嘿,GPU,我的矩阵怎么了?
GPU执行矩阵乘法的简洁指南

矩阵乘法;深度神经网络和现代语言理解巨头的圣杯。作为MLE或数据科学家,我们的手指过于迅速,输入tf.matmul或torch.matmul,从未回头。但是不要告诉我你从未想过当矩阵进入GPU时可能会发生什么!如果你想知道,那么你来对地方了。请跟我一起进入GPU内部的迷人细节之旅。
我将向您解释这些计算强大的系统如何计算数字。你将学习到GPU面对矩阵时做的三件鲜为人知的惊人的事情。在本博客文章结束时,您将对GPU内部的矩阵乘法如何工作有很好的理解。
GEMM: GPU的真正宝石💎
GEMM或广义矩阵乘法是GPU执行矩阵乘法时执行的核。
C = a (A.B) + b C
在这里,a和b是标量,A是一个MxK矩阵,B是一个KxN矩阵,因此C是一个MxN矩阵。就是这么简单!你可能会想知道为什么会存在尾随的加法。事实证明,这是神经网络的一个相当普遍的模式(例如添加偏差,应用ReLU,添加残差连接)。
技巧#1:外积是外太空👽
如果要求你从头编写矩阵乘法算法,你会做什么(除非你有一个GPU代替大脑——那会为MLE节省多少钱!)。
for (int i = 0; i < M; ++i) for (int j = 0; j < N; ++j) for (int k = 0; k < K; ++k) C[i][j] += A[i][k] * B[k][j];这里有一个动画,展示了它是如何工作的。

但是你知道GPU憎恨这种实现方式吗🤔?要理解为什么是这样,您需要了解GPU内存架构,
对于所有比较和规格,我将使用Nvidia A100 GPU规格。
GPU有三个主要的内存级别,
- 全局内存或HBM(您通常称之为GPU内存,以及在运行
nvidia-smi时看到的内容) - 共享内存(一个本地内存,专门为单个流多处理器[或SM]专用,并在运行该SM的线程之间共享)
- 寄存器(分配给线程以执行其工作负载)
它看起来像这样,
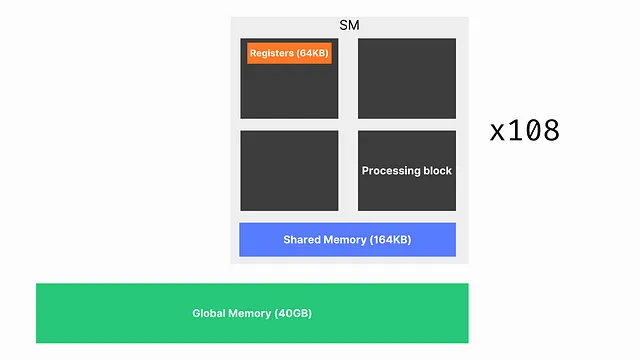
首先要注意的是,共享内存(现在称为 SRAM)比 HBM 要小得多,更不用说寄存器了。因此,在大多数情况下,您的矩阵是放不下的。回到我们的动画,对于 A 的一行,需要检索所有 B 的列,并重复此过程以处理 A 的所有行。这意味着 GPU 需要进行许多读取才能计算输出。HBM(~1.5TB/s)比 SRAM(~19TB/s)慢几个数量级。
换句话说,假设您想要乘以一个 10x20 和一个 20x30 的矩阵,则需要读取 B 的列 10x30=300 次。有没有更好的方法可以解决这个问题?
事实证明,一个简单的技巧在这里可以起到很大的作用!只需翻转循环的顺序,使 k 成为最外层的循环即可。完成了! 😮
for (int k = 0; k < K; ++k) for (int i = 0; i < M; ++i) for (int j = 0; j < N; ++j) C[i][j] += A[i][k] * B[k][j];我们没有触及实际的计算,只是改变了循环的顺序,因此应该得到与之前相同的结果。现在矩阵乘法看起来像这样!
