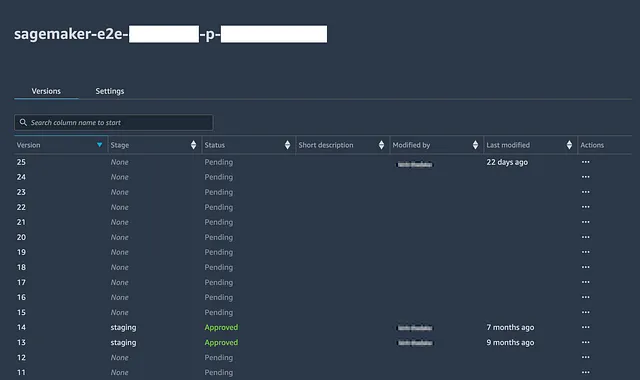
然后,管道的监督者可以审查在前一步保存的评估报告,其中包含所有过去模型评估的历史记录,并根据测试集评估指标确定是否批准或拒绝模型。稍后,可以设置条件,以仅在获得批准的情况下使用最新模型更新生产(或QA)端点。
4. 使用新模型刷新多模型端点
SageMaker有一个MultiDataModel类,允许部署能够托管多个模型的SageMaker端点。其理念是可以将多个模型加载到同一计算实例中,共享资源并节省成本。此外,它简化了模型重新训练/管理,因为只需要反映具有新模型的一个端点并进行管理,而不是在每个专用端点之间复制步骤(可以作为替代方法完成)。MultiDataModel类也可用于部署单个模型,如果将来有添加其他模型的计划,则可能有意义。
我们需要在训练账户的第一次操作中创建模型和端点。MultiDataModel类需要一个位置来存储模型工件,当它们被调用时可以加载到端点中;下面我们将使用正在使用的s3桶中的“model”目录。
# 加载容器from sagemaker.xgboost.estimator import XGBoostxgboost_container = sagemaker.image_uris.retrieve("xgboost", region, "1.2-2")# 一次性构建多模型estimator = sagemaker.estimator.Estimator.attach('sagemaker-xgboost-220611-1453-011-699894eb')xgboost_container = sagemaker.image_uris.retrieve("xgboost", region, "1.2-2")model = estimator.create_model(role=role, image_uri=xgboost_container)from sagemaker.multidatamodel import MultiDataModelsagemaker_session=sagemaker.Session()# 这是我们的MME将从S3上读取模型的位置。model_data_prefix = f"s3://{bucket}/models/"mme = MultiDataModel( name=model_name, model_data_prefix=model_data_prefix, model=model, # 传递我们的模型 - 传递所需的端点容器映像 sagemaker_session=sagemaker_session,)# 一次性部署MMEENDPOINT_INSTANCE_TYPE = "ml.m4.xlarge"ENDPOINT_NAME = "<insert here>"predictor = mme.deploy( initial_instance_count=1, instance_type=ENDPOINT_INSTANCE_TYPE, endpoint_name=ENDPOINT_NAME,kms_key='<insert here if desired>')之后,MultiDataModel可以参考如下:
model=sagemaker.model.Model(model_name)from sagemaker.multidatamodel import MultiDataModelsagemaker_session=sagemaker.Session()# 这是我们的MME将从S3上读取模型的位置。model_data_prefix = f"s3://{bucket}/models/"mme = MultiDataModel( name=model_name, model_data_prefix=model_data_prefix, model=model, # 传递我们的模型 - 传递所需的端点容器映像 sagemaker_session=sagemaker_session,)可以通过将工件复制到{S3桶}/models目录中来将模型添加到MultiDataModel中,该端点将使用该目录来加载模型。我们只需要模型包组名称和模型注册表将提供相应的源工件位置和批准状态。
我们可以添加一个条件,仅在获得批准的情况下添加最新模型,如下所示。在沙盒账户中可以省略此条件,以便进行数据科学QA和最终批准模型的即时部署。
# 获取给定模型包组的最新模型版本和关联工件位置ModelPackageGroup = 'model_package_group'list_model_packages_response = client.list_model_packages(ModelPackageGroupName=f"arn:aws:sagemaker:{region}:{aws_account_id}:model-package-group/{ModelPackageGroup}")list_model_packages_responselatest_model_version_arn = list_model_packages_response["ModelPackageSummaryList"][0][ "ModelPackageArn"]print(latest_model_version_arn)modelpackage=client.describe_model_package(ModelPackageName=latest_model_version_arn)modelpackageartifact_path=modelpackage['InferenceSpecification']['Containers'][0]['ModelDataUrl']artifact_path# 如果批准,则添加模型if list_model_packages_response["ModelPackageSummaryList"][0]['ModelApprovalStatus']=="Approved": model_artifact_name='<model_name>.tar.gz' mme.add_model(model_data_source=artifact_path, model_data_path=model_artifact_name)我们可以使用以下函数列出已添加的模型:
list(mme.list_models())# Output we'd see if we added the following two models['modela.tar.gz','modelb.tar.gz']要删除一个模型,可以转到控制台中的相关s3目录并删除其中任何一个,当重新列出可用模型时,它们将不存在。
一旦添加了一个模型,就可以使用以下代码在部署的端点中调用它:
