卷积神经网络全面指南
人工智能正在见证在弥合人类和机器之间能力差距方面的巨大增长研究人员和爱好者们一起致力于该领域的众多方面,以创造惊人的事物其中之一就是计算机视觉领域
人工智能正在见证人类和机器能力差距的巨大缩小。研究人员和爱好者们为实现惊人的成果在该领域进行了众多方面的工作。其中一个领域是计算机视觉。
该领域的议程是使机器像人类一样观察世界、以类似的方式感知它,甚至将这种知识用于诸如图像和视频识别、图像分析和分类、媒体重建、推荐系统、自然语言处理等多种任务。深度学习在计算机视觉方面的进步是通过时间的构建和完善的,主要是通过一种算法——卷积神经网络。
介绍

卷积神经网络(ConvNet/CNN)是一种深度学习算法,可以接收输入图像,为图像中的各个方面/对象分配重要性(可学习的权重和偏差),并能够区分一个方面/对象与另一个方面/对象。与其他分类算法相比,ConvNet所需的预处理要低得多。虽然在原始方法中,滤波器是手工设计的,但经过充分的训练,ConvNets具有学习这些滤波器/特征的能力。
ConvNet的架构类似于人类大脑神经元连接模式,并受到视觉皮层组织的启发。单个神经元仅对称为接收场的视觉领域的受刺激做出反应。一组这样的领域重叠以覆盖整个视觉区域。
为什么使用ConvNets而不是前馈神经网络?
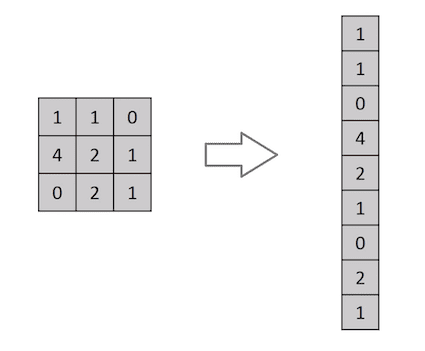
一幅图像不过是像素值的矩阵,对吧?那么为什么不把图像展平(例如,将3×3的图像矩阵变成9×1的向量),然后将其馈送到多层感知器进行分类呢?嗯…实际上不是这样。
对于极其基本的二元图像,该方法可能显示出平均的精度评分,但对于具有整个像素依赖关系的复杂图像来说,几乎没有准确性。
ConvNet能够成功地捕捉图像中的空间和时间依赖关系,通过应用相关滤波器。由于减少了涉及的参数数量和权重的可重用性,该架构对图像数据集的拟合效果更好。换句话说,可以训练网络更好地了解图像的复杂性。
输入图像
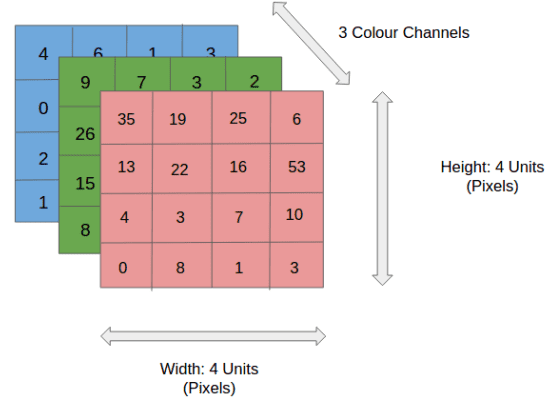
在图中,我们有一幅RGB图像,已经通过其三个颜色平面——红色、绿色和蓝色分离。存在许多这样的颜色空间,其中图像存在——灰度、RGB、HSV、CMYK等。