您会发现,我们一次只带入一个 A 的列和一个 B 的行,不再回头。这需要比原始实现少得多的读取。唯一的区别是我们之前计算了两个向量之间的内积,现在我们计算的是外积。
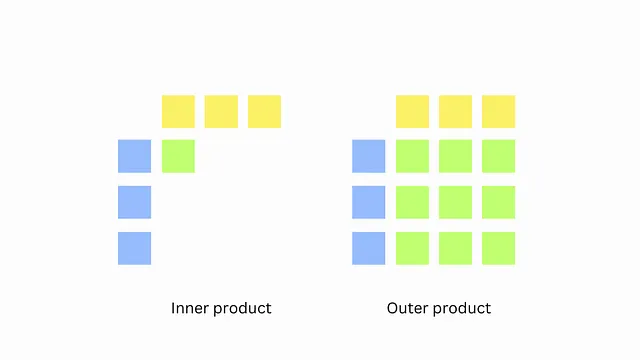
但是,我们仍然需要在 SRAM 中拥有整个 C,这可能太大而无法放入 SRAM 中。CUDA 做什么呢?这带我们到第二个技巧。
技巧 #2:分治(和累加)
别担心!我不会向您炸掉任何复杂的数学或 Leetcode 算法。主要要记住的是,矩阵是个体块的 2D 布局。以下动画很好地解释了我要解释的内容。
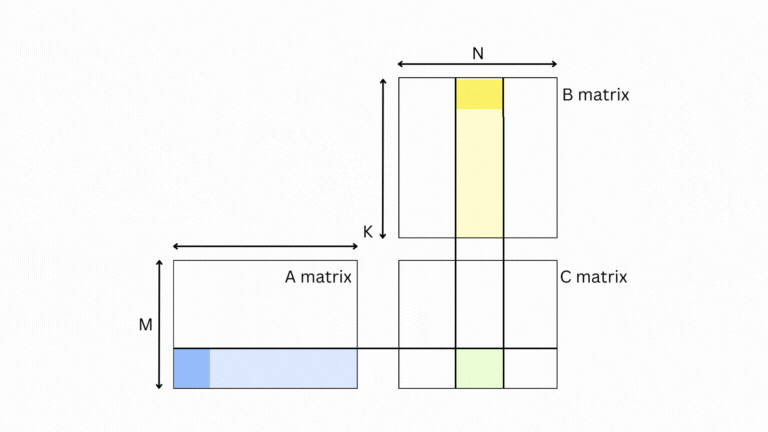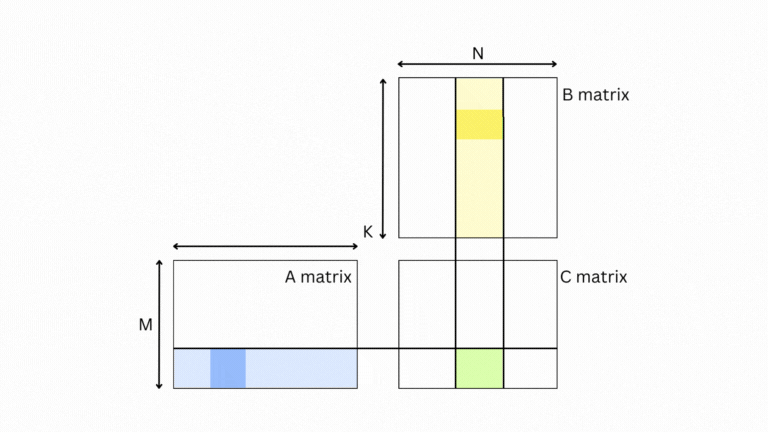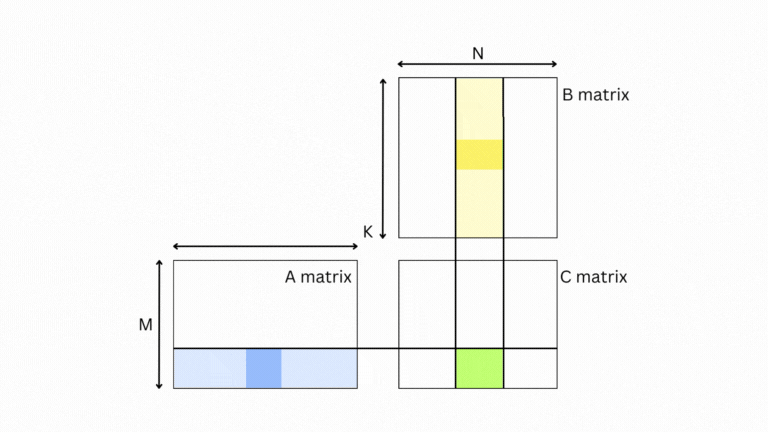
绿色块 💚 的结果是 A 💙 的浅蓝色条和 B 💛 的浅黄色条。更进一步,要计算输出,您可以一次带入 A 的一块和 B 的一块,计算输出并在绿色框中累加结果。
这为我们提供了一个灵活的框架,在其中可以加载任意大小的 A 和 B 块(或瓷砖),并仍然计算最终答案。我们不必停在那里,我们可以继续将问题递归地分解为更小的问题。即矩阵被分成瓷砖,瓷砖被分成碎片,碎片被分成单个值。
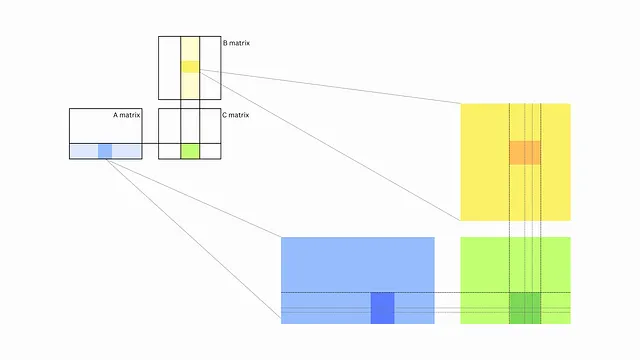
这很适合在GPU中进行进程执行架构。GPU的内核执行有三个层次。为了简单起见,我们将称SM运行单个线程块(尽管在实践中,它们同时执行它们,以减少尾部效应)。
- 线程
- 线程束(32个线程的集合)
- 线程块(几个线程束的集合)
线程块中的线程数取决于特定的架构。例如,A100具有以下规格。
- 每个SM最多2048个线程
- 每个块最多1024个线程
- 每个SM最多32个线程块
侧边栏#2:2的幂的魔力
回到铺瓷砖,已经发现(启发式地),对于大多数问题,每个线程块的矩阵块大小为256x128可以达到合理的效率。因此,这是CUDA使用的常见瓷砖大小。
您可能已经听说过将批大小、隐藏维度大小保持为2的幂的最佳实践。这就是这里来的地方!当您的矩阵维度为2的幂时,它将被完全分成一组没有余数的瓷砖。否则,它会使您的代码效率低下。
当您的矩阵维度为2的幂时,GPU计算更加高效
当它不是2的幂时会发生什么?
