速度就是你所需要的:通过 GPU 感知优化在设备上加速大型扩散模型
由软件工程师Juhyun Lee和Raman Sarokin发布,核心系统和体验
大规模扩散模型用于图像生成的普及已经导致模型大小和推理工作负载的显着增加。在移动环境中进行设备上的ML推理需要经过细致的性能优化和考虑由于资源限制而产生的权衡。在设备上运行大型扩散模型(LDM)的推理,由于需要成本效益和用户隐私,因此面临着更大的挑战,因为这些模型的大量内存需求和计算需求。
我们在名为“ Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations ”的工作中解决了这个挑战(将在CVPR 2023 Efficient Deep Learning for Computer Vision的研讨会上提出),重点是在移动GPU上对基础LDM模型进行优化执行。在本博客文章中,我们总结了我们使用的核心技术,以成功地执行像Stable Diffusion这样的大型扩散模型,其完整分辨率(512×512像素)和20次迭代的现代智能手机的高性能推理速度,而无需对其进行精馏。正如我们在先前的博客文章中所讨论的那样,GPU加速的ML推理通常受到内存性能的限制,执行LDM也不例外。因此,我们优化的中心主题是高效的内存输入/输出(I/O),即使这意味着选择内存效率算法优先于那些优先考虑算术逻辑单元效率的算法。最终,我们的主要目标是减少ML推理的总延迟。
 |
| 移动GPU上LDM的样本输出,其中提示文本为:“一个可爱小狗和周围的花的逼真高分辨率图像”。 |
增强的注意模块以提高内存效率
ML推理引擎通常提供各种优化的ML操作。尽管如此,实现最佳性能仍然具有挑战性,因为在GPU上执行单个神经网络操作存在一定的开销。为了减轻这种开销,ML推理引擎采用广泛的运算符融合规则,将多个运算符合并为单个运算符,从而减少张量元素之间的迭代次数,同时最大化每次迭代的计算量。例如,TensorFlow Lite利用运算符融合将计算密集型的操作(如卷积)与后续的激活函数(如整流线性单元)结合在一起。
- Meta AI通过Voicebox打破了障碍:一个前所未有的生成式人工智能模型——革命性地改变了语音合成领域
- 从GPT-3到未来的语言模型
- 来自微软和加州大学圣塔芭芭拉分校的研究人员提出了LONGMEM:一种人工智能框架,使LLMs能够记忆长期历史
优化的明显机会是LDM中噪声去除器模型中采用的广泛使用的注意块。注意块允许模型通过将更高的权重分配给重要区域,来关注输入的特定部分。有多种方式可以优化注意模块,我们根据哪种优化效果更好而选择性地采用以下两种优化之一。
我们称之为部分融合softmax的第一种优化,消除了在注意模块中softmax和矩阵乘法之间进行大量内存写入和读取的需求。假设注意块只是形式为Y = softmax( X ) * W的简单矩阵乘法,其中X和W分别是形状为a×b和b×c的2D矩阵(如下图所示)。
为了数值稳定性,T = softmax( X )通常在三次传递中计算:
- 确定列表中的最大值,即矩阵X中的每一行
- 计算每个列表项的指数和最大值(来自第1次传递)之间的差异的总和
- 将项的指数减去最大值除以第2次传递的总和
简单地执行这些步骤会导致临时中间张量T的大量内存写入,该张量保存整个softmax函数的输出。如果我们仅存储标记为m和s的1和2步的结果,分别是小向量,每个向量有a个元素,与T相比,后者有a·b个元素,则可以绕过此大型内存写入。通过此技术,我们能够将数十甚至数百兆字节的内存消耗减少数个数量级(如下图所示)。
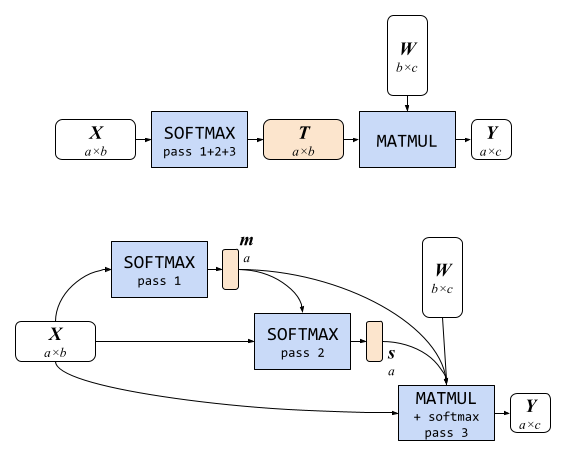 |