你可以想象一下,当图像达到8K(7680×4320)的尺寸时,计算密集型的东西会变得多么复杂。ConvNet的作用是将图像缩小为更容易处理的形式,同时不失去对于获得良好预测至关重要的特征。这在我们设计一个既擅长于学习特征,又可扩展到大规模数据集的架构时非常重要。
卷积层 – 过滤器

图像尺寸=5(高)x5(宽)x1(通道数,例如RGB)
在上面的演示中,绿色部分类似于我们的5x5x1输入图像I。参与卷积层的第一部分的元素称为Kernel/Filter,K,用黄色表示。我们选择了K作为3x3x1矩阵。
Kernel/Filter,K =
1 0 1
0 1 0
1 0 1由于步长=1(非跨度),内核移动了9次,每次在内核所在的图像部分P上执行一个逐元素乘法运算(哈达玛积)和K之间。
过滤器向右移动一定的步幅值,直到解析完整个宽度。 接着,它以相同的步幅值向下跳到图像的开始(左边),并重复此过程,直到整个图像被遍历。
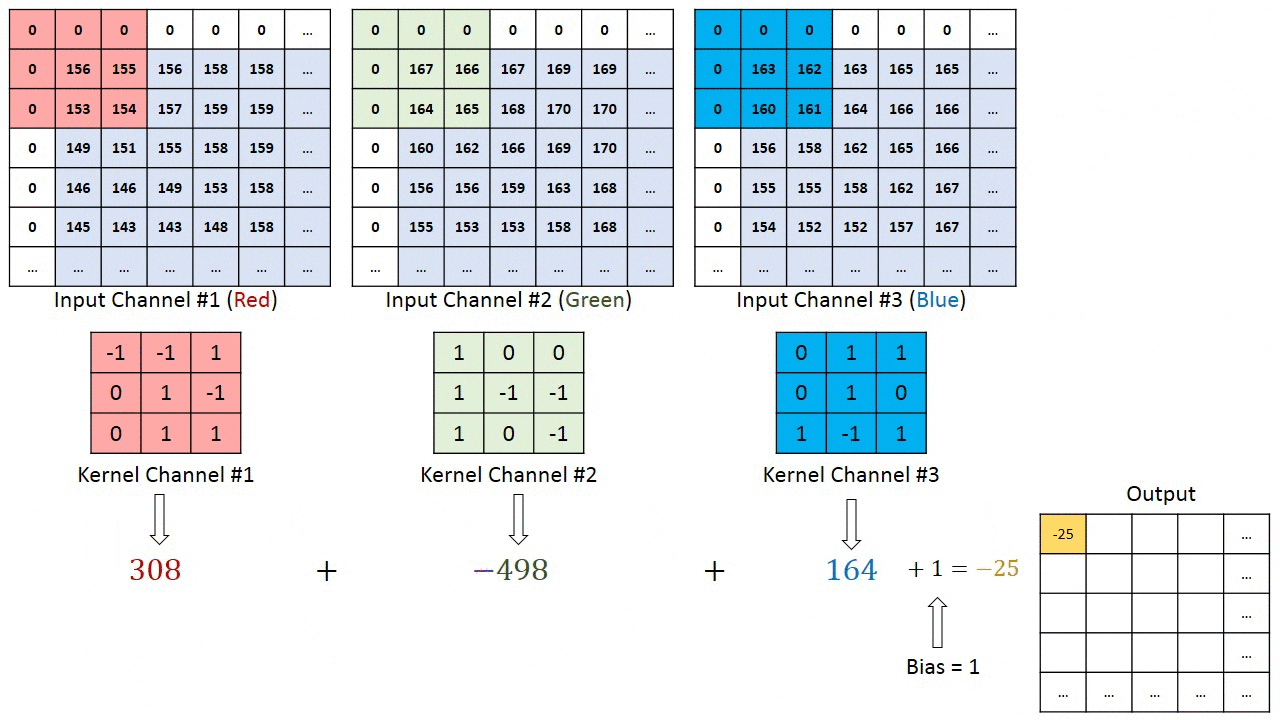
对于具有多个通道(例如RGB)的图像,内核的深度与输入图像的深度相同。在Kn和In堆栈([K1,I1]; [K2,I2]; [K3,I3])之间执行矩阵乘法,并将所有结果与偏差相加,以给出我们一个压缩的一深度通道卷积特征输出。

卷积操作的目的是从输入图像中提取高级特征,例如边缘。 ConvNets不必仅限于一个卷积层。传统上,第一个ConvLayer负责捕获低级特征,例如边缘,颜色,梯度方向等。随着添加的层数,体系结构也适应了高级特征,从而为我们提供了对数据集中图像的全面理解,类似于我们的理解方式。
操作有两种结果类型-一种是与输入相比,卷积特征的维数降低,另一种是维数增加或保持不变。在前一种情况下应用有效填充,在后一种情况下应用相同填充。
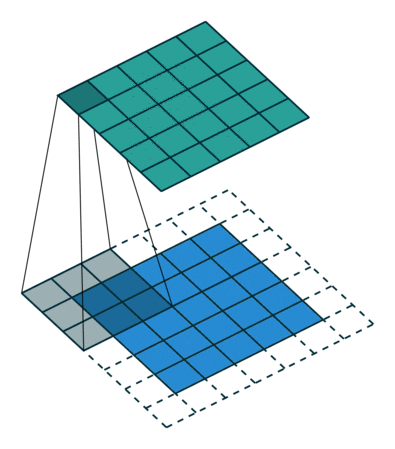
当我们将5x5x1图像增强为6x6x1图像,然后在其上应用3x3x1内核时,我们发现卷积矩阵的尺寸为5x5x1。因此得名相同填充。
另一方面,如果我们在没有填充的情况下执行相同的操作,则会呈现出与内核(3x3x1)本身具有相同维度的矩阵-有效填充。
以下存储库包含许多此类GIF,可帮助您更好地了解填充和步幅长度如何共同实现与我们需求相关的结果。
[vdumoulin / conv_arithmetic
