变分推断:基础知识
我们生活在量化时代。但是严格的量化说起来容易做起来难。在生物学这样的复杂系统中,数据可能难以收集且成本高昂。而在医疗和金融等高风险应用中,考虑不确定性至关重要。变分推断——AI研究的前沿方法之一——是解决这些问题的一种方法。
本教程将向您介绍基础知识:变分推断的何时、为什么以及如何使用。
何时使用变分推断?
变分推断适用于以下三种密切相关的用例:
1. 如果您拥有少量数据(即观察次数较少),
2. 您关心不确定性,
3. 用于生成建模。
我们将在我们的示例中涉及每种用例。
1. 少量数据的变分推断

有时,数据收集是昂贵的。例如,DNA或RNA测量可能每个观察值轻易花费几千欧元。在这种情况下,您可以在没有额外样本的情况下硬编码领域知识。变分推断可以帮助您系统地“调低”领域知识,以便在收集更多示例时更加依赖数据(图1)。
2. 不确定性的变分推断
对于金融和医疗等安全关键应用程序,不确定性是很重要的。不确定性可能影响模型的所有方面,最明显的是预测输出。模型参数(例如,权重和偏差)不明显。您可以为参数赋予分布以使其模糊,而不是通常的数字数组——权重和偏差。变分推断允许您推断合理值的范围。
3. 生成建模的变分推断
生成模型提供了完整的规范,说明数据是如何生成的。例如,如何生成猫或狗的图像。通常,有一个潜在表示z,它具有语义含义(例如,z描述了一只暹罗猫)。通过一组(非线性)变换和采样步骤,z被转换为实际图像x(例如,暹罗猫的像素值)。变分推断是推断和采样来自潜在语义空间z的方法。一个众所周知的例子是变分自编码器。
什么是变分推断?
在其核心,变分推断是贝叶斯方法之一[1]。在贝叶斯观点中,您仍然让机器像往常一样从数据中学习。不同之处在于,您给模型一个提示(先验),并允许解决方案(后验)更模糊。更具体地说,假设您有一个训练集X = [x₁,x₂,..,xₘ]ᵗ,其中m个示例。我们使用贝叶斯定理:
p(Θ | X)= p(X | Θ)p(Θ)/ p(X),
推断出一组解决方案Θ的范围(分布)。与传统的机器学习方法相反,我们通过最小化损失ℒ(Θ,X)= ln p(X | Θ)来找到一个特定的解决方案Θ。贝叶斯推断围绕着找到确定参数的后验分布p(Θ | X)展开。一般来说,这是一个困难的问题。在实践中,有两种方法用于解决p(Θ | X):(i)使用模拟(马尔可夫链蒙特卡罗)或(ii)通过优化。
变分推断涉及选项(ii)。
证据下界(ELBO)
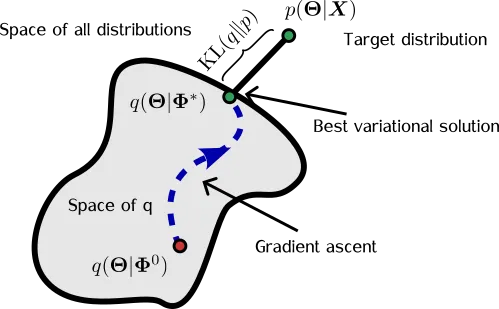
变分推断的思想是寻找一个分布q( Θ ),它是p( Θ | X )的替代品(代理)。然后我们尝试通过改变 Φ 的值(图2)使q( Θ|Φ )看起来类似于p( Θ | X )。这是通过最大化证据下界(ELBO)来完成的:
ℒ ( Φ ) = E[ln p ( X , Θ ) — ln q ( Θ|Φ) ],
其中期望E[·]是在q( Θ|Φ )上取的。乍一看,由于E[·]对q( Θ|Φ )的依赖关系,我们必须小心地取导数(关于 Φ )。幸运的是,像JAX这样的自动求导软件支持重新参数化技巧[2],它可以让你直接从随机样本(例如伽马分布的样本)中取导数,而不是依赖于高方差的黑箱变分方法[3]。长话短说:用一个批次[ Θ ₁,Θ ₂,..] ~ q( Θ|Φ )来估计∇ℒ( Φ ),让你的自动求导软件来担心细节。
从头开始的变分推断
为了巩固我们的理解,让我们使用JAX从头开始实现变分推断。在此示例中,您将训练一个生成模型来识别sci-kit learn中的手写数字。您可以使用Colab笔记本跟随本文。
为了简单起见,我们只分析数字“零”。
from sklearn import datasetsdigits = datasets.load_digits()is_zero = digits.target == 0X_train = digits.images[is_zero]# Flatten image grid to a vector.n_pixels = 64 # 8-by-8.X_train = X_train.reshape((-1, n_pixels))每个图像都是一个8乘8的离散像素值数组,范围从0到16。由于像素是计数数据,让我们使用泊松分布对像素 x 进行建模,使用伽马分布作为率 Θ 的先验分布。率 Θ 决定像素的平均强度。因此,联合分布为:
p ( x , Θ ) = Poisson( x | Θ ) Gamma( Θ | a , b ),
其中 a 和 b 是伽马分布的形状和速率。

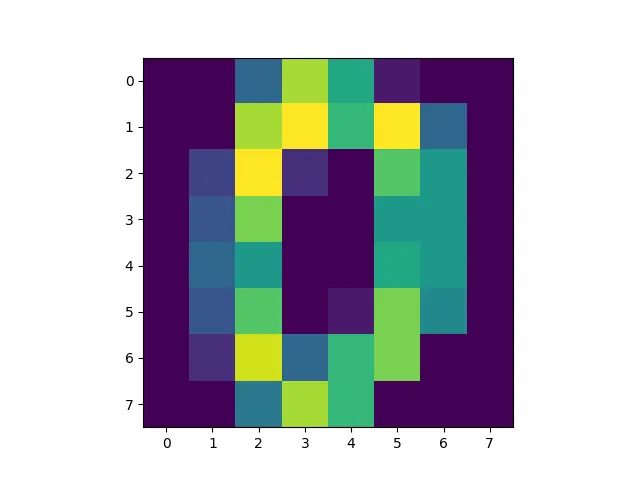
先验 – 在这种情况下,Gamma(Θ|a, b) – 是您注入领域知识(用例1.)的地方。例如,您可能对“平均”数字零的外观有一些想法(图4)。您可以使用这些先验信息来指导您选择的a和b。要将图4用作先验信息 – 让我们称其为x₀ – 并将其重要性作为两个示例进行加权,然后设置a = 2x₀; b = 2。
在Python中写下来看起来像:
import jax.numpy as jnpimport jax.scipy as jsp# 模型的超参数。a = 2. * x_domain_knowledgeb = 2.def log_joint(θ): log_likelihood = jnp.sum(jsp.stats.gamma.logpdf(θ, a, scale=1./b)) log_likelihood += jnp.sum(jsp.stats.poisson.logpmf(X_train, θ)) return log_likelihood请注意,我们使用了numpy和scipy的JAX实现,以便我们可以进行导数计算。
接下来,我们需要选择一个代理分布q(Θ|Φ)。提醒一下,我们的目标是更改Φ,使得代理分布q(Θ|Φ)与真实分布p(Θ|X)匹配。因此,q(Θ)的选择确定了逼近的水平(我们在上下文允许的情况下抑制了对Φ的依赖)。为了说明目的,让我们选择由伽马的乘积组成的变分分布:
q(Θ|Φ) = Gamma(Θ|α,β),
其中我们使用了简写Φ = {α,β}。
接下来,为了实现证据下限ℒ(Φ) = E[ln p(X,Θ) – ln q(Θ|Φ)], 首先写下期望括号内的项:
@partial(vmap, in_axes=(0, None, None))def evidence_lower_bound(θ_i, alpha, inv_beta): elbo = log_joint(θ_i) - jnp.sum(jsp.stats.gamma.logpdf(θ_i, alpha, scale=inv_beta)) return elbo在这里,我们使用了JAX的vmap将函数向量化,以便我们可以在批[Θ₁,Θ₂,…,Θ₁₂₈]ᵗ上运行它。
为了完成ℒ(Φ)的实现,我们对变分分布样本Θᵢ ~ q(Θ)进行平均:
def loss(Φ: dict, key): """证据下限的随机估计。""" alpha = jnp.exp(Φ['log_alpha']) inv_beta = jnp.exp(-Φ['log_beta']) # 从变分分布q中抽取一个批次。 batch_size = 128 batch_shape = [batch_size, n_pixels] θ_samples = random.gamma(key, alpha , shape=batch_shape) * inv_beta # 计算证据下限的蒙特卡罗估计。 elbo_loss = jnp.mean(evidence_lower_bound(θ_samples, alpha, inv_beta)) # 将elbo转换为损失。 return -elbo_loss关于参数,有几个要注意的事项:
- 我们将 Φ 打包成一个字典(或技术上说是一个 pytree),包含 ln ( α ) 和 ln ( β )。这个技巧保证了在优化过程中 α >0 且 β >0,这是 gamma 分布所要求的。
- 损失是 ELBO 的随机估计值。在 JAX 中,我们需要每次采样都使用一个新的伪随机数生成器(PRNG)密钥。在这种情况下,我们使用密钥来采样 [ Θ ₁, Θ ₂,.., Θ ₁₂₈]ᵗ。
这就完成了模型 p ( x , Θ),变分分布 q ( Θ ) 和损失 ℒ ( Φ ) 的规范。
模型训练
接下来,我们通过变化 Φ = { α , β } 来最小化损失 ℒ ( Φ ),使得 q ( Θ|Φ ) 与后验分布 p ( Θ | X ) 匹配。如何实现?使用老式的梯度下降!为了方便起见,我们使用 Optax 中的 Adam 优化器,并使用先验分布 α = a 和 β = b 初始化参数[记住,先验是 Gamma( Θ | a , b ),并且编码了我们的领域知识]。
# 使用先验初始化参数。Φ = { 'log_alpha': jnp.log(a), 'log_beta': jnp.full(fill_value=jnp.log(b), shape=[n_pixels]),}loss_val_grad = jit(jax.value_and_grad(loss))optimiser = optax.adam(learning_rate=0.2)opt_state = optimiser.init(Φ)这里,我们使用 value_and_grad 同时评估 ELBO 及其导数。方便监控收敛性!然后,我们使用 jit 即时编译生成的函数,使其更快。
最后,我们将训练模型 5000 步。由于损失是随机的,因此每次评估时我们都需要提供一个伪随机数生成器(PRNG)密钥。我们通过使用 random.split 分配 5000 个密钥来实现这一点。
n_iter = 5_000keys = random.split(random.PRNGKey(42), num=n_iter)for i, key in enumerate(keys): elbo, grads = loss_val_grad(Φ, key) updates, opt_state = optimiser.update(grads, opt_state) Φ = optax.apply_updates(Φ, updates)恭喜!您已成功使用变分推理训练了第一个模型!
