使用Docker调试SageMaker终端节点
替代SageMaker本地模式的方法
使用SageMaker实时推理的一个痛点是有时难以进行调试。在创建端点时,您需要确保一些关键要素被正确配置,才能成功部署。
- 根据您正在使用的模型服务器和容器,正确地构造模型工件的文件结构。实际上,您提供的model.tar.gz必须符合模型服务器的规范。
- 如果您有一个自定义的推理脚本,实现了模型的前后处理,您需要确保实施的处理程序符合您的模型服务器,并且代码层面没有脚本错误。
以前我们已经讨论过SageMaker本地模式,但在本文撰写时,本地模式不支持SageMaker部署可用的所有托管选项和模型服务器。
为了克服这个限制,我们将看看如何使用Docker和样例模型来测试/调试我们的模型工件和推理脚本,以便在SageMaker部署之前。在这个具体的例子中,我们将利用我在上一篇文章中介绍的BART模型,看看如何使用Docker托管它。
注意: 对于AWS新手,请确保在以下链接处注册一个帐户,以便跟随本文步骤。本文还假定您已掌握SageMaker部署的中级理解,我建议您阅读这篇文章以更深入地理解部署/推理。对于Docker的中级理解也有所帮助,以充分理解本例。
SageMaker托管的工作原理是什么?
在我们进入本文的代码部分之前,让我们看一下SageMaker实际上是如何服务请求的。在其核心,SageMaker推理有两个构造:
- 容器:这建立了模型的运行时环境,它还与您正在使用的模型服务器集成。您可以使用现有的Deep Learning Containers (DLCs)之一或构建您自己的容器。
- 模型工件:在CreateModel API调用中,我们指定一个S3 URL,其中包含以model.tar.gz(tarball)格式呈现的模型数据。将此模型数据加载到容器上的opt/ml/model目录中,这也包括您提供的任何推理脚本。
关键在于容器需要实现一个Web服务器,以响应端口8080上的/invocations和/ping路径。在Bring Your Own Container示例中,我们已经实现了这些路径之一的Web服务器示例,即Flask。
使用Docker,我们将公开此端口,并指向我们的本地脚本和模型工件,以模拟SageMaker端点的预期行为方式。
使用Docker进行测试
为了简单起见,我们将使用我上一篇文章中的BART示例,您可以从此存储库中获取工件。在这里,您应该看到以下文件:

- model.py:这是我们正在处理的推理脚本。在这种情况下,我们使用了DJL Serving,它需要一个具有实现推理的处理程序函数model.py。您的推理脚本仍然需要与模型服务器期望的格式兼容。
- requirements.txt:您的model.py脚本需要的任何其他依赖项。对于DJL Serving,PyTorch已预先安装,我们使用numpy进行数据处理。
- serving.properties:这也是DJL特定的文件,在这里您可以定义模型级别的任何配置(例如:每个模型的工作人员)
我们有了模型工件,现在我们需要要使用的容器。在这种情况下,我们可以检索现有的DJL DeepSpeed镜像。有关AWS已提供的图像的详细列表,请参阅此指南。您还可以在本地构建自己的映像,并指向该映像。在这种情况下,我们在SageMaker Classic Notebook Instance环境中运行,该环境预先安装了Docker。
要使用现有的AWS提供的镜像,我们首先需要登录AWS Elastic Container Registry(ECR)来检索镜像,您可以使用以下shell命令执行此操作。
$(aws ecr get-login --region us-east-1 --no-include-email --registry-ids 763104351884)您应该会看到类似以下的登录成功消息。

登录后,我们可以进入存储模型工件的路径并运行以下命令,这将启动模型服务器。如果您尚未检索镜像,则还将从ECR中提取该镜像。
docker run \-v /home/ec2-user/SageMaker:/opt/ml/model \--cpu-shares 512 \-p 8080:8080 \763104351884.dkr.ecr.us-east-1.amazonaws.com/djl-inference:0.21.0-deepspeed0.8.0-cu117 \serve这里有几个关键点:
- 我们正在公开端口8080,因为SageMaker Inference需要。
- 我们还指向现有的镜像。此字符串取决于您所操作的区域和模型。您还可以使用SageMaker Python SDK检索image_uri API调用来识别要在此处拉取的适当镜像。

在拉取镜像后,您将看到启动了模型服务器。

我们还可以通过使用以下Docker命令验证此容器是否正在运行。
docker container ls
我们看到API通过端口8080公开,我们可以通过curl向其发送示例请求。请注意,我们指定了SageMaker Containers期望的/invocations路径。
curl -X POST http://localhost:8080/invocations -H "Content-type: text/plain" "This is a sample test string"然后我们看到请求的推理结果以及模型服务器跟踪响应并从推理脚本发出我们的日志记录语句。
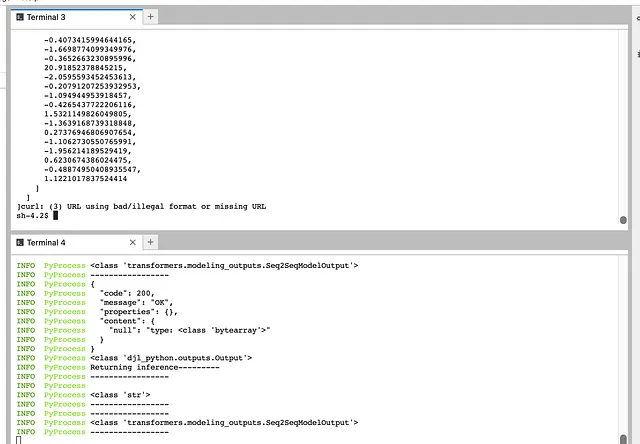
让我们打破我们的model.py并查看是否可以通过Docker尽早捕获错误。在这里,我在推理函数中添加了一个语法上不正确的打印语句,并重新启动我的模型服务器,以查看是否捕获到此错误。
def inference(self, inputs): """ Custom service entry point function. :param inputs: the Input object holds the text for the BART model to infer upon :return: the Output object to be send back """ #sample error print("=)然后,当我们执行docker run命令时,我们可以看到模型服务器捕获了此错误。

请注意,您不仅限于使用curl来测试您的容器。我们还可以使用类似于Python requests库的东西来接口和使用容器。示例请求如下:
import requestsheaders = { 'Content-type': 'text/plain',}response = requests.post('http://localhost:8080/invocations', headers=headers)使用类似requests的东西,您可以在容器上运行更大规模的负载测试。请注意,您运行容器的硬件正在被利用(将其视为SageMaker Endpoint背后实例的等效项)。
其他资源和结论
GitHub – RamVegiraju/SageMaker-Docker-Local: 如何在本地使用Docker测试SageMaker推理
如何在本地使用Docker测试SageMaker推理 – GitHub – RamVegiraju/SageMaker-Docker-Local: 如何在本地测试SageMaker推理
github.com
您可以在上面的链接中找到整个示例的代码。使用SageMaker推理,您要避免等待端点创建以捕获任何错误的痛苦。使用这种方法,您可以使用任何SageMaker容器来测试和调试您的模型工件和推理脚本。
如往常一样,欢迎留下任何反馈或问题,感谢您的阅读!
如果您喜欢本文,请随时在LinkedIn上与我联系并订阅我的小猪AI Newsletter。如果您是小猪AI的新用户,请使用我的Membership Referral进行注册。