侧边栏#2:块状量化
发生的是一种称为瓷砖量化的效应。换句话说,如果您的瓷砖行维度为128,但是您的矩阵在一行中有257个元素,您将需要不是两个,而是三个瓷砖行(即256 + 1)。如下所示。
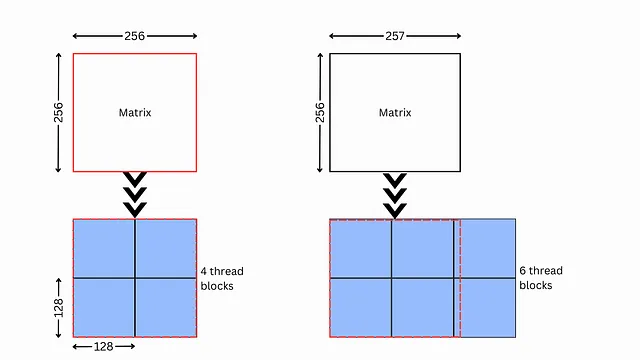
这样做的问题是,线程块执行的计算量不会因其中包含的有用数据而改变。因此,您正在从GPU中获取执行有用计算的机会,从而导致效率低下。
类似的效应称为波量化,其中矩阵过大,SM无法同时将其放在一个地方。然后,GPU需要在2个“波”中进行计算。但是,对于现代GPU来说,这不是太重要,因为它们利用并发性来减少波量化。
当线程块不得不部分溢出数据时,会发生瓷砖量化,当SM不得不溢出数据时,会发生波量化。
技巧#3:1比2好
最后一个技巧是内核融合。往往,将所有计算放在一个内核中比一个接一个地调用两个内核更快。为什么?因为一个内核需要将数据写入HBM,另一个需要读取数据。我们已经谈到了这有多慢。更好的方法是将两个操作合并成一个。一些示例是,
- matmul +偏差+ relu
- conv +偏差+ relu
- batchnorm + relu
因此,如此看来(我确定Pytorch有类似的词汇表),通过TensorFlow提供了许多融合内核,将舒适的操作组合成单个内核。在代码中,它的意思是这样的,
for (int m = 0; m < M; m += Mtile) for (int n = 0; n < N; n += Ntile) for (int k = 0; k < K; ++k) float tmp = 0 for (int i = 0; i < Mtile; ++i) for (int j = 0; j < Ntile; ++j) int row = m + i; int col = n + j; tmp += A[row][k] * B[k][col]; // Do other things C[row][col] = tmp换句话说,我们珍视我们的tmp变量,直到完成所有计算之后。然后我们才会将结果写回C。
结论
就是这样。我希望这是一次有趣的GPU之旅。如果您对音频-视频版本感兴趣,这是我的YouTube视频链接。
回顾一下,我们讨论了三个让GPU在矩阵乘法中变得非常快的东西:
- GPU放弃了matmul的更友好的内积实现,而采用了更具读取效率的外积实现
- GPU将矩阵分成较小的块(并将块分成片段),并将计算负载分配给线程块、warp和线程。
- GPU采用内核融合将常见的共同功能组合在一起,提高GPU的效率。
如果您喜欢这个故事,请随时订阅小猪AI,您将收到来自我的新鲜内容的通知,以及解锁其他作者数千个优质故事的完全访问权限。
使用我的推荐链接加入小猪AI – Thushan Ganegedara
作为小猪AI会员,您的会员费的一部分将支付给您阅读的作家,并且您将获得对每个故事的完全访问权限…
thushv89.medium.com
除非另有说明,所有图片均由作者提供。
参考文献:
- https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html
- https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/
- https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/