您可以在 Colab 上访问完整代码的笔记本。
结果
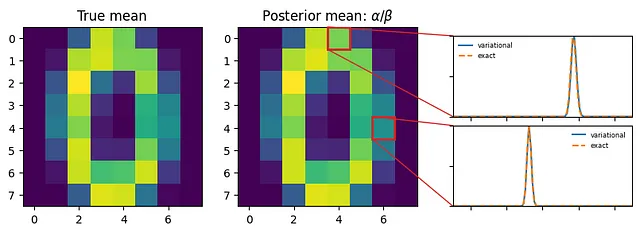
让我们退后一步,欣赏一下我们所构建的东西(图 5)。对于每个像素,代理 q ( Θ ) 描述了关于平均像素强度的不确定性(用例 2.)。特别地,我们选择的 q ( Θ ) 捕捉了两个互补的元素:
- 典型的像素强度。
- 强度从图像到图像的变化程度(变异性)。
事实证明,我们选择的联合分布 p ( x , Θ ) 有一个精确解:
p ( Θ|X) = Gamma( Θ | a + Σ x ᵢ, m + b )。
其中,m 是训练集 X 中样本数量。在这里,我们清楚地看到领域知识——在a和b中编码——如何随着我们收集更多的示例x ᵢ而降低。
我们可以将学习到的形状α和速率β与真实值a + Σ x ᵢ 和 m + b 进行简单比较。在图4中,我们比较了两个特定像素的分布——q ( Θ|Φ ) 与 p ( Θ|X) —。看,完美匹配!
奖励:生成合成图像

变分推断非常适用于生成建模(用例3)。有了后验替代物q ( Θ ) ,生成新的合成图像就很容易。两个步骤如下:
- 样本像素强度 Θ ~ q ( Θ )。
# 提取 q.alpha 的参数 = jnp.exp(Φ['log_alpha'])inv_beta = jnp.exp(-Φ['log_beta'])# 1)为10个图像生成像素级强度。key_θ、key_x = random.split(key)m_new_images = 10new_batch_shape = [m_new_images, n_pixels]θ_samples = random.gamma(key_θ, alpha , shape=new_batch_shape) * inv_beta- 使用 x ~ Poisson( x | Θ ) 样本图像。
# 2)从强度中采样图像。X_synthetic = random.poisson(key_x, θ_samples)您可以在图6中看到结果。请注意,“零”字符略微比预期的模糊。这是我们建模假设的一部分:我们将像素建模为相互独立而不是相关的。要考虑像素相关性,可以将模型扩展到聚类像素强度:这称为泊松分解[4]。
总结
在本教程中,我们介绍了变分推断的基础知识,并将其应用于一个玩具示例:学习手写数字零。由于自动微分,从头开始实现变分推断只需要几行Python代码。
如果您拥有少量数据,变分推断特别强大。我们看到如何将领域知识与数据信息相结合并进行权衡。推断的代理分布 q ( Θ ) 给出了模型参数的“模糊”表示,而不是固定值。如果您处于高风险应用程序中,并且不确定性很重要,这是理想的!最后,我们演示了生成建模。一旦您可以从 q ( Θ ) 中进行采样,生成合成样本就很容易。
总之,这使它成为数据科学工具箱的核心组件。
通过利用变分推断的力量,我们可以解决复杂的问题,使我们能够做出明智的决策,量化不确定性,并最终释放数据科学的真正潜力。
致谢
我要感谢 Dorien Neijzen 和 Martin Banchero 进行校对。
参考文献:
[1] Blei, David M., Alp Kucukelbir, and Jon D. McAuliffe. ” Variational inference: A review for statisticians. ” Journal of the American statistical Association 112.518 (2017): 859–877.
[2] Figurnov, Mikhail, Shakir Mohamed, and Andriy Mnih. ” Implicit reparameterization gradients. ” Advances in neural information processing systems 31 (2018).
[3] Ranganath, Rajesh, Sean Gerrish, and David Blei. ” Black box variational inference .” Artificial intelligence and statistics . PMLR, 2014.
[4] Gopalan, Prem, Jake M. Hofman, and David M. Blei. ”基于泊松分解的可扩展推荐系统.” arXiv预印本arXiv:1311.1704 (2013).