有关深度学习上的卷积算法的技术报告-vdumoulin / conv_arithmetic github.com](https://github.com/vdumoulin/conv_arithmetic)
池化层
与卷积层类似,池化层负责减小卷积特征的空间大小。这是为了通过降低维数来减少处理数据所需的计算能力。此外,它还可用于提取旋转和位置不变的主导特征,从而保持有效地训练模型的过程。
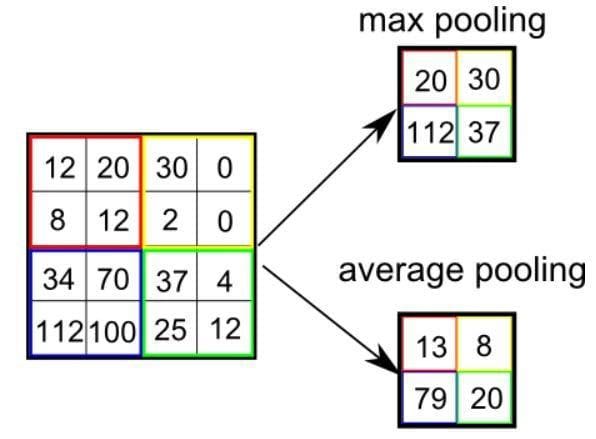
有两种类型的池化:最大池化和平均池化。 最大池化返回由内核覆盖的图像部分的最大值。另一方面,平均池化返回由内核覆盖的图像部分的所有值的平均值。
最大池化还充当噪声抑制器。它完全丢弃嘈杂的激活,并且还执行去噪和降维。另一方面,平均池化仅作为减少维数的噪声抑制机制。因此,我们可以说最大池化比平均池化表现更好。
 池化的类型
池化的类型
卷积层和池化层一起构成了卷积神经网络的第i层。根据图像的复杂性,这样的层数可以增加,以捕获更低级别的细节,但代价是需要更多的计算能力。
通过上述过程,我们已成功使模型能够理解特征。接下来,我们将把最终输出展开,并将其馈送到常规神经网络中进行分类。
分类 — 全连接层(FC层)
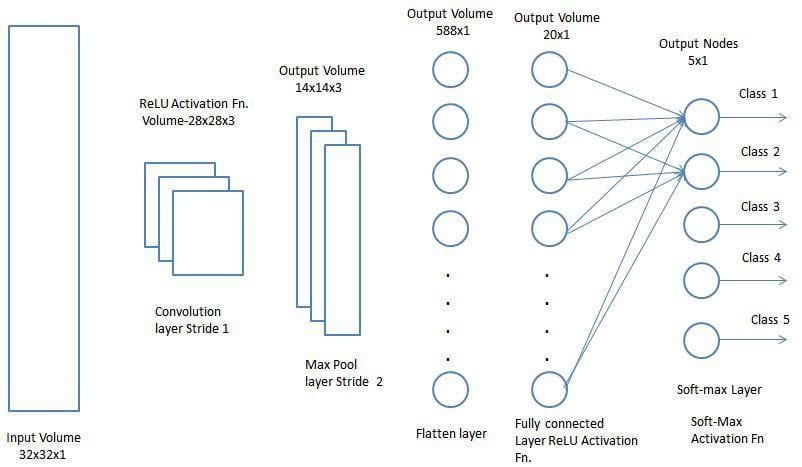
添加一个全连接层是一种(通常)廉价的学习方法,可以学习由卷积层输出表示的高级特征的非线性组合。全连接层在该空间中学习可能是非线性的函数。
现在,我们已将输入图像转换为适合我们的多层感知器的形式,我们将把图像展平为列向量。将展平的输出馈送到前馈神经网络中,并对每次训练的反向传播进行应用。在一系列时期内,模型能够区分图像中的占主导地位的和某些低级特征,并使用Softmax分类技术对它们进行分类。
有各种可用的CNN架构,它们一直是构建推动和将来将推动AI的算法的关键。以下是其中一些:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
Sumit Saha是一位数据科学家和机器学习工程师,目前致力于构建AI驱动的产品。他热衷于将AI应用于社会公益,特别是在医药和医疗领域。偶尔也会写一些技术博客。
原文。获得许可后转载。