| 注意力模块。顶部:由SOFTMAX(带有所有三个步骤)和MATMUL组成的简单注意块需要为大型中间张量T进行大量内存写入。底部:我们的内存高效注意块仅需存储m和s的两个小中间张量,无需存储T。 |
另一个优化涉及使用FlashAttention,这是一种I/O感知的精确注意力算法。该算法减少了GPU高带宽内存访问的数量,因此非常适合我们的内存带宽受限用例。但是,我们发现此技术仅适用于具有特定大小的SRAM,并且需要大量的寄存器。因此,我们仅在某些大小的注意力矩阵上使用此技术,并选定一组GPU。
Winograd快速卷积用于3×3卷积层
常见的LDM的主干严重依赖于3×3卷积层(滤波器大小为3×3的卷积),在解码器中占据了90%以上的层。尽管会增加内存消耗和数字误差,但我们发现Winograd快速卷积可有效加速卷积。与卷积中使用的3×3滤波器大小不同,瓦片大小指的是一次处理的输入张量的子区域的大小。增加瓦片大小可以增强卷积在算术逻辑单元(ALU)使用方面的效率。但是,这种改进是以增加内存消耗为代价的。我们的测试表明,瓦片大小为4×4可以实现计算效率和内存利用率的最佳平衡。
| 内存使用情况 | |||
| 瓦片大小 | FLOPS节省 | 中间张量 | 权重 |
| 2×2 | 2.25× | 4.00× | 1.77× |
| 4×4 | 4.00× | 2.25× | 4.00× |
| 6×6 | 5.06× | 1.80× | 7.12× |
| 8×8 | 5.76× | 1.56× | 11.1× |
| 使用不同图块大小的Winograd对3×3卷积的影响。 |
专门的运算符融合以实现内存效率
我们发现,在移动GPU上执行LDM的性能推断需要比当前在设备上提供的GPU加速ML推断引擎所提供的更大的融合窗口,以常用的层和单元为基础。因此,我们开发了专门的实现,可以执行比典型的融合规则允许的更大范围的神经运算符。具体而言,我们专注于两个特殊化:高斯误差线性单元(GELU)和群组归一化层。
使用双曲正切函数的GELU的近似需要在八个GPU程序中执行八个操作(如下图中的浅橙色圆角矩形所示),需要写入和读取七个辅助中间张量(在下图中显示),从输入张量x读取三次,并从输出张量y中写入一次。执行八个操作的自定义GELU实现(如下图所示底部)可以绕过所有中间张量的内存I/O。
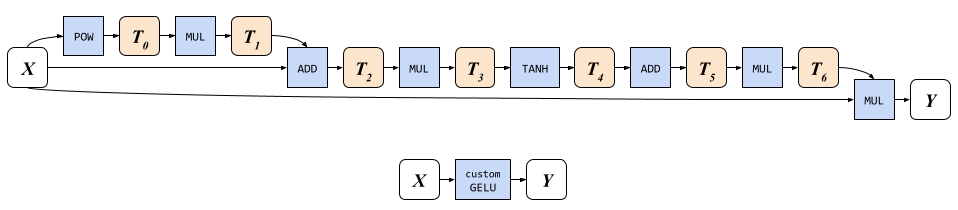 |
| GELU实现。 顶部:Naïve实现需要8个内存写操作和10个读操作。 底部:我们的自定义GELU仅需要1个内存读取(针对x)和1个写入(针对y)。 |
结果
在应用所有这些优化后,我们在高端移动设备上进行了Stable Diffusion 1.5(图像分辨率512×512,20个迭代)的测试。使用我们的GPU加速的ML推断模型运行稳定扩散需要2,093MB的权重和84MB的中间张量。使用最新的高端智能手机,稳定扩散可以在不到12秒的时间内运行。
 |
| 稳定扩散在现代智能手机上运行时间不到12秒。请注意,运行解码器以显示动画GIF中的中间输出会导致大约2倍的减速。 |
结论
在设备上执行大型模型的ML推断已被证明是一个重大的挑战,包括模型文件大小的限制,广泛的运行时内存要求和长期的推断延迟。通过将内存带宽使用量视为主要瓶颈,我们将我们的努力集中在优化内存带宽利用率和在ALU效率和内存效率之间取得微妙的平衡上。因此,我们实现了大扩散模型的最先进的推断延迟。您可以在论文中了解更多关于这项工作的信息。
致谢
我们要感谢陈玉辉、唐久强、弗兰克·巴查德、赵扬、邹俊、Khanh LeViet、张卓玲、安德烈·库利克、王璐和马蒂亚斯·格伦德曼。