response = runtime_sagemaker_client.invoke_endpoint( EndpointName = "<endpoint_name>", ContentType = "text/csv", TargetModel = "<model_name>.tar.gz", Body = body)在调用模型的第一次启动时,端点将加载目标模型,从而导致额外的延迟。对于已经加载了模型的未来调用,推断将立即获得。在多模型端点开发者指南中,AWS指出,长时间未调用的模型将在端点达到内存利用率阈值时被“卸载”。这些模型将在下次调用它们时重新加载。
4. 使用新模型刷新多模型端点
当通过mme.add_model()或s3控制台覆盖现有模型工件时,部署的端点不会立即反映出来。为了强制端点在下次调用时重新加载最新的模型工件,我们可以使用更新端点的技巧,使用带有日期时间戳后缀的任意新端点配置。这将创建一个需要加载模型的新端点,并安全地管理新旧端点之间的转换。因为每个端点配置需要一个唯一的名称,所以我们可以添加带有日期时间戳后缀的名称。
# Get datetime for endpoint configurationtime=str(datetime.now())[0:10]+'--'+str(datetime.now())[11:13]+'-'+'00'time# Create new endpoint config in order to 'refresh' loaded models to account for new deploymentscreate_endpoint_config_api_response = client.create_endpoint_config( EndpointConfigName=f"""<endpoint name>-{time}""", ProductionVariants=[ { 'VariantName': model_name, 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': instance_type }, ] )# Update endpoint with new configresponse = client.update_endpoint( EndpointName=endpoint_name, EndpointConfigName=f"""{model_name}-{time}""")response运行此代码后,您将看到相关端点在控制台中具有“正在更新”的状态。在此更新期间,以前的端点将可供使用,并且在准备就绪后将与新端点交换,之后状态将调整为“服务中”。然后将在下一次调用时加载新添加的模型。
现在,我们已经构建出了CI/CD解决方案所需的三个笔记本电脑——数据准备、培训/评估和端点更新。但是,这些文件目前只在训练AWS帐户中。我们需要调整第三个笔记本电脑,使其适用于任何部署AWS帐户,在其中将创建/更新相应的端点。
为此,我们可以根据AWS帐户ID添加条件逻辑。在新的AWS帐户中,还需要s3存储桶来存放模型工件。由于s3存储桶名称在AWS中必须是唯一的,因此可以使用此类条件逻辑。它也可以应用于调整端点实例类型和添加新模型的条件(即批准状态)。
# Get AWS Account IDaws_account_id = boto3.client("sts").get_caller_identity()["Account"]aws_account_id# Set Bucket & Instance Type Across Accountsif aws_account_id=='<insert AWS Account_ID 1>': bucket='<insert s3 bucket name 1>' instance_type='ml.t2.medium'elif aws_account_id=='<insert AWS Account_ID 2>': bucket='<insert s3 bucket name 2>' instance_type='ml.t2.medium'elif aws_account_id=='<insert AWS Account_ID 3>': bucket='<insert s3 bucket name 3>' instance_type='ml.m5.large'training_account_bucket='<insert training account bucket name>'bucket_path = 'https://s3-{}.amazonaws.com/{}'.format(region,bucket)需要在每个新的部署帐户中重复创建和部署MultiDataModel的步骤。
现在,我们有了一个可以引用AWS账户ID并可以在不同的AWS账户中运行的工作笔记本,我们将想要设置一个包含此笔记本的git仓库(以及可能用于谱系跟踪的其他两个笔记本),然后在这些账户的SageMaker Studio域中克隆该仓库。幸运的是,借助Studio/Git集成,这些步骤很简单/无缝,并在以下文档中概述。根据我的经验,建议在SageMaker Studio之外创建仓库,并在每个AWS账户域内克隆它。
将来对笔记本的任何更改都可以在训练账户中完成,并将其推送到仓库中。然后,可以通过在其他部署账户中拉取更改来反映这些更改。确保创建一个.gitignore文件,以便只考虑这3个笔记本,而不考虑任何日志或其他文件;谱系将在s3中跟踪。此外,应该认识到,每次运行笔记本时,控制台输出都会改变。为了避免在其他部署账户中拉取文件更改时出现冲突,应该在拉取最新更新之前恢复这些账户自上次拉取以来的任何文件更改。
5. 安排重新训练/重新部署笔记本以在一定节奏下运行
最后,我们可以在训练账户中同时安排所有三个笔记本运行。我们可以使用新的SageMaker Studio笔记本作业功能来实现这一点。这些计划应该被视为环境/账户相关的 – 即在部署账户中,我们可以创建单独的笔记本作业,但现在仅用于更新端点以使用最新的模型,并在新批准的模型在沙盒、QA和生产账户中自动部署之间提供一些滞后时间。美好的事情是,一旦解决方案发布,流程中唯一需要手动处理的部分就是模型在注册表中的批准/拒绝。如果新部署的模型出现问题,模型可以在注册表中被拒绝,之后可以手动运行端点更新笔记本来恢复到以前的生产模型版本,为进一步调查争取时间。在这种情况下,我们将管道设置为按设定时间间隔运行(即每月/每季度),尽管这个解决方案可以根据条件进行调整(即数据漂移或下降的生产模型准确性)。
结束语
CI/CD当前是机器学习运营领域的热门话题。这是有道理的,因为许多时候在机器学习解决方案的连续性方面没有多少思考。为了确保生产机器学习解决方案对协变量漂移具有鲁棒性,并且随着时间的推移是可持续的,需要一个简单而灵活的CI/CD解决方案。幸运的是,AWS已经在其SageMaker生态系统中发布了许多新功能,使得这样的解决方案成为可能。本文展示了成功为广泛的定制ML解决方案实现这一点的路径,只需要进行一次手动模型验证步骤。
感谢阅读!如果你喜欢这篇文章,请关注我以获取我的新文章通知。此外,欢迎分享任何评